
阿里通义发布第三代图像生成模型Qwen-Image-3.0,一手实测
阿里通义发布第三代图像生成模型Qwen-Image-3.0,一手实测今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。
来自主题: AI资讯
8200 点击 2026-07-21 22:20
 搜索
搜索
今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。
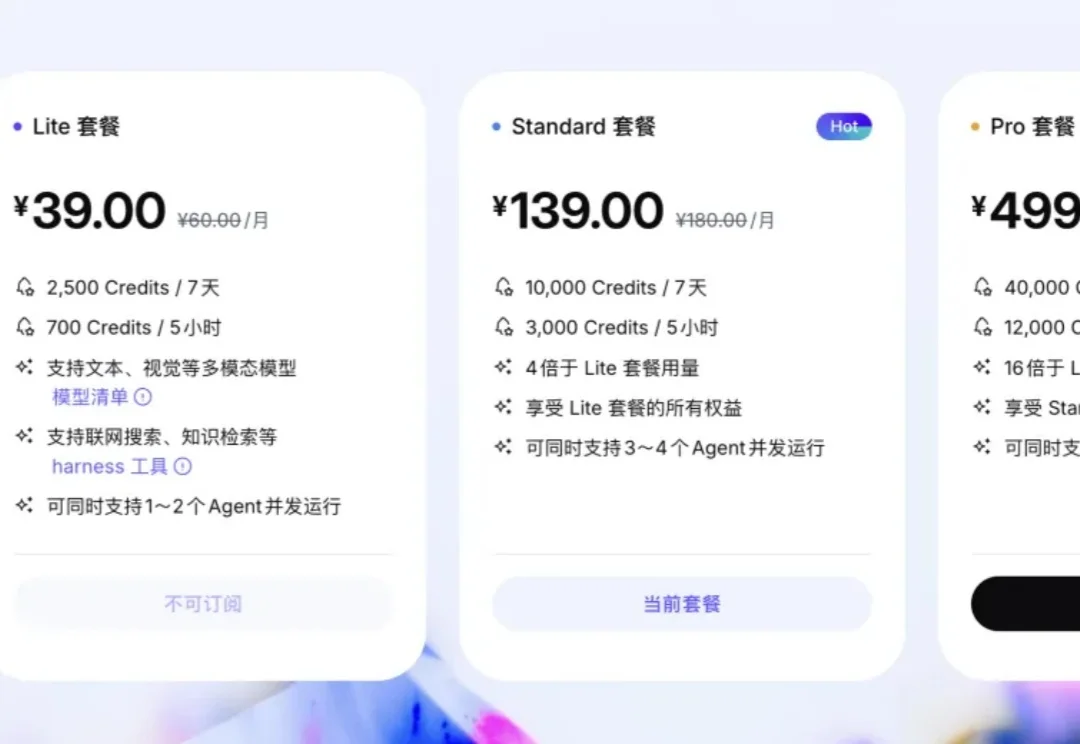
我刚刚 AGI Bar 小程序里建了一个共享钱包,并往里面充了 1 万块,未来 24h可点开领取

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个
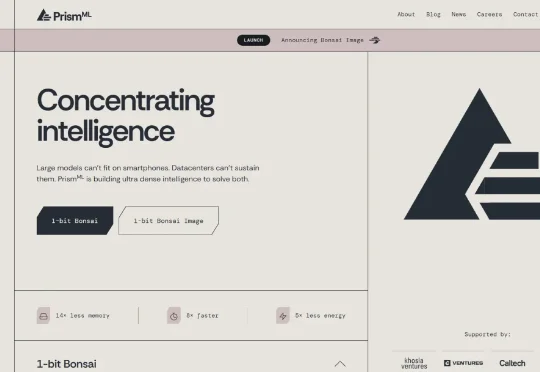
这家名为 PrismML 的初创公司表示,已将 Qwen 3.6 缩减至可在 iPhone 17 Pro 上运行,该模型拥有 270 亿参数(参数大致类似于大脑中的突触,能够帮助决定模型可处理数据的复杂性)。相比之下,大多数在手机上运行的模型一次仅有几十亿个参数处于活动状态。

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。

MrFlow(Multi-Resolution Flow Matching)就用这样的三阶段,在Qwen-Image等模型上把端到端生成时间从49.32s压到4.77s,实际加速10.35x。文章发布当日即登上Hugging Face Daily Papers;发布三天内,GitHub已收获200+stars;目前也已登上Hugging Face Trending Papers。

乐鑫喵伴 EchoEar EchoEar 喵伴 AI 机器人搭载的 ESP-Brookesia 框架实现全双工语音交互、多模态识别与智能体控制,构建更具沉浸感的人机交互体验。 EchoEar 套件以端
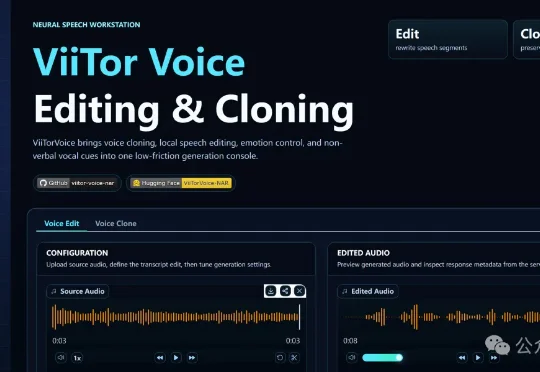
全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
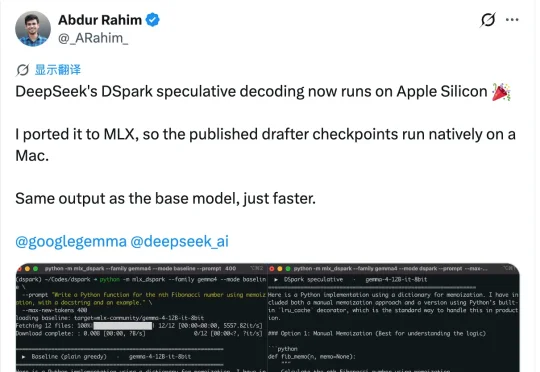
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。

7月2日,据大厂日爆消息,美团内部开始限制使用豆包大模型。消息称,美团向所有涉及到豆包大模型的业务部门下发通知,要求自查并规划迁移至LongCat、DeepSeek等模型,若无法迁移,需单独走审批流程。对此消息,截至发稿,美团暂无官方回应。据媒体报道,这并非美团首次收紧外部大模型的使用。今年4月,美团对内部大模型使用做出调整,不再推荐业务使用阿里云提供的Qwen模型。若业务仍需使用,需上报审批。