# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这几天,OCR这个词,绝对是整个AI圈最火的词。
因为DeepSeek-OCR,甚至让OCR这个赛道文艺复兴,又给直接带火了。
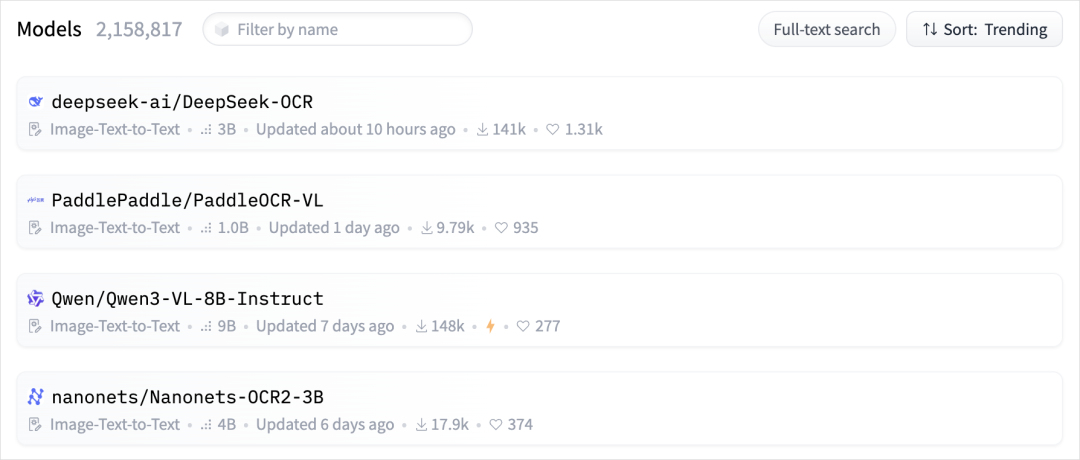
整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。
然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。


所以我也觉得,不如就来写一篇关于PaddleOCR-VL的内容吧。
非常坦诚的讲,百度家的东西,我写的一直都会非常谨慎。
但是这个PaddleOCR-VL,是我真的觉得值得一写的。
因为,确实很牛逼。

首先提一下,PaddleOCR这个项目本身,不是啥新东西,这是百度一直都在做的项目,很多年了,最早期甚至可以追溯到2020年,也是一直是开源的姿态。

后来他们就不断的迭代,整整5年时间,成了整个OCR领域最火的开源,现在也应该是现在Github上Star最高的OCR项目,有60K,基本属于断档领先。
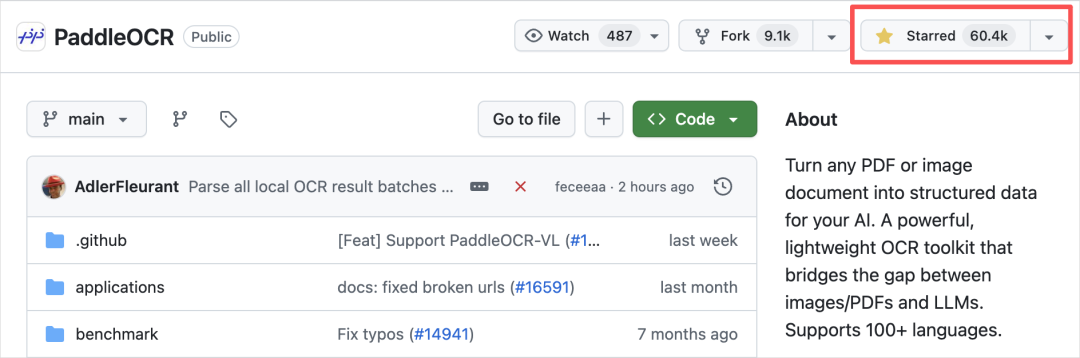
而PaddleOCR-VL模型,就是他们前几天开源了他们的PaddleOCR系列里最新的模型,这也是第一次,把大模型用在了整个OCR文档解析的最核心的位置。

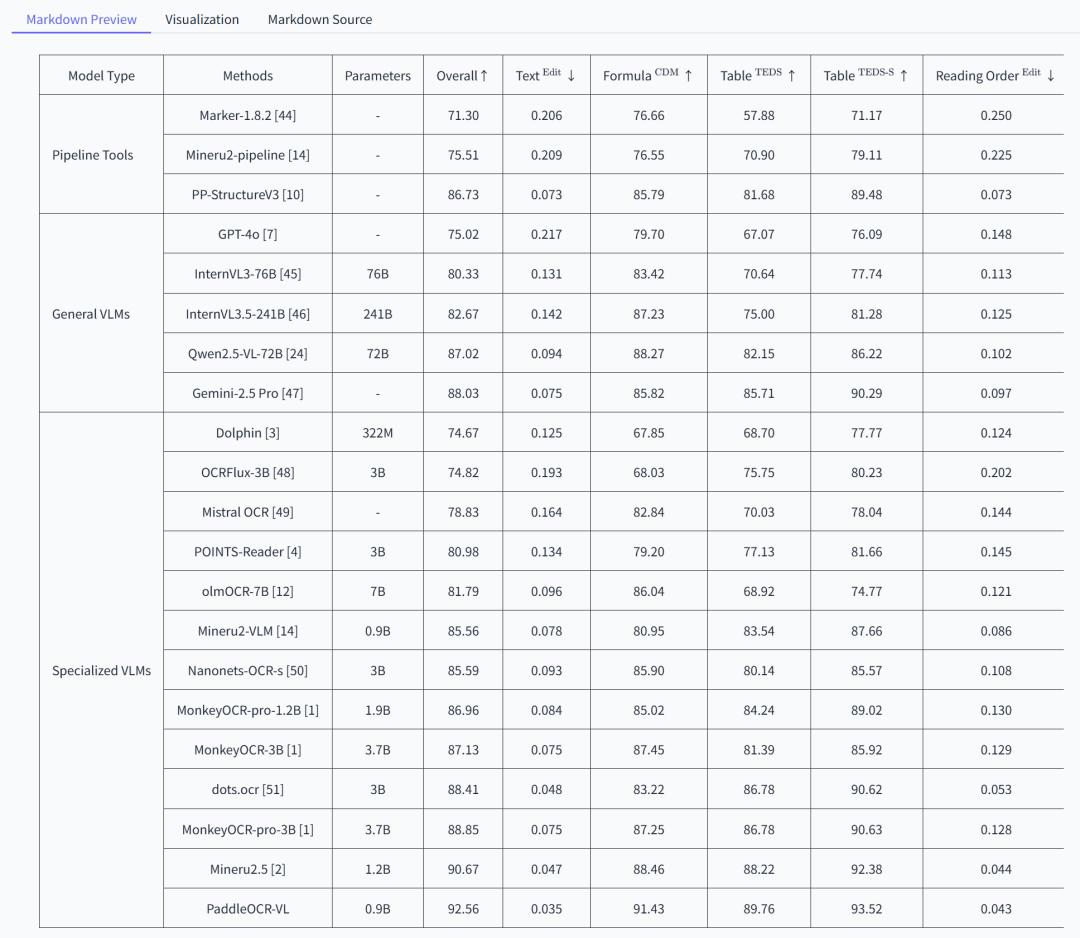
整个模型只有0.9B,但是几乎在OCR的评测集叫OmniDocBench v1.5的所有子项,都做到了SOTA。
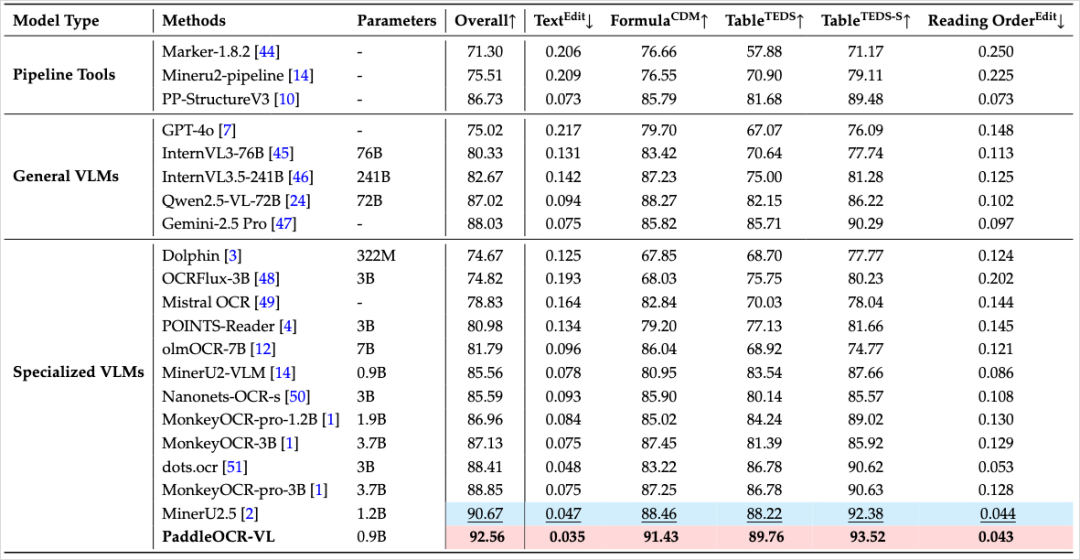
左边有三个类型,分别是传统的多阶段流水线系统、通用多模态大模型、专门为文档解析训练的视觉语言模型。
PaddleOCR-VL参数最小,效果最好,然后因为发的刚好早了三四天,所以表里没有DeepSeek-OCR的跑分,但是OmniDocBench v1.5的最新跑分昨天也出炉了,DeepSeek-OCR综合跑分是86.46,比PaddleOCR-VL的92.56还是低了大概6分,不过也能理解。
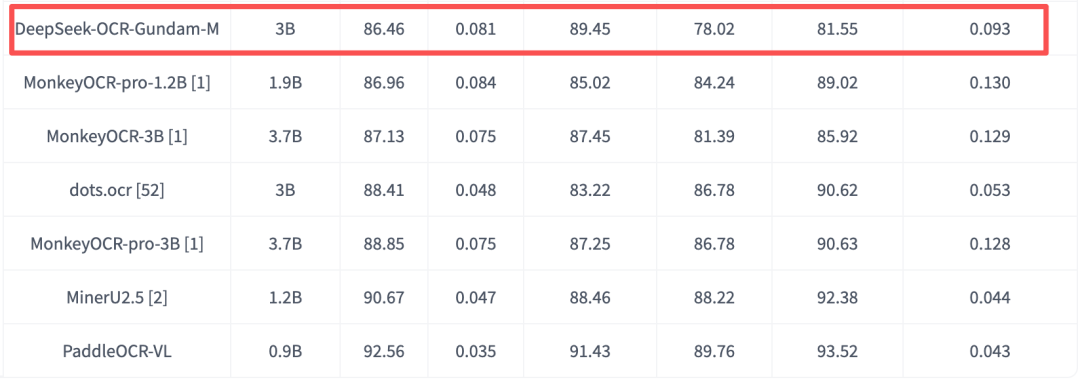
PaddleOCR-VL确实足够的猛,在垂直模型领域,把性价比做到了极致。你可能会有一点点好奇,为啥一个0.9B的模型,能比其他的大模型都要强。
除了确实专精这个领域之外,还有个非常有趣的架构,是我觉得单独可以说一下的。
也是长上下文和避免幻觉的一种非常有趣的解法。
很多的多模态大模型,是端到端的,他们干OCR的方式其实是非常低效的。
就是你把一整张A4纸扔给它,它需要一口气把这张图上所有的文字、表格、公式、图片、排版等等全都看懂,然后再一口气生成一个完美的Markdown,这个难度,其实也挺地狱级的。
毕竟模型需要同时理解:“哦,这块是个表,它在页面的左上角,这个表有3行5列,哦表头是这个,哦内容是那个,它旁边的这段文字是在解释这个表……哦哎卧槽我第一个事是要干啥来着。。。”
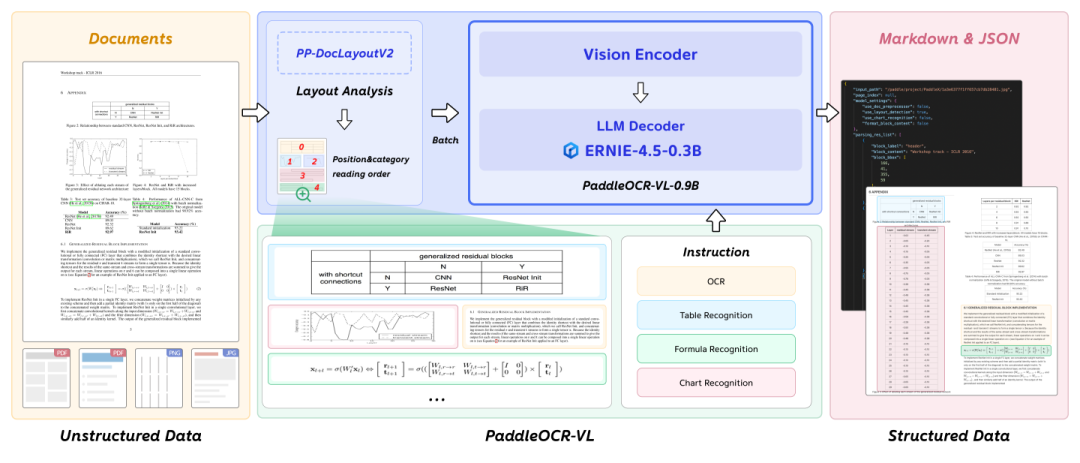
PaddleOCR-VL的做法就挺高效好玩的,它的架构,就两步:
第一步,先让专干布局分析的传统视觉模型上。这个玩意叫PP-DocLayoutV2,它干的活儿特纯粹,就是“框”。
它以极快的速度扫一眼整张图,然后把一些区域都框起来,然后告诉你:“报告老板,这里是标题,那里是正文,这块是个表,那块是公式。” 而且每个框的阅读顺序,也都是符合人类的阅读顺序的。
这个活儿,在CV领域已经很成熟了,根本不需要一个大模型来搞。
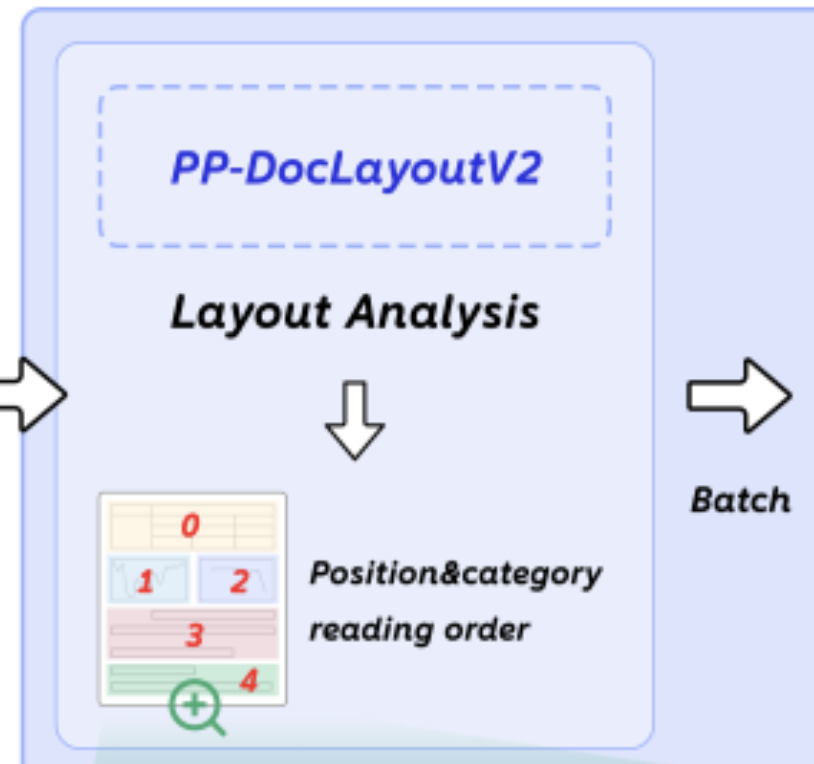
第二步,就是主力登场。这个主力,就是最核心的这个0.9B的PaddleOCR-VL模型。
它现在接到的任务,根本不是去看那张复杂的A4纸。它接到的是一堆被PP-DocLayoutV2裁好的小图片。
一个任务是:“这是一张200x500的小图,我(PP-DocLayoutV2)已经告诉你这是个表了,你(PaddleOCR-VL)给我把它转成Markdown。”
下一个任务是:“这是一张50x50的小图,我知道这是个公式,你给我转成LaTeX。”
然后循环往复,最后,又准又快。
所以这种做法,根本不需要复杂的几百B的大模型,直接上0.9B的模型,却能达到最完美的效果。
我之所以把这个点单独拿出来说,也是想表达我的一个观点:
在普通用户眼里,其实很多时候技术根本没有优劣,能解决用户的问题,就是最牛逼的技术。黑猫白猫,能抓到耗子的,就是好猫。
至少我认为,PaddleOCR-VL的做法,就非常的巧劲。
我也专门找了几类特别有代表性,处理起来比较头疼的图片来给大家看一下实测的效果。
首先肯定是扫描PDF,这种应该是重中之重,比如下面这张非常糊的扫描件截图,肉眼看起来也会有点吃力。

糊不拉几的,我眼睛看着都疼。
而把这个扔给PaddleOCR-VL,它处理起来很顺利,先是把需要识别的地方框了出来,并打上了阅读循序的序号。
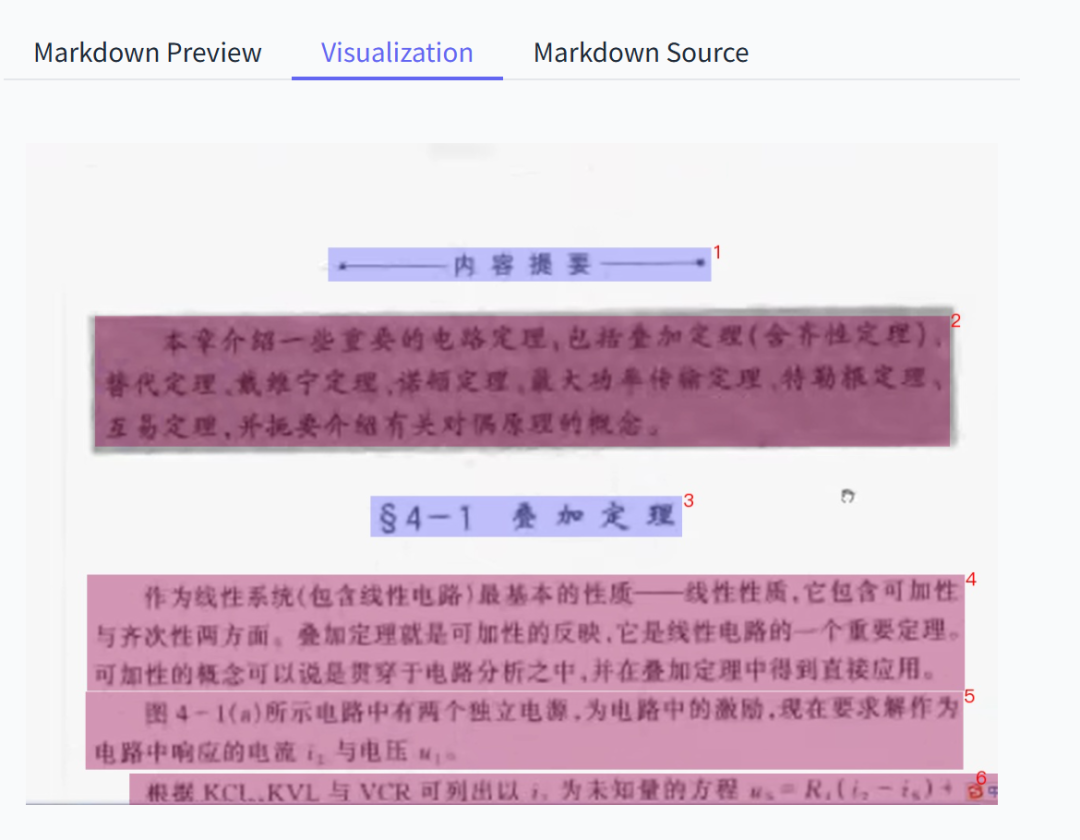
然后是第二步,分块识别出结果,效果很不错,公式也识别出来了。

我详细核对了2、3遍,发现确实一个字都没错。
最后的那个+号后面之所以没东西了,是因为我截图的时候,不小心让搜狗输入法的图标给挡住了。。。
我又找了一些手写笔记的照片去试,这玩意绝对是OCR领域的硬骨头。
不管是中文还是英文,只要字迹别太潦草到像天书一样,PaddleOCR-VL给出的识别结果准确率都还挺在线的。
对比很多工具碰到手写基本就歇菜的情况,这个已经很能打了。
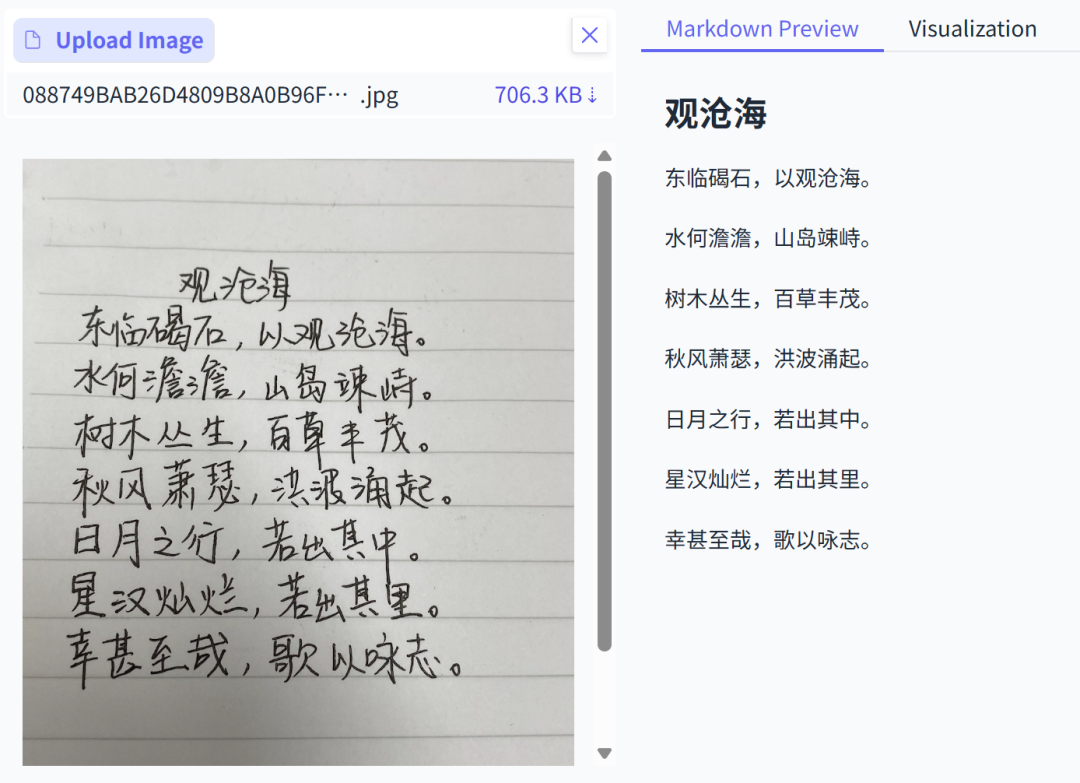
当然,前提是你的手写字得大致能看懂,如果是医生的那种字,我觉得神仙来了都没用。。。
然后是论文这种排版密集的。报纸那小字、多分栏、紧凑的布局,对布局分析和识别都是不小的挑战。
实测下来,PaddleOCR-VL对多栏的处理还比较稳定,阅读顺序也能捋顺,文字识别本身也没啥毛病,基本全对,总体效果挺好。

因为支持端到端的解析,所以能给你把一些图表啥的都给你还原回来。
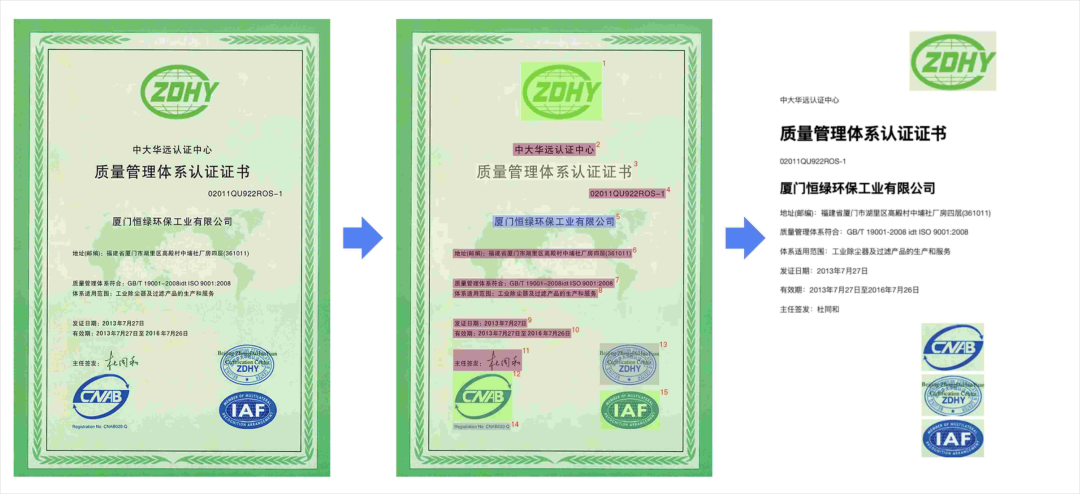
这个点非常的牛逼。
还有就是票据,像发票收据这些。格式虽然相对固定,但里面混着机打字、数字、手写补充、甚至盖章,挺复杂的。
PaddleOCR-VL在处理这类半结构化文档、抓取关键信息时表现还行,我自己跑了很多次,不能说百分百没差错,但在同类模型里,已经算非常靠谱的了。
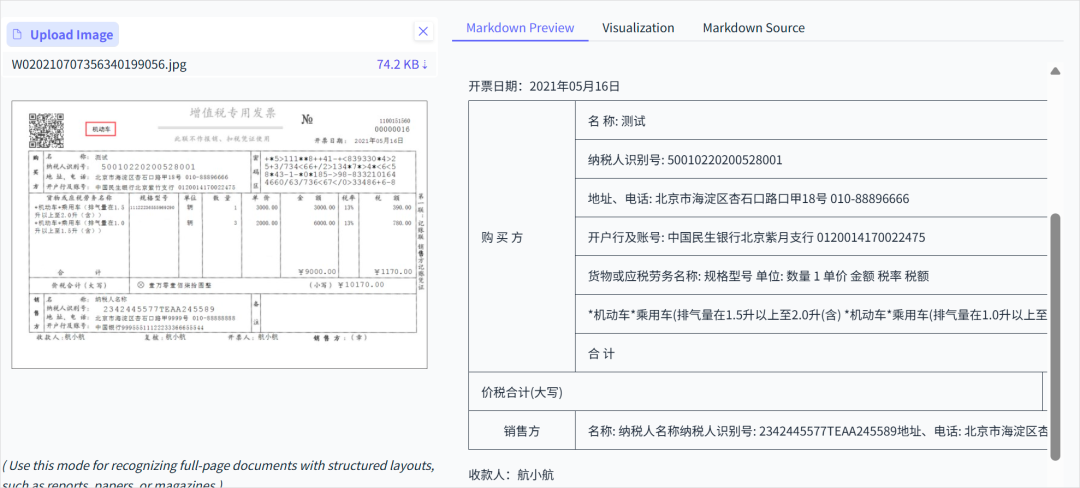
感觉这个已经完全可以替换我们现在多维表格上用的视觉大模型,接入到我们公司财务的多维表格系统里面了。。。
准确性强很多,真的能节省财务的不少时间。
还有那种大型表格,这就是重头戏了。
不管是论文里那种带合并单元格的复杂表,还是财报里密密麻麻的数字表,甚至是没啥框线的表,PaddleOCR-VL的表格结构识别能力是有一点让我惊讶的,不光能认出格子里面的字,还能把表格的行列关系比较好地还原出来,这对我们的一些自动化信息提取非常有帮助。
比如就是上文里面的那个跑分图。
识别提取出来之后,没有一丁点问题,这个是有点离谱的。
总的来说,这些实测跑下来,PaddleOCR-VL在处理这些复杂和刁钻的场景时,表现确实可圈可点。
而且实测确实会比DeepSeek-OCR准确更高,DeepSeek-OCR提取的时候总是会错一两个字,PaddleOCR-VL是一字不错,当然你不能把DeepSeek-OCR纯看成是一个纯OCR模型,毕竟意义还是不太一样。
我们自己其实有很多飞书多维表格的信息提取工作流,也已经在考虑换成PaddleOCR-VL了。
比如我们经常需要,批量上传一些各个平台的数据截图,然后提取里面的一些结构化信息。
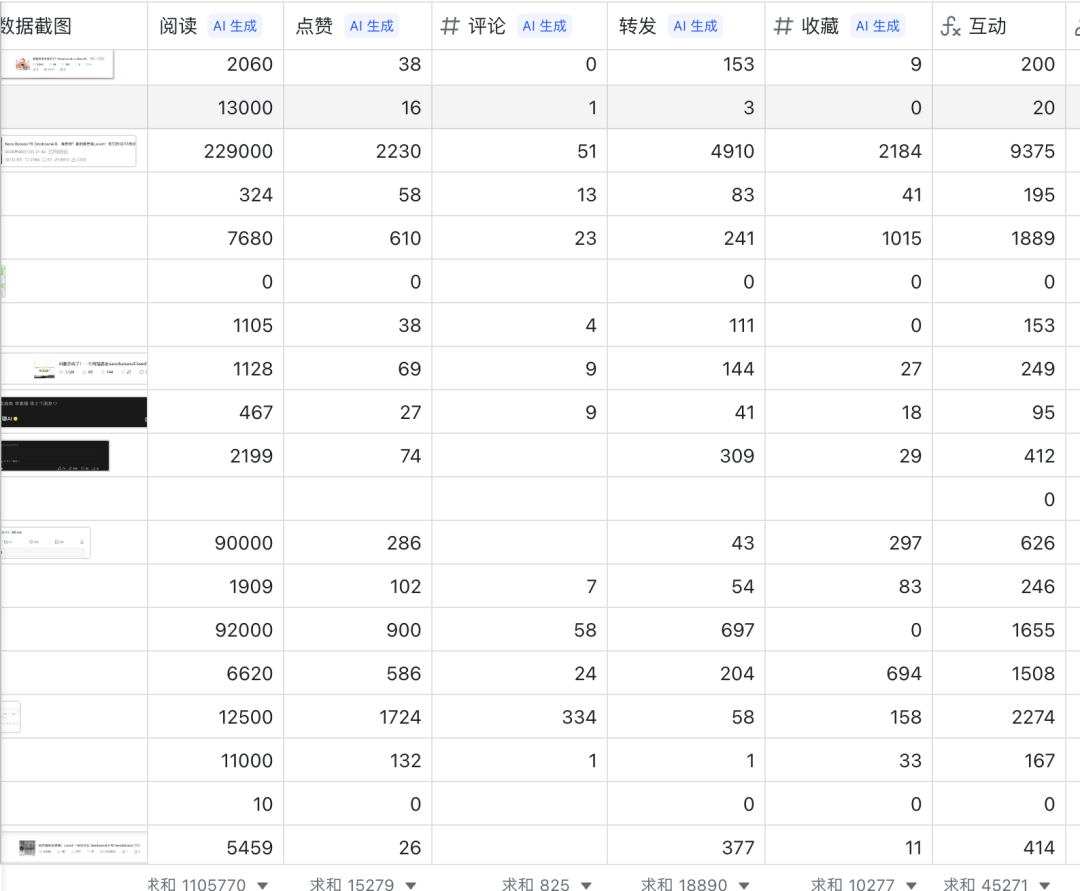
现在都是接了一些比较大的多模态大模型来做提取的,有一说一,从价格上来说,会比PaddleOCR-VL这种贵很多,而且有时候还会出错。
感觉把PaddleOCR-VL接进去,会是目前的最优解。
目前PaddleOCR-VL已经开源,网址在此:
https://github.com/PaddlePaddle/PaddleOCR
我本来想跟DeepSeek-OCR一样,给大家手搓一个Windows的本地整合包,让大家能开箱即用,结果因为不同于一些常规的大模型,折腾了一夜,干到凌晨4点多,两眼发黑,还是没做出来,这个只能说对不起大家,还是有点太菜了= =
所以现阶段,大家如果有自己部署能力的,可以自己根据PaddleOCR Github上的部署教程来部署到本地。
只是想用一下的,不想折腾部署的,可以去各大demo平台上用官方自己部署的体验版本。
飞桨:https://aistudio.baidu.com/application/detail/98365
魔搭:https://www.modelscope.cn/studios/PaddlePaddle/PaddleOCR-VL_Online_Demo
Hugging Face:https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
最后,还是想多说几句。
DeepSeek-OCR探索的上下文光学压缩确实非常新,也打开了大家对人类视觉感知的一些新的想象。
百度的PaddleOCR-VL,更是从实际出发,在一个细分领域达到了SOTA,成为了这个领域效果最好的模型。
高效、准确,也能实实在在地提升我们处理文档信息的效率。
两者都是非常优秀的工作,没有谁比谁强。
都是在自己领域。
最亮眼的仔。
文章来自于微信公众号 “数字生命卡兹克”,作者 “数字生命卡兹克”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
