全球OCR新王来自中国开源!GitHub狂揽73300+Star
全球OCR新王来自中国开源!GitHub狂揽73300+StarGitHub OCR项目之王刚刚历史性易主。
来自主题: AI技术研报
6736 点击 2026-03-31 10:29
 搜索
搜索
GitHub OCR项目之王刚刚历史性易主。
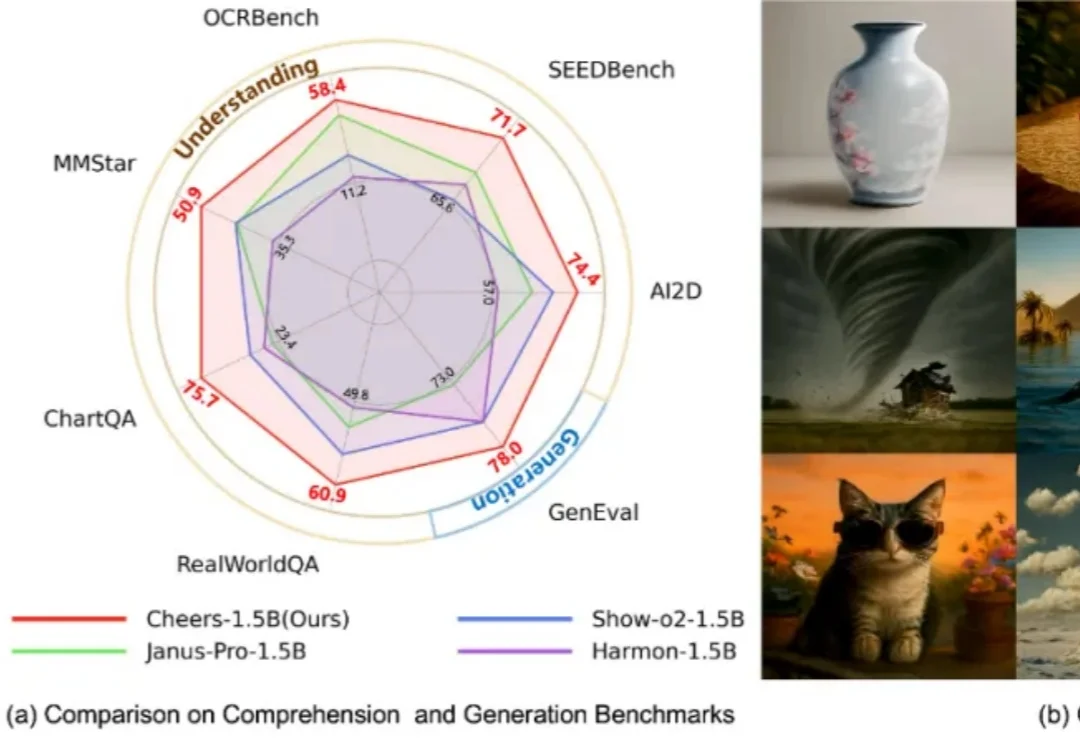
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
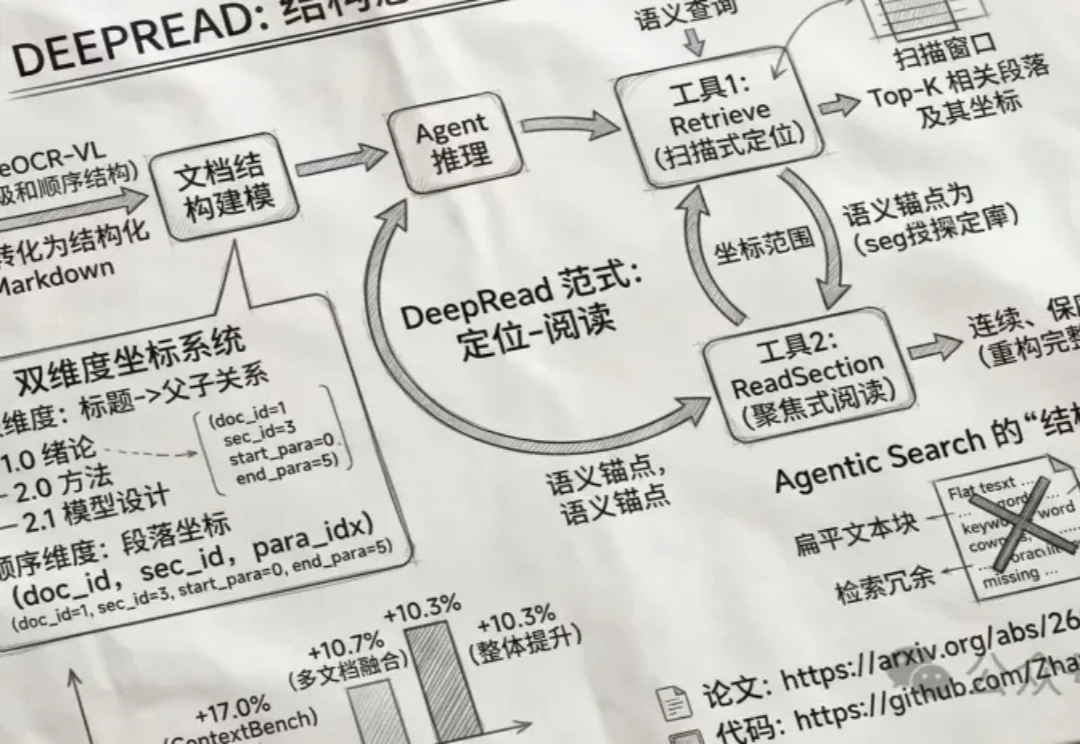
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。
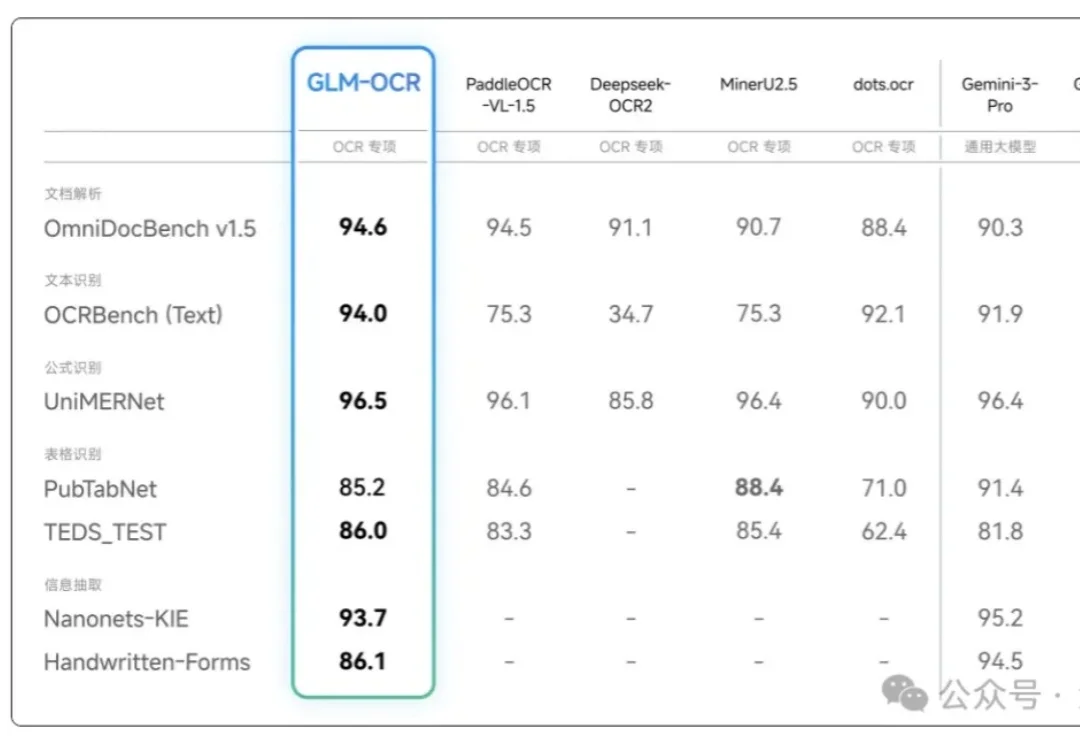
OCR模型究竟能干什么?干得怎么样?
没想到吧,Google DeepMind刚刚为Gemini 3 Flash推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被DeepSeek-OCR2给刺激到了?)

嘿!刚刚,DeepSeek 又更新了!这次是更新了十月份推出的 DeepSeek-OCR 模型。刚刚发布的 DeepSeek-OCR 2 通过引入 DeepEncoder V2 架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!

DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。

这一框架可用于集成额外文本、语音和视觉等多种模态。

随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……还得是吴恩达老师,火速来了新课程,帮你速通OCR。
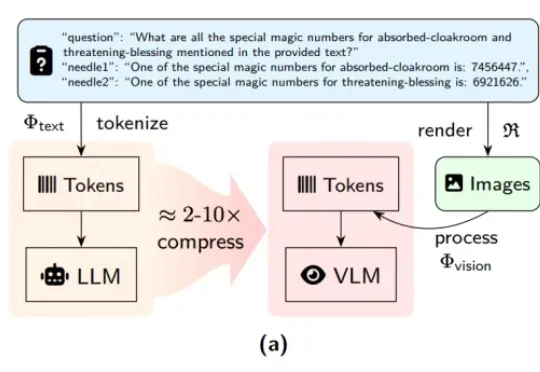
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。