# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RAG系统的搭建与优化是一项庞大且复杂的系统工程,通常需要兼顾测试制定、检索调优、模型调优等关键环节,繁琐的工作流程往往让人无从下手。
近日,针对以上痛点,清华大学THUNLP团队联合东北大学NEUIR、面壁智能及9#AISoft团队共同推出了UltraRAG框架,该框架革新了传统RAG系统的开发与配置方式,极大降低了学习成本和开发周期。
UltraRAG 不仅具备满足专业用户需求的“单反相机”级精细化配置能力,同时也提供类似“卡片机”的一键式便捷操作,让RAG系统的构建变得极简且高效。
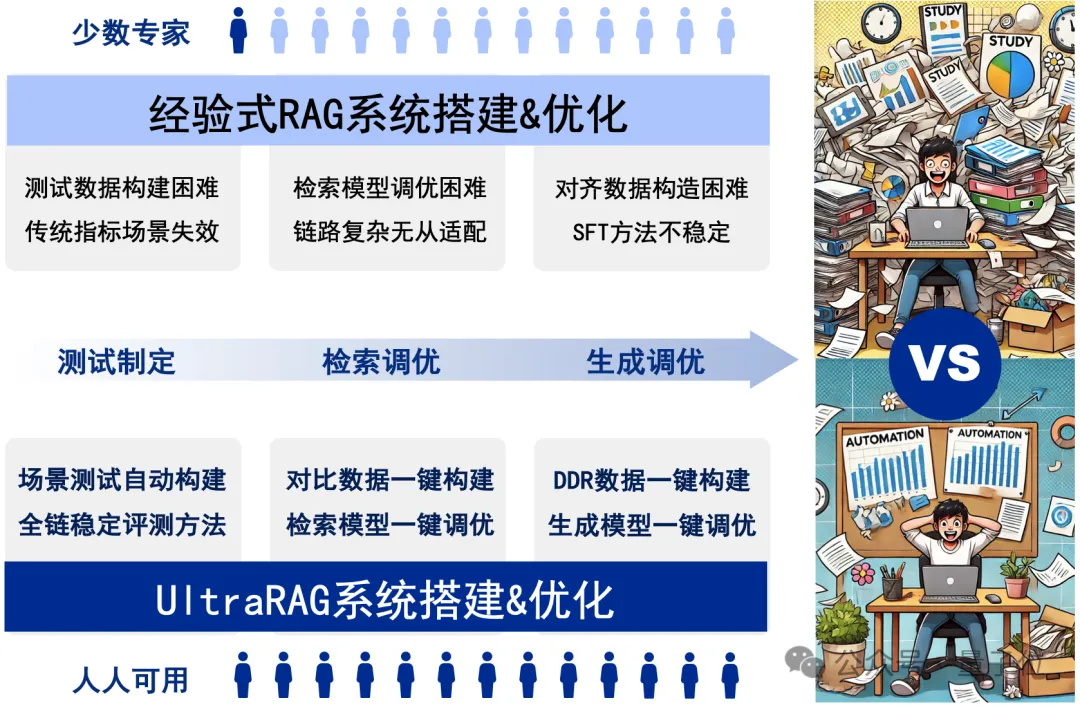
更重要的是,相比复杂配置的Llamaindex等传统RAG框架,UltraRAG更加关注将模型适配到用户提供的知识库,有效避免在“模型选型”的反复纠结。
同时,其模块化设计又能为科研需求快速赋能,帮助研究者在多种场景下自由组合、快速迭代。通过UltraRAG,用户可以轻松完成从数据到模型的全流程管理。
一同发布的还有一系列 RAG 技术全家桶,其中,RAG-DDR、VisRAG 刚刚被ICLR收录,MiniCPM-Embedding已有30余万次下载量。
GitHub地址可到文末领取。
UltraRAG以其极简的WebUI作为核心优势之一,即便是无编程经验的用户,也能轻松完成模型的构建、训练与评测。
无论是快速开展实验,还是进行个性化定制,UltraRAG均能提供直观且高效的支持。该框架集成了多种预设工作流,用户可根据具体需求灵活选择最优路径,无需编写繁琐代码,即可完成从数据处理到模型优化的全流程操作。
以下是操作演示:
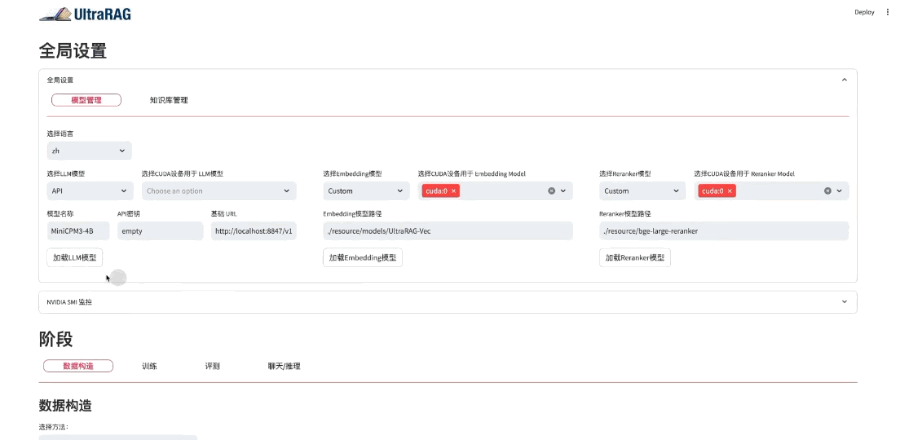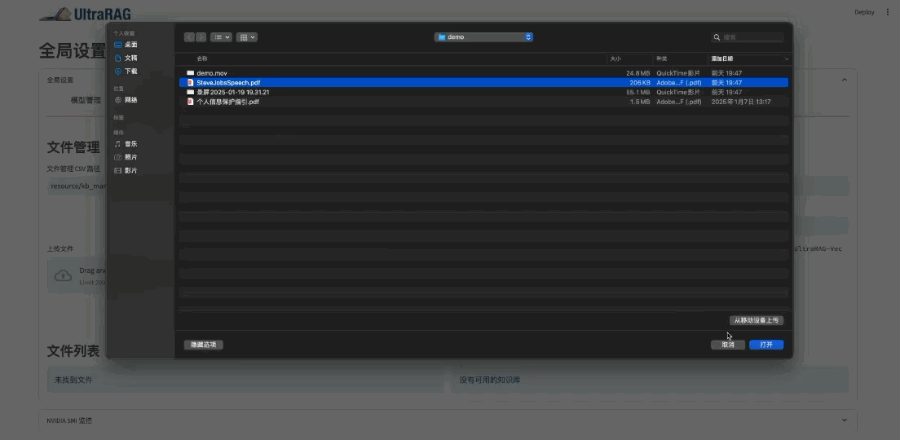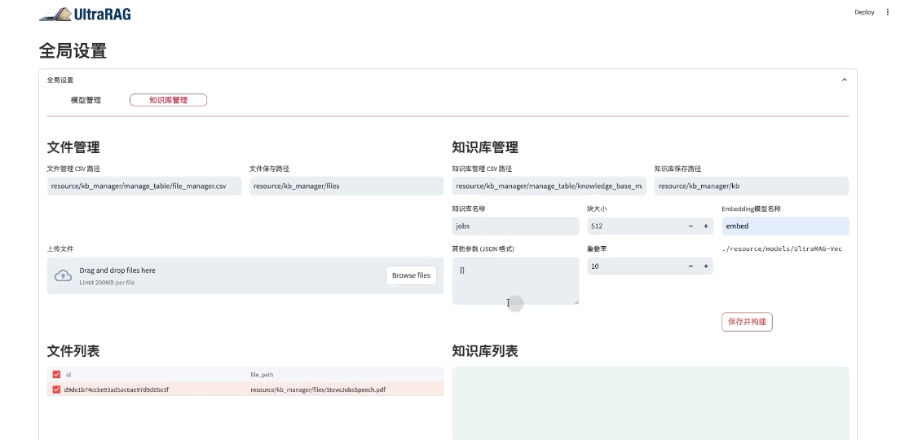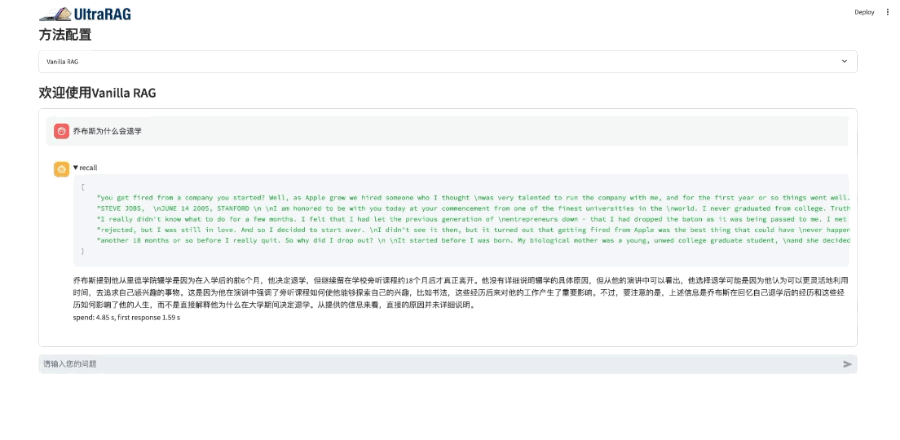
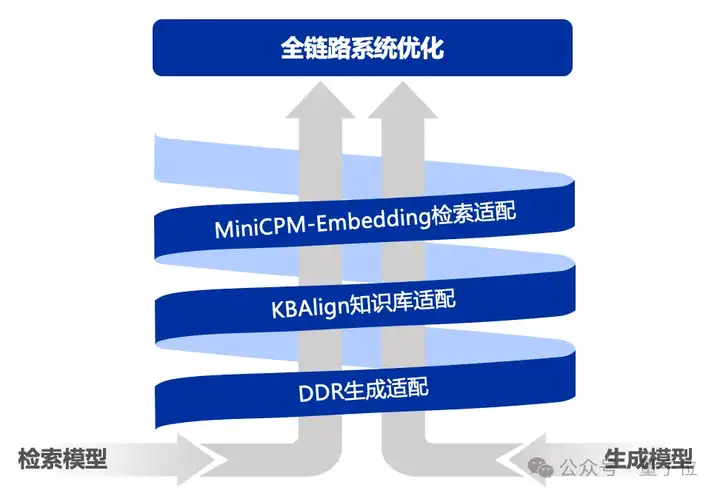
UltraRAG以自研的KBAlign、DDR等方法为核心,提供 “一键式”数据构建,结合检索与生成模型的多样化微调策略,助力性能全面优化。
在数据构造方面,UltraRAG覆盖从检索模型到生成模型的全流程数据构建方案,支持基于用户导入的知识库自动生成训练数据,显著提升场景问答的效果与适配效率。
在模型微调方面,UltraRAG提供了完备的训练脚本,支持Embedding模型训练及LLM的DPO/SFT微调,帮助用户基于数据构建更强大、更精准的模型。
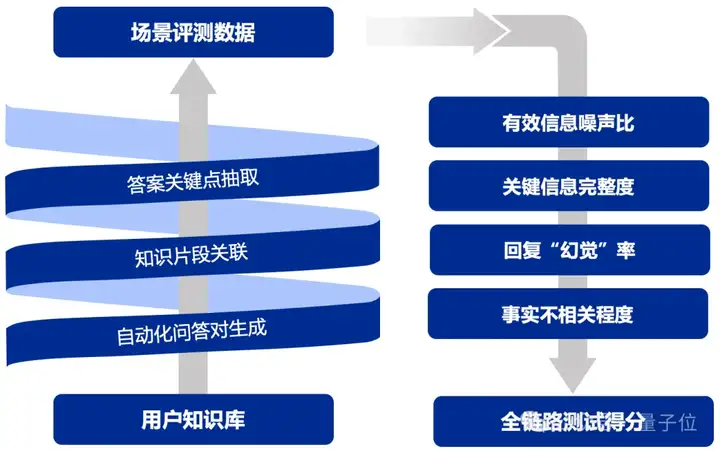
UltraRAG以自研的UltraRAG-Eval方法为核心,融合针对有效与关键信息的多阶段评估策略,显著提升模型评估的稳健性,覆盖从检索模型到生成模型的多维评估指标,支持从整体到各环节的全面评估,确保模型各项性能指标在实际应用中得到充分验证。
通过关键信息点锚定,UltraRAG有效增强评估的稳定性与可靠性,同时提供精准反馈,助力开发者持续优化模型与方法,进一步提升系统的稳健性与实用性。
UltraRAG内置THUNLP-RAG组自研方法及其他前沿RAG技术,支持整个模块化的持续探索与研发。UltraRAG不仅是一个技术框架,更是科研人员与开发者的得力助手,助力用户在多种任务场景中高效寻优。
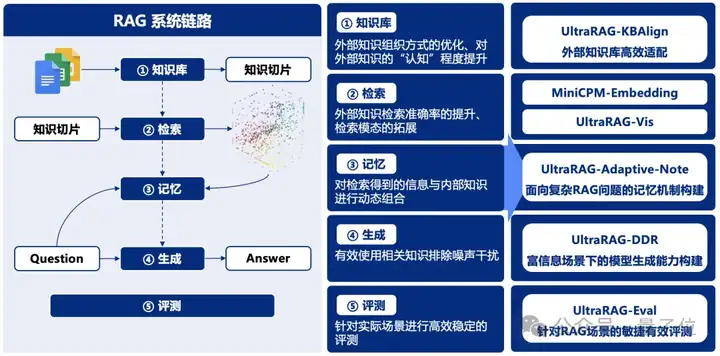
UltraRAG系列引入多项创新技术,优化了检索增强生成中的知识适配、任务适应和数据处理,提升了系统的智能性和高效性。
UUltraRAG各方法在国内外AI社区中享有一定的影响力和知名度,部分模型拥有30余万次下载量。
Github地址:
https://github.com/OpenBMB/UltraRAG
https://arxiv.org/abs/2410.13509
Li, Xinze, Mei, Sen, Liu, Zhenghao, Yan, Yukun, Wang, Shuo, Yu, Shi, Zeng, Zheni, Chen, Hao, Yu, Ge, Liu, Zhiyuan, et al. (2024). RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards. arXiv preprint arXiv:2410.13509.【ICLR 2025】
https://arxiv.org/abs/2410.10594
Yu, Shi, Tang, Chaoyue, Xu, Bokai, Cui, Junbo, Ran, Junhao, Yan, Yukun, Liu, Zhenghao, Wang, Shuo, Han, Xu, Liu, Zhiyuan, et al. (2024). Visrag: Vision-based Retrieval-Augmented Generation on Multi-Modality Documents. arXiv preprint arXiv:2410.10594. 【ICLR 2025】
https://arxiv.org/abs/2410.08821
Wang, Ruobing, Zha, Daren, Yu, Shi, Zhao, Qingfei, Chen, Yuxuan, Wang, Yixuan, Wang, Shuo, Yan, Yukun, Liu, Zhenghao, Han, Xu, et al. (2024). Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation. arXiv preprint arXiv:2410.08821.
https://arxiv.org/abs/2411.14790
Zeng, Zheni, Chen, Yuxuan, Yu, Shi, Yan, Yukun, Liu, Zhenghao, Wang, Shuo, Han, Xu, Liu, Zhiyuan, Sun, Maosong. (2024). KBAlign: Efficient Self Adaptation on Specific Knowledge Bases. arXiv preprint arXiv:2411.14790.
https://arxiv.org/abs/2408.01262
Zhu, K., Luo, Y., Xu, D., Wang, R., Yu, S., Wang, S., Yan, Y., Liu, Z., Han, X., Liu, Z., & others. (2024). Rageval: Scenario specific rag evaluation dataset generation framework. arXiv preprint arXiv:2408.01262.
文章来自微信公众号 “ 量子位 ”,作者 UltraRAG团队




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
