OpenAI发布新产品,亲自下场搅动千亿市场
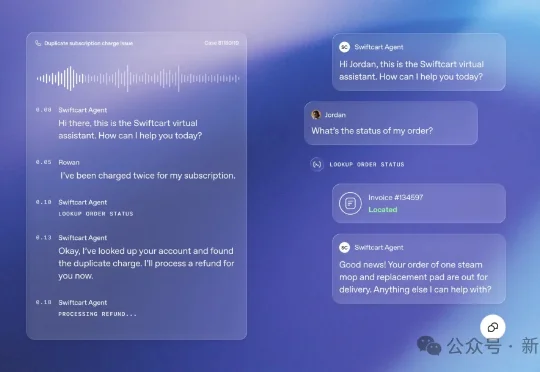
OpenAI发布新产品,亲自下场搅动千亿市场AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。
来自主题: AI资讯
10255 点击 2026-07-27 11:31
 搜索
搜索
AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。
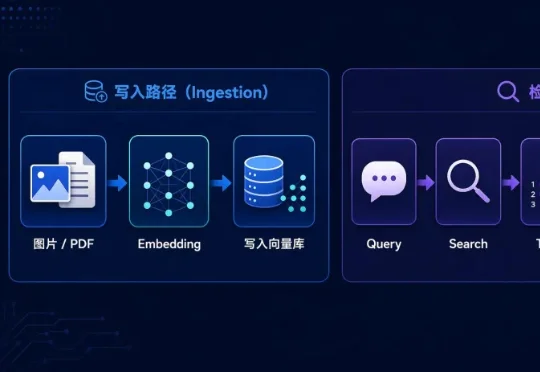
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。

还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。
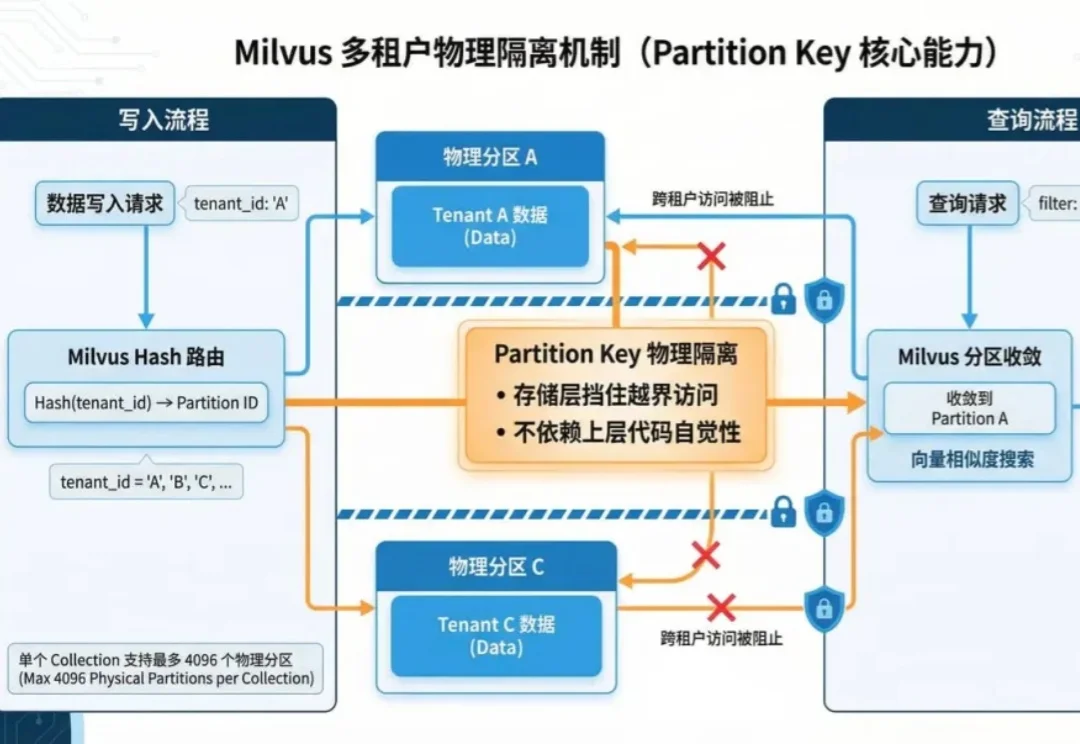
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

知识第一次,能像代码一样利滚利。前OpenA 创始团队成员、特斯拉前 AI 高级总监 Andrej Karpathy,提出一个狠招:别再用 RAG 检索你的知识库,让大模型把它「编译」成一座持续生长的活 Wiki。两个多月,他在GitHub屠出 5000+ star。

非手机业务目标400亿美元,“飞龙”进入数据中心,高通这次整了个大的。
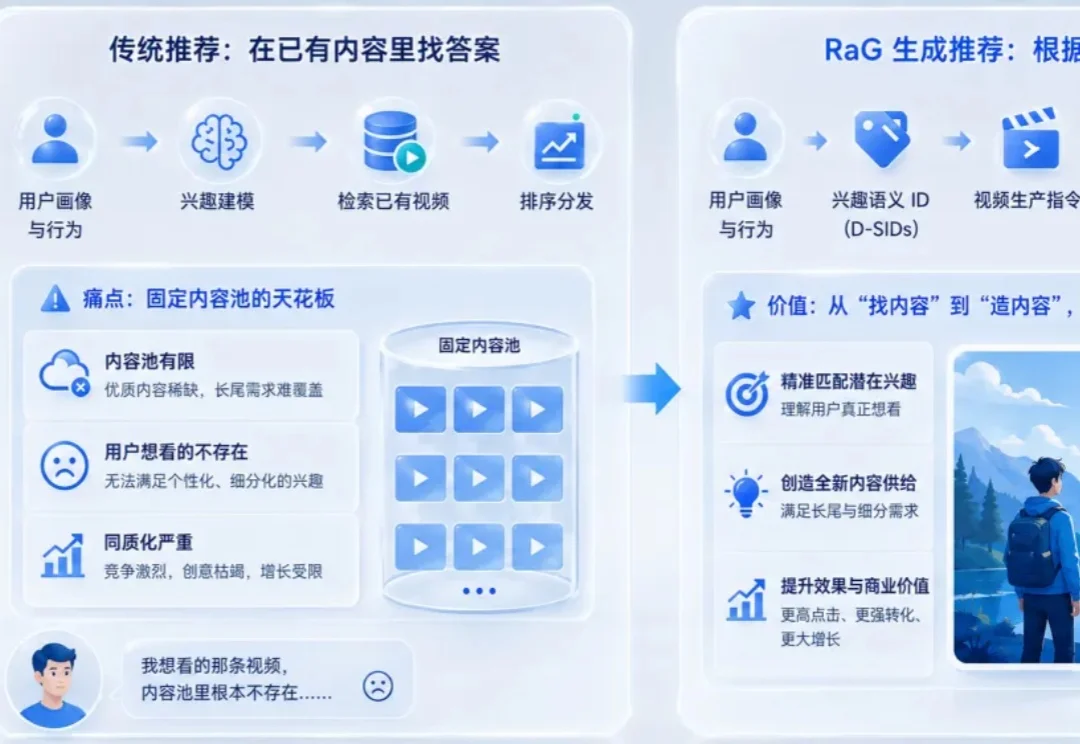
过去十年,推荐系统最核心的动作可以概括成一个字:找。
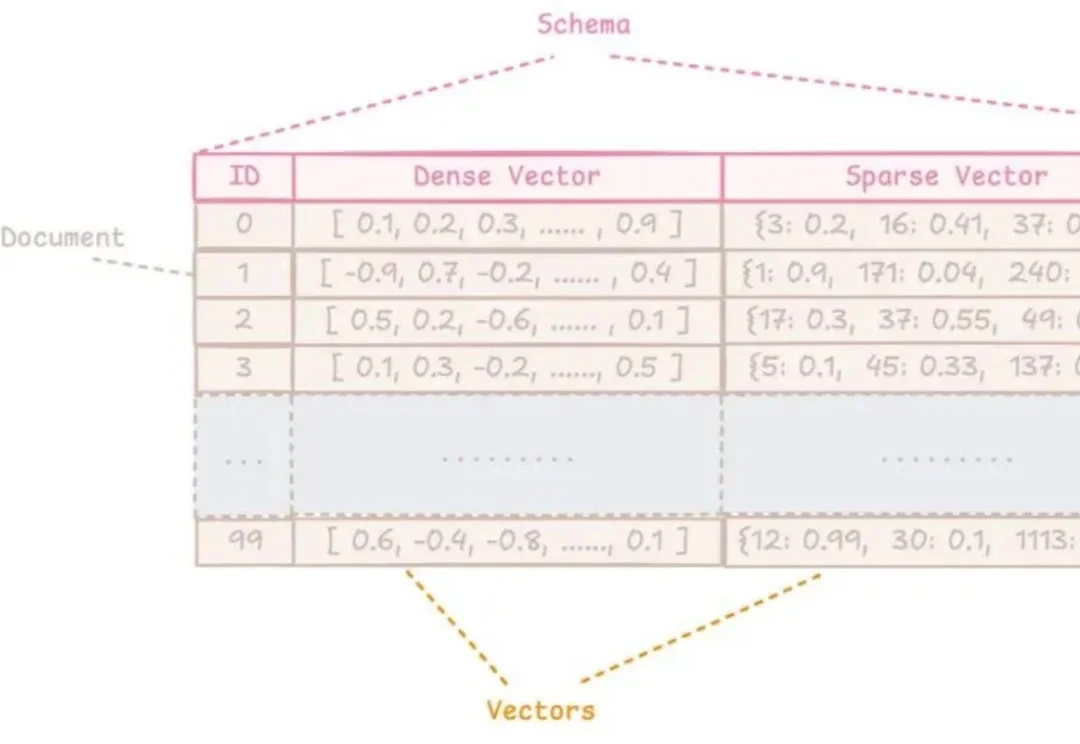
阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应
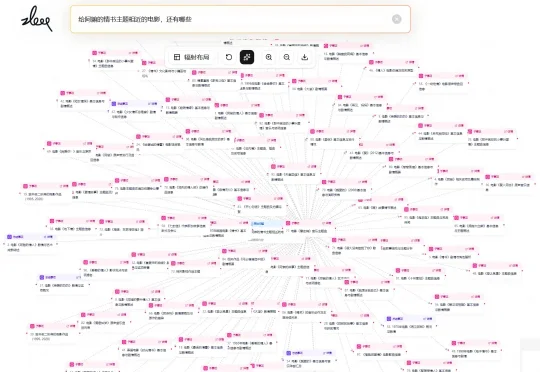
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。
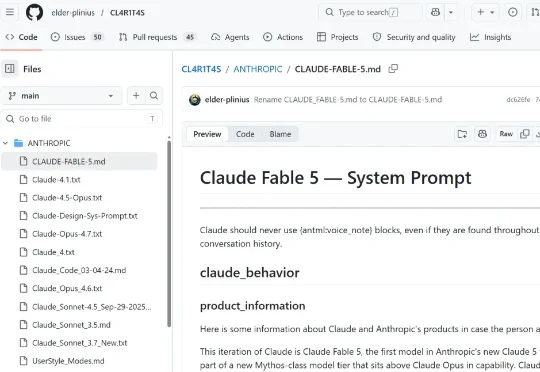
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。