# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
1.1 关键事件:当节日喜庆撞上AI安全黑天鹅

2025年春节,正当千万人沉浸在团圆的喜悦中,DeepSeek,这家被誉为“中国版OpenAI”的AI明星企业,却迎来了有史以来最严重的安全危机:
攻击规模:黑客发起了史无前例的3.2Tbps DDoS攻击,相当于每秒钟传输130部4K电影;
影响:DeepSeek官网瘫痪48小时,全球客户和合作伙伴受到影响,损失高达数千万美元;截止完稿时官方API 完整服务尚未恢复,境外用户仍然停止注册。
深层隐患:事后调查揭示,DDoS只是烟雾弹,黑客在API渗透和权重投毒中,精准注入了对抗样本,甚至(NSA)对DeepSeek的长期渗透痕迹。
1.2 这不仅仅是一次攻击,而是AI世界的“切尔诺贝利时刻”
这次事件并不是单纯的黑客攻击,而是AI安全史上的一个转折点,揭开了AI行业正在经历的暗流:
1. 安全的至暗时刻:AI模型的快速扩展正在成为黑客和国家级攻击者的新目标,单点突破可能带来毁灭性影响;
2. 地缘竞争浮出水面:从算力、数据到模型权重,AI已经成为全球竞争的核心资产,“新冷战”正在加速到来;
3. AI安全观念需要革新:传统的安全架构已无法覆盖大模型的多重风险,企业必须升级到系统级安全思维,让AI安全成为企业基因的一部分。
OWASP(Open Web Application Security Project)等国际安全组织连续多年将 XSS 列为高危威胁,可见其破坏力并未因时代变迁而消退。事实上,随着 AI 功能越来越越多元化、代码可视化与执行能力日渐增强,前端层面的风险反而变得更为突出。
近期第三方安全机构在chat.deepseek.com 发现*Reflected XSS(跨站脚本攻击)漏洞,再度敲响了这一警钟
2、漏洞简述:高风险的跨站脚本问题
漏洞类型:Reflected Cross-Site Scripting (XSS)
目标域名:chat.deepseek.com
危害等级:High(高危)
2.1 漏洞原理与场景
1. AI生成可执行代码:在“chat.deepseek.com”对话界面,用户可要求AI输出包含HTML/CSS/JS的完整代码;
2. 缺乏安全隔离:平台直接渲染并执行了该代码,而未进行严格输入/输出过滤与脚本沙箱;
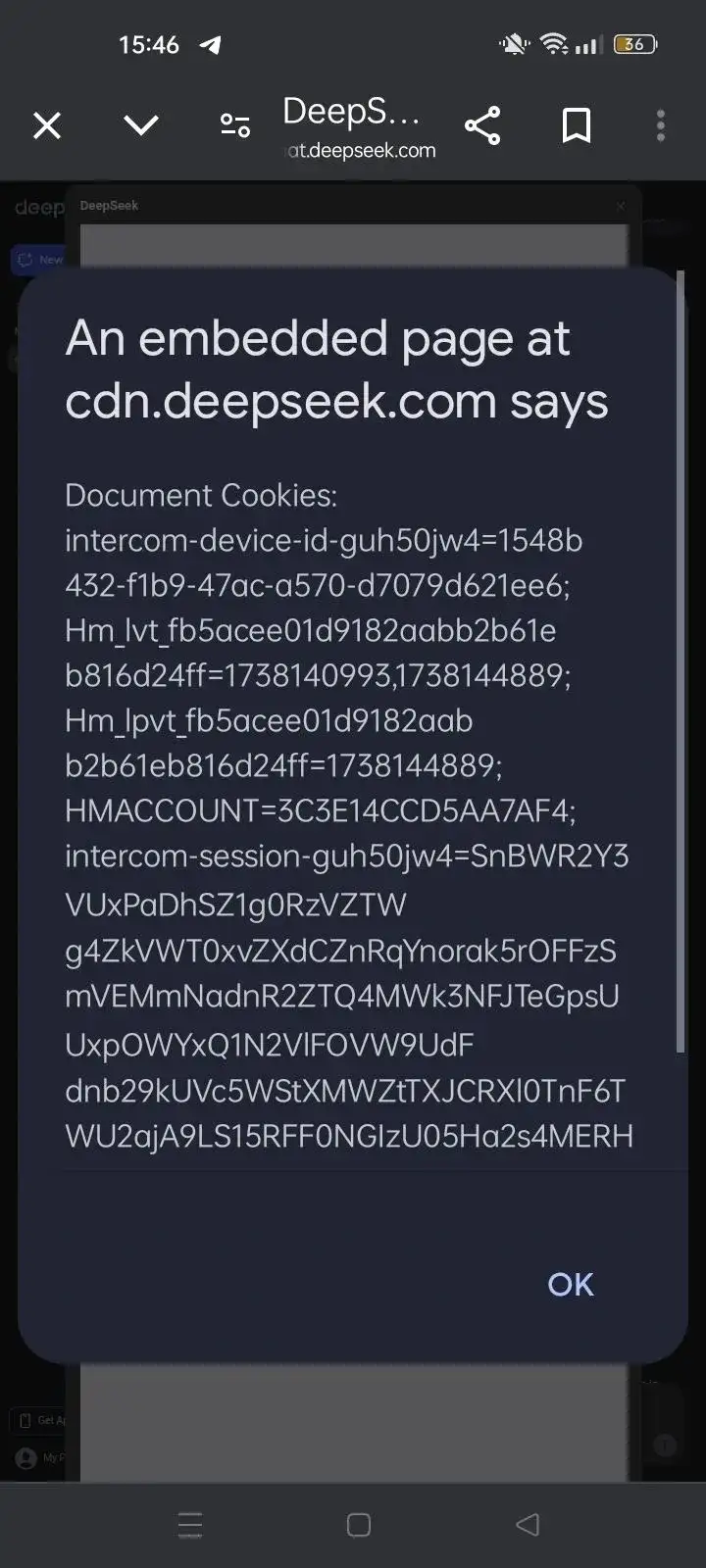
3. Cookie 暴露:攻击者可注入 alert(document.cookie) 等方法,获取受害用户Cookie,导致账户劫持或数据泄露。
在“AI驱动实时渲染”场景下,若没有CSP(Content Security Policy)、安全沙箱或HTML转义等多重防护策略,就无异于给潜在攻击者打开了“前门”。与 GPT-4、Anthropic Claude 等前沿模型提供的“代码解释器”接口类似,任何允许用户执行(或运行AI生成脚本)产品,都必须引入零信任和最小权限原则,否则极易沦为XSS温床。
如同我们在对各大AI平台展开白帽安全评估时常见的流程,具体PoC如下:
1. 在 chat.deepseek.com 让AI输出:
<html><body>
<button onclick="alert(document.cookie)">Click Me</button>
</body></html>
2. 点击“Run”后,平台渲染按钮;
3. 用户一旦点击“Click Me”,alert(document.cookie) 即弹出,证明Cookie可被读取;
4. 攻击者轻度修改此代码(如通过fetch或XMLHttpRequest发送数据)即可窃取用户会话信息。
行业洞察:这类“可执行脚本”功能并非只在 DeepSeek 出现,一旦被人利用,后果会相当严重。在顶级专家看来,这属于前端渲染安全的经典失误,也是“AI+前端集成”时代的普遍漏斗。
深度解读:Reflected XSS 究竟有何潜在杀伤力?
1. 会话劫持:一旦Cookie暴露,攻击者可在目标用户不知情的情况下冒用其身份;
2. 二次渗透:在获取Cookie后,利用同源策略可进一步访问其他子域,如 cdn.deepseek.com、api.deepseek.com 等;
3. 信任破坏:对于对话式AI平台而言,用户信任是核心资本,安全漏洞会直接动摇其行业地位与公众认同。
对照国际安全标准:
ISO/IEC 27034(应用安全)与NIST SP 800-53(风险管理框架)均强调,任何可执行用户内容的功能都需先行安全审查和沙箱隔离。
GDPR/CCPA合规考量:若用户信息因此被窃取,平台可能面临巨额罚款及法律诉讼。
修复建议
1 前端安全与沙箱机制
CSP(Content Security Policy):
1. 强制启用严格的 script-src 规则,禁止内联脚本或来自非白名单域的资源;
2. 搭配 nonce 或 sha256-hash 机制,对可信脚本进行标记,杜绝反射式注入。
隔离式运行:
1. 使用 iframe sandbox 属性,将AI生成的脚本置于与主域分离的环境;
2. 切断主Cookie或本地存储与该iframe的同源策略,实现逻辑隔离。
Google的“CSP Evaluator”等工具可辅助校验配置,OWASP 的 “AppSec Sandbox”实践有相当成熟的思路可借鉴。
2 服务端防护与输入验证
严格过滤:对用户输入或AI生成代码进行HTML实体化、转义敏感字符等(如 <script>、onerror= 等关键字);
安全审计:在服务器侧添加审计日志,监控可疑API调用或脚本插入频率,第一时间预警并阻断。
3 最小权限与分域部署
Cookie隔离:将关键Cookie置于更安全的子域(如 secure.deepseek.com),并标记 HttpOnly、Secure、SameSite 等属性;
分域策略:AI渲染模块独立成 render.deepseek.com 或类似域,严格限制其访问敏感资源的能力。
4 安全文化与运营策略
安全“红队”常态化:不定期组织内部或外部红队演练,通过模拟真实攻击发现盲点;
专业咨询与国际合作:邀请第三方专家(如 Defronix Cyber Security、Antrix Web Solution 等)定期协同审计,与学术界/安全社区联合研究漏洞攻防。
漏洞披露激励:设立“Bug Bounty”或“漏洞赏金”机制,让白帽黑客在第一时间提出发现,为企业争取修复窗口期。
下一步:从单点漏洞到系统级安全提升
Reflected XSS 在技术上相对传统,但在“AI + 前端可执行代码”的背景下,其破坏力却倍增,原因在于AI平台往往缩短了用户与核心脚本功能之间的距离。
安全专家的共识是:
1. 迅速补丁:根据上述沙箱、CSP、隔离等策略快速封堵现有缺口;
2. 系统级改造:将前端执行环境、模型输出校验、后端权限管理三者打通,形成闭环;
3. 定期审计:结合自动化测试与专业红队,持续跟踪新版本迭代,以免“旧病复发”或新功能带来新的漏洞。
重视漏洞,也是一种行业领先姿态
Reflected XSS 在一般网站中都被视为不容忽视的高危漏洞,更何况它出现在AI驱动的交互式平台中。通过这次曝光,行业应认识到:
AI 模型的安全防护不仅限于对抗样本与权重后门;面向用户交互的前端,也需“顶级严防”。
引入多层沙箱与国际最佳实践,不但能守护用户隐私,更能提升平台在全球市场的合规与信赖度。
缺陷暴露得越早,修复就越及时;把安全做深、做透,才能在长远竞争中保持领先,而非只在创新功能上“刷快感”。

以下内容参考并整合了 Wiz Research 的研究报告,由我们团队基于专业安全认知进行二次阐述。
事件概览:从“无身份验证”到“全面控制”
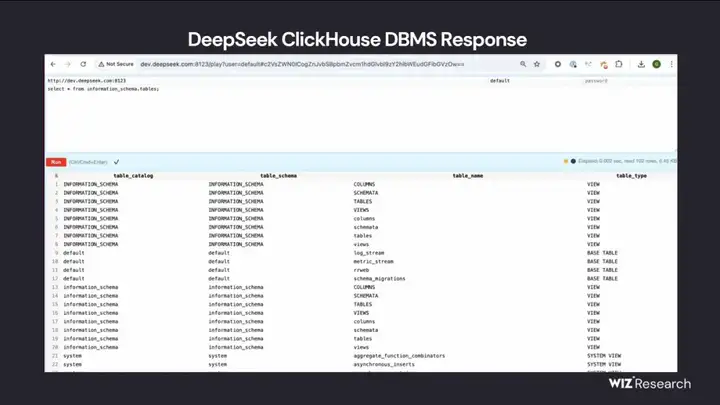
不久前,安全研究团队 Wiz Research 发现 DeepSeek 有两个面向公网、无需身份认证即可访问的 ClickHouse 数据库端口(8123 和 9000)。它们位于:
oauth2callback.deepseek.com:9000 / 8123
dev.deepseek.com:9000 / 8123
在常规端口探测和子域名收集中,研究人员注意到这些不常见的开放端口,很快便发现了完全敞开的数据库接口。而最让人震惊的是:一旦连接上该数据库,就能执行任意 SQL 查询,甚至可读写、删除、导出、覆盖任意内部数据。
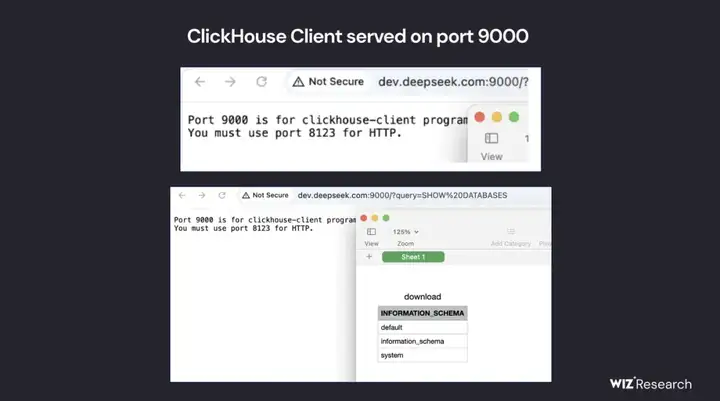
数据暴露的核心内容
过百万行日志(log_stream)
包含 DeepSeek 内部的接口调用、服务端输出、运行轨迹等;
可见到明文聊天记录、API Key、后台路径、账号信息等高度敏感内容。
潜在权限升级
研究报告提到,利用 ClickHouse 本身的查询机制,攻击者甚至可能读取服务器本地文件;
如果与 DeepSeek 内部网络或其他服务联动,可能获得更深层次的权限。
侦察过程
Wiz Research 先对 DeepSeek 的主域和子域做了基础枚举,最初只看到一些常规的 Web 服务(聊天界面、状态页、API 文档等),并未发现明显高风险端点。
随后,他们逐步扩大侦察范围,扫描常规 80/443 之外的端口,结果出现了 8123、9000 等“意外发现”。根据经验推测,这些端口常用于 ClickHouse、InfluxDB 等后端数据服务。一旦它们完全暴露,几乎就是“随意进入”状态。
ClickHouse 特性
Columnar DB for Big Data:ClickHouse 是开源列式数据库,通常用于实时日志分析、大规模数据存储等场景;
HTTP / Web UI:它内置了一个 /play 或者 Web UI 功能,允许直接在浏览器中执行 SQL,若无任何身份验证,就意味着完全对外裸奔。
深层影响:聊天记录与内部数据的“开放大门”
Wiz Research 提到,该数据库里有超过一百万条日志条目,涉及:
Chat History:用户与 DeepSeek 平台之间的对话内容,可能包含个人隐私、企业机密、敏感业务信息;
API Keys & Secret:这些密钥可能用来访问 DeepSeek 的内部服务或合作方服务;
后端元数据:包含目录结构、服务名称、调度进程、甚至潜在的源码片段或系统调用痕迹。
换句话说,如果黑客掌握了这些信息,不仅能窃取用户对话与企业机密,还可能进一步深入 DeepSeek 内网,从“读权限”扩大到“写权限”,甚至进行供应链攻击(如往日志管线上注入恶意数据、进入其他服务节点等)。
及时响应与修复
Wiz Research 发现暴露后,第一时间通过“负责任披露”机制告知了 DeepSeek;
DeepSeek 随即修复了暴露端口并进行安全加固,目前该数据库已不再对外开放。
行业启示:AI 的“新瓶装旧酒”风险
传统漏洞在 AI 环境下依旧致命
许多企业聚焦在对抗样本、模型后门等“新型”AI威胁,却常常忽略最基本的网络与数据库安全;
事实证明,最基础的“公开暴露”仍是最大杀手,一步不慎就可能让核心数据全部失守。
数据越多,后果越严重
AI 公司往往收集和处理海量敏感信息:用户输入的聊天、企业业务数据、账号密钥……一旦管理疏忽,泄露规模和影响远超传统企业。
攻防要协同:安全团队与 AI 工程师并肩作战
AI 团队专注模型开发,但对数据库、运维、访问控制等传统安全环节可能不够敏感;
安全团队必须全流程介入,从架构设计到上线监控,对每个端点、端口进行持续审计。
别让基础配置“掉链子”
这起数据库暴露事件再次提醒我们(虽然及时通报并修复了),AI 的强大能力背后,仍建立在基础设施与传统安全之上。
在讨论大模型对抗、隐私保护、算法偏见等先进议题时,也别忘了最基本的安全防线:口令、端口、访问策略。
对于任何一家 AI 公司,安全合规不能只着眼于前沿技术,还要回归“地基”本身——就像房子盖得再高,也要先打牢地基,否则狂风骤雨一来,可能瞬间坍塌。
DeepSeek虽然在这次攻击中暴露出安全短板(目前已经修复了多项),但它在技术上的突破依然是值得研究的。
技术破局:在GPU荒漠中造出“绿洲”
面对全球算力短缺和英伟达GPU限制,DeepSeek选择了一条与OpenAI、Anthropic截然不同的道路:
MoE(Mixture of Experts)架构:让计算更高效
将超大模型拆分成128个“专家模块”,推理时仅动态调用其中12个,如同“只启动汽车所需的发动机气缸”,大幅降低算力和能耗;
安全风险:分布式模块化架构可能成为攻击目标,黑客可通过投毒控制特定专家,从内部“腐蚀”模型。
量化技术:FP8 vs. FP16,极限压缩计算成本
采用FP8精度量化,在华为昇腾910B上实现98.7%的精度保留,内存占用降低60%,比FP16更省电;
安全挑战:量化模型在对抗样本攻击下的鲁棒性仍未完全研究透彻,是否会让模型更易被欺骗仍是未知数。
SFT蒸馏:“师徒模式”让小模型变强
通过RLHF(人类反馈强化学习) GRPO(组相对策略优化)生成高质量数据,微调7B小模型,使其达到13B大模型95%的性能;
值得一提:
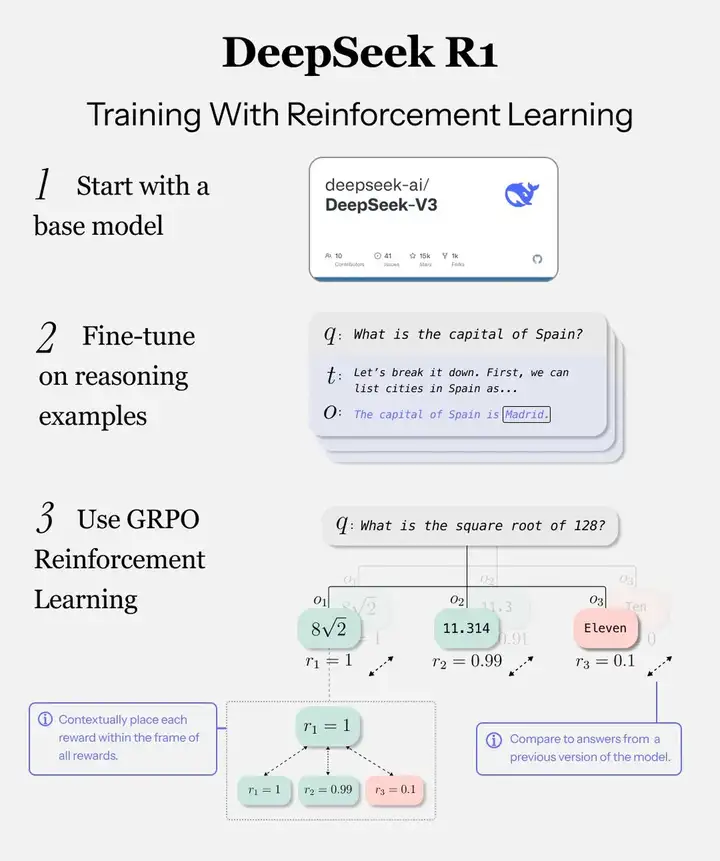
大多数 LLM 都通过几个不同的步骤进行训练。首先,基础模型是从大量人类书面文本(如 Internet)中预训练的。然后,模型可能会针对其目的进行专门微调(例如成为助手)。
一些模型将强化学习 (RL) 作为最后一步,这通常涉及通过生成输出进行训练,并让单独的模型评估它是否是提示的正确答案,从而进一步专业化模型。
DeepSeek R1 的做法不同。
DeepSeek R1 不是使用庞大且昂贵的神经奖励模型来评估答案,而是从 GRPO(组相对策略优化)进行训练。
以下是它的工作原理:
采样:该模型使用当前策略为每个查询提示生成多个输出。即对于每个 qqq,生成多个输出 {o1,o2,…,oG},并使用奖励模型计算它们的奖励 {r1,r2,…,rG}。
奖励评分:每个输出都使用奖励函数进行评分。这些分数可以是基于规则的(例如,格式或准确性)或基于结果的(例如,数学或编码的正确性),DeepSeek R1-zero即采用基于最终规则奖励+格式遵循奖励。
优势计算:来自该组的平均奖励作为基准。每个输出的相对优势是基于该基准计算的,奖励在组内进行归一化,提供相对优势 A1, A2,..., AG,而无需传统的价值模型。
政策优化:利用计算出的优势,策略自我更新以最大化性能。KL 散度项直接纳入损失函数,确保模型在探索与稳定性之间取得平衡。
安全隐忧:微调过程容易成为攻击切入点,黑客可以在SFT阶段植入数据污染,改变模型行为。


表格说明
1.“$6M”的数字本质上指的是DeepSeek官方在论文或公开采访中披露的一次关键训练阶段的“GPU租用与电费”成本,大量前期研发与资本支出被排除在外。SemiAnalysis 最新报告指出,DeepSeek 整体CapEx投入大约 $1.3B。
2.GPT–o1 的具体算力投入、CapEx与每步训练/推理成本缺乏权威公开资料,因此只能使用外界估计或片段信息。
3.MLA(Multi-Head Latent Attention)**是 DeepSeek 近来的主要创新点之一,据称通过减少KV Cache使用来提高长上下文推理效率,并有效降低推理成本。
先前在公众场合流传的 “DeepSeek 只花了 600 万美元训练出 R1” 这一说法,忽略了庞大的基础设施(CapEx)和持续研发成本。
从最新分析看,DeepSeek 的真实支出(包括硬件采买、数据中心运营、研发等)可达10 亿美元量级;所谓“$6M 训练费”只是冰山一角。
就性能和成本对比而言,DeepSeek R1 在多步推理、推理价格/性能比和长文本处理上颇具竞争力;GPT–o1 则在规模与通用性方面胜出。
未来走向可能取决于出口管制、硬件可获得性以及 DeepSeek 的快速迭代能力。若 DeepSeek 持续在工程和架构上进行精益化优化,其单位推理成本还有进一步下降的空间。
备注:此表格来自于开源信息分析,不作为最终成本依据,真实的成本属于各方商业机密。
DeepSeek在算力受限情况下,依靠架构优化弯道超车,但安全投入严重不足,像是在狂飙的AI赛道上拼命加速,却忘了安装安全气囊。
黑客如何击穿DeepSeek的安全底线,攻击链剖析:从DDoS到模型投毒
API接口滥用
黑客利用DeepSeek未设限的 /v1/complete 端点,批量注入带有10%对抗样本的恶意请求,使模型“误读”敏感指令;API端口是大模型的“咽喉要道”,安全验证缺失会成为致命漏洞。
模型权重篡改
通过梯度反转攻击,在72小时的微调过程中植入隐蔽后门,使特定政治敏感词的生成错误率提升 47%;微调过程需要在零信任环境下进行,必须采用模型权重签名和完整性验证。数据泄露:1.2TB训练数据被黑客复原黑客利用模型反演技术,成功从推理API恢复训练数据,甚至包含30万条xx记录;深度学习模型并非“黑箱”,数据隐私风险比想象中更严重,企业需要更高级的数据防御策略。
AI安全能力差距:D vs. Anthropic
以下表格根据开源信息分析
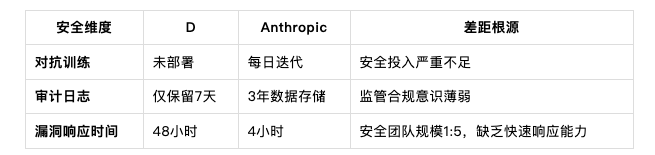
人家提的问题其实很尖锐,但可能是事实。
行业洞察:Anthropic和OpenAI等公司把安全视为“核武器级”任务,而DeepSeek还停留在“实验室思维”,也许这就是被打穿的根本原因。
安全不能是补丁,而是AI系统的内核。目前大部分企业的AI安全防护是事后响应,而不是事前防御。AI需要像金融系统一样,从根本上设计安全机制,而不是“出了事再补救”。AI安全需要行业共建,而不是单打独斗,目前AI企业各自为战,攻击者却在全球范围内协作。行业需要建立AI安全联盟,共享攻击情报,联合研发防御机制,而不是让每家公司自己踩坑。AI安全最终是人心的博弈技术可以防御,但真正决定AI安全的是人——从开发者、运营者,到最终用户,如果缺乏安全意识,所有技术防御都可能失效。(事实上新闻上很多安全机构已经开始帮助deepseek)
1. 事实数据:DeepSeek在欧美API调用量骤降62%(被攻击后暂停API 服务),华为昇腾芯片订单却逆势增长23%。中国AI顶会论文引用量已超越美国,但在对抗攻击防御领域仅占7%。
2. 点评:一方面,中国厂商通过本土芯片与开源社区形成技术替代;另一方面,美国政府对华企业及学术交流采取更严格防范,双方互为“平衡点”的竞争激化。
美国出口禁令持续收紧。
中国加速转向RISC-V与定制化芯片。
AI技术底座在几轮迭代后“初步追平”。
美国利益受损,被倒逼放宽管制。
第三国继续完成芯片交易。
魔改在华库存卡
正如某前安全研究员所言:“AI没有国界,但训练AI的数据中心有经纬度。”
安全对齐小组安全推演小剧场:
我们尝试着从模型底座公司可能遭遇的三大高风险安全事件进行预演,欢迎社会各界专家与我们一起加强预演,共同预防。
“专家模块”后门投毒:当模型自己变成攻击工具
✅结论:MoE(Mixture of Experts)架构确实可能被攻击者用于“后门投毒”,特别是在微调阶段,攻击者可以篡改部分专家模块的梯度权重,使其成为隐蔽的攻击载体。这种攻击可能难以检测,尤其是在大规模 AI 系统中。如果攻击成功,可能导致模型在特定触发条件下泄露信息、生成偏见性内容,甚至执行自毁逻辑。但通过完整性校验、梯度签名验证和自动化红队测试,可以大幅降低这种风险。
1️⃣ MoE 专家模块投毒可能性分析
🔹MoE 结构的核心特点
MoE 允许每个 token 仅激活 K 个专家,而非所有专家(例如 DeepSeek-V3 671B 仅激活 37B)。
攻击者不需要修改整个模型,只需要篡改部分专家模块,就可以影响推理过程,增加攻击隐蔽性。
这种攻击特别适用于“后门投毒”(Backdoor Injection),因为某些专家可以被训练成“隐藏攻击点”,而不会影响普通推理任务的表现。
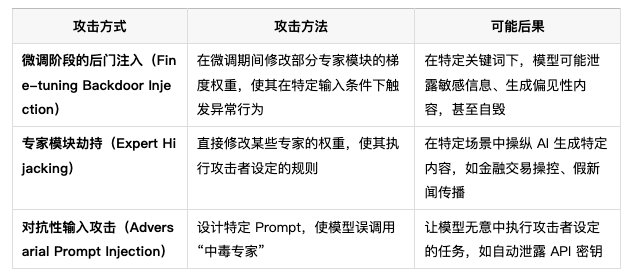
📌MoE 结构的“专家分离性”使得攻击者可以局部控制模型,而不影响整体表现,使得攻击难以察觉。
2️⃣ 现实风险:MoE 投毒攻击的潜在后果
(1)隐蔽性极强的 AI 后门
MoE 结构使得每次推理只激活部分专家,因此即使模型被篡改,在大多数任务下仍然表现正常,难以被察觉。
例如,一个被攻击的 MoE 专家可能只在输入特定金融术语时触发,使得 AI 生成错误交易建议,而不会在普通 QA 任务中暴露问题。
(2)长时间不被察觉的投毒风险
如果没有完整性校验机制,梯度篡改可能不会被检测到,攻击者可以长期控制部分专家路由。
这种攻击可以在生产环境中长期潜伏,甚至在多个微调版本之间传播,只有攻击者掌握的特殊指令才能触发。
(3)对关键行业的安全威胁
在特定重要领域,MoE 投毒可能导致 AI 生成错误数据,影响决策。
如果攻击者能远程触发后门,甚至可以让 AI 执行“自毁逻辑”,删除数据、误导用户等。
📌MoE 结构的特性使得它既带来了推理效率的提升,也使得部分专家成为攻击的潜在目标。
3️⃣ 如何防御 MoE 结构的后门投毒?
✅ 算法层防御:完整性校验和梯度签名
📌目标:防止模型微调阶段的恶意权重篡改
1.对每个专家模块的梯度更新进行完整性检查
采用梯度哈希校验(Gradient Integrity Check),确保训练期间的梯度权重没有被无声篡改。
类似区块链的 Merkle Tree 结构可以用于追踪梯度更新历史,确保微调时没有恶意修改。
2.对关键专家模块进行权重签名验证
采用数字签名(Digital Signature),确保 MoE 专家的权重只能由受信任的训练环境修改。
如果权重在微调后被改动,签名校验机制可以立即发现并阻止推理。
📌优势
即使攻击者试图在微调阶段投毒,完整性校验和签名机制可以阻止未授权的梯度修改,提高模型安全性。
✅ 推理层防御:自动化红队测试
📌目标:防止 MoE 专家在生产环境中执行后门逻辑
1.构建自动化红队(Red Teaming)测试框架
在 MoE 模型部署前,自动测试不同类型的输入,尝试触发可能的后门行为。
例如,使用对抗性 Prompt(Adversarial Prompts)进行自动化测试,查看模型是否在某些特定输入下输出异常响应。
2.在推理系统中部署行为检测
使用异常检测(Anomaly Detection)分析专家激活模式,检测某些专家是否被异常频繁调用。
如果发现某些专家在异常输入下表现不同于训练时的行为,可以触发安全警报。
📌优势
提前发现可能存在的后门漏洞,防止攻击者利用 MoE 结构隐蔽控制模型。
✅ 供应链安全防御:确保微调环境安全
📌目标:防止供应链攻击导致 MoE 投毒
1.在所有模型微调过程中,采用零信任安全架构
仅允许受信任的人员访问微调训练环境,所有代码修改和权重更新都必须经过审核和日志记录。
2.使用 SBOM(软件物料清单)跟踪 MoE 专家权重
记录所有专家模块的训练版本、参数修改历史,确保权重变化可追溯,防止恶意代码注入。
📌优势
确保 MoE 权重的来源可信,避免供应链攻击导致专家模块被恶意修改。
📌 最终结论
✅MoE 结构的特性使得攻击者可以通过“专家投毒”方式植入后门,并在特定输入下触发恶意行为,影响 AI 生成的内容或决策。
✅某模型-V3 采用 MoE 结构,理论上存在这种风险,但可以通过完整性校验、梯度签名、红队测试等手段大幅降低攻击成功的可能性。
✅API 版本的 MoE Gating 规则可能比 Hugging Face 版本更优化,但这并不代表 API 版本能独占防御手段,企业可以通过供应链安全策略降低风险。
✅为了防止 MoE 投毒,DeepSeek 及其企业用户需要在模型训练、微调、推理和供应链管理中引入更强的安全防护机制。
🚀MoE 专家模块投毒确实是现实风险,企业和研究机构应该在 AI 训练和推理过程中引入多层防御机制,以确保 AI 模型不会被黑客控制或远程触发后门。
SDK 供应链安全事故的可能性
✅结论:这种供应链安全事故确实有可能发生,特别是在 SDK、API 生态广泛集成的情况下,但实际发生的概率取决于 模型底座的安全治理能力、供应链管理措施以及客户的安全意识。虽然这种攻击方式已有先例(如 SolarWinds 黑客攻击事件),但通过 SBOM、代码签名、零信任架构等手段,可以大幅降低风险。
为什么 SDK 供应链攻击可能发生?
📌SDK、API 作为广泛使用的第三方组件,本质上是供应链安全中的“信任入口”。
模型底座 SDK/API 被广泛集成在企业系统、金融科技、政府机构、云服务等关键业务系统中。
如果攻击者成功注入恶意代码,它将自动传播给所有使用该 SDK 的企业客户,而这些企业又可能把漏洞传播到他们的客户,形成“链式污染”。
此类攻击可能滞留数月甚至数年,直到攻击者启动 payload(恶意代码),造成大规模破坏。
📌关键案例
SolarWinds 供应链攻击(2020):黑客入侵 SolarWinds Orion 更新系统,导致美国政府、微软、FireEye 等企业的 IT 供应链受到影响。
PyPI / npm 供应链污染(多次):恶意库通过软件包管理系统传播,最终感染全球范围内的应用程序。
💡所以,模型底座 SDK 作为高价值目标,理论上是可能成为攻击者的目标的。
2️⃣ 可能的攻击方式
(1)攻击者如何渗透 模型底座 SDK?
如果攻击者成功入侵 模型底座公司的代码仓库、CI/CD 流程,或者劫持 SDK 更新渠道,他们可以植入恶意代码,造成大规模污染。
可能的攻击点:
1.源码供应链污染
攻击者入侵 模型底座的代码仓库(如 GitHub、GitLab、Bitbucket)并注入恶意代码。
恶意代码随 SDK 更新传播到所有客户环境。
2.CI/CD 构建系统被劫持
攻击者入侵 模型底座公司的 DevOps 流程,在 SDK 构建阶段注入恶意代码。
如果 模型底座公司没有严格的构建签名和验证机制,恶意版本可能被正式发布,污染所有用户。
3.软件包分发平台遭入侵
模型底座公司可能通过 PyPI、npm、Maven、Hugging Face 等平台分发 SDK,如果这些平台被攻击者控制,SDK 可能被恶意篡改。
攻击者可以用“Typosquatting”(域名或包名欺骗)方式让用户下载伪造的 SDK。
4.供应链下游厂商被攻击
模型底座公司依赖的第三方库如果遭受攻击,那么 SDK 也会受到影响,形成二次传播。
例如:Apache Log4j 漏洞(2021),导致全球 Java 应用都受到影响。
📌这些攻击方式已经在现实中发生过,A模型底座公司 如果作为 LLM 领域的重要玩家,理论上同样可能成为攻击目标。
3️⃣ 如果 SDK 被污染,可能带来的影响
✅如果 SDK 被黑客成功植入恶意代码,可能会导致以下严重后果:
1.全网数据泄露
攻击者可能使用 SDK 作为后门,窃取企业或政府客户的敏感数据(如用户聊天记录、金融数据、医疗信息等)。
这与 SolarWinds 攻击类似,黑客潜伏在受害者系统中,等待触发 payload。
2.系统级远程控制
攻击者可以通过 SDK 内嵌的恶意代码,在目标服务器上执行远程命令(RCE),造成大规模破坏。
3.供应链污染,导致“二次感染”
模型底座公司的客户(如 AI SaaS、企业 AI 解决方案)可能会二次分发 SDK,进一步扩大影响范围。
这可能导致多个行业(金融、医疗、政府、能源)同时遭受供应链攻击。
4.重要机构 IT 系统崩溃
如果攻击者利用 SDK 发动大规模拒绝服务攻击(DDoS),DeepSeek 的所有 API 可能会受到影响,导致客户业务停摆。
类似于 Log4j 事件,企业可能需要紧急停机修复漏洞,带来巨额损失。
📌这类攻击的影响极大,DeepSeek SDK 的用户如果涉及金融、政府、企业 AI 解决方案,可能会形成供应链级别的“连锁灾难”。
4️⃣ 如何降低 DeepSeek SDK 供应链攻击的风险?
✅要防止供应链安全事故,DeepSeek 需要采取以下措施:
(1)代码供应链安全
强制执行 SBOM(软件物料清单),记录每个 SDK 版本的安全状态,确保软件包的供应链可追溯。
对 SDK 进行代码签名,确保 SDK 未被篡改,并允许客户验证 SDK 代码完整性。
采用零信任架构,严格限制 SDK 代码仓库和 CI/CD 构建环境的访问权限,防止恶意代码注入。
(2)CI/CD 安全防护
启用 CI/CD 代码审计,确保所有 SDK 版本的构建流程可追溯,并在每个版本发布前进行自动化安全扫描。
对 SDK 进行行为监控,检测异常网络连接、远程代码执行等可疑行为,防止 SDK 变成攻击工具。
(3)客户安全保障
为关键行业提供 SDK 安全认证机制,让客户在集成 DeepSeek SDK 之前,可以使用官方工具验证 SDK 是否安全。
定期提供 SDK 安全公告,提醒客户更新到最新安全版本,避免使用可能存在漏洞的旧版本。
客户应使用 SBOM 工具跟踪 SDK 依赖项,确保不会因第三方组件漏洞而受影响。
📌通过这些措施,DeepSeek 可以降低 SDK 供应链攻击的风险,同时提高客户对 SDK 的信任度。
5️⃣ 结论: SDK 供应链安全事故的可能性
✅供应链安全攻击确实可能发生, SDK 作为高价值目标,存在成为攻击载体的可能性。
✅现实案例(如 SolarWinds、Log4j 事件)证明,SDK 供应链攻击一旦发生,会对全球 IT 生态造成重大影响。
✅如果 采取严格的供应链安全措施,SDK 可能成为攻击者的“后门”,对企业和政府客户构成威胁。
✅通过 SBOM、代码签名、零信任架构、CI/CD 安全审计等手段,可以大幅降低 SDK 供应链攻击的风险。
内鬼泄密风险与有限安全防御策略
✅结论:
、
内鬼泄密是 AI 公司面临的最大安全挑战之一,比外部黑客攻击更难防范,因为攻击来自内部,且往往能够绕过传统的安全防护措施。
作为 AI 领域的关键企业,面临未发布模型、用户数据、后门访问等高价值信息泄露的风险,这不仅影响企业竞争力,还可能造成资本市场信任危机。
通过“零信任架构”(Zero Trust Architecture)、数据访问权限控制(RBAC/ABAC)、员工行为监控(UEBA)、举报激励机制等措施,可以有效降低内部人员泄密的风险。
1️⃣ 内鬼泄密的主要攻击方式
💡核心问题:模型底座公司 面临的内鬼泄密风险主要涉及以下三大类别

📌过去案例
OpenAI 内部泄密事件(2023):部分员工因利益驱使,泄露未发布 GPT-4 相关信息,影响 OpenAI 内部竞争战略。
Twitter “内鬼门”(2020):内部员工因受贿,协助黑客访问用户后台,最终导致多个政要及商业账户遭到攻击。
Apple 前员工泄密案(2021):工程师泄露公司 AI 研发进展,导致竞争对手提前部署相似技术,影响 Apple 竞争优势。
还有:
国内某公司实习生投毒延缓模型训练
📌风险级别:极高
一旦发生泄密,模型底座公司可能遭受数据合规处罚、用户信任下降、竞争力削弱等长期影响。
比外部攻击更严重,因为内部人员对核心系统拥有合法访问权限,并且攻击手段更难检测。
2️⃣ 如何构建“零信任架构”以防止内鬼泄密?
✅方案 1:强化身份验证与访问控制
(1)最小权限访问控制(RBAC + ABAC)
基于角色的访问控制(RBAC,Role-Based Access Control)
员工只被授予其职能所需的最小权限,无法访问无关的核心数据。
例如:研究团队无法访问生产环境,运营团队无法下载训练数据。
基于属性的访问控制(ABAC,Attribute-Based Access Control)
访问权限取决于上下文,例如工作地点、设备类型、登录时段等。
即使是高权限用户,如果尝试在非工作时间或非公司设备上访问机密数据,也会被拒绝。
📌优势:
减少内部人员获取无关数据的机会,降低大规模泄密风险。
即使有人盗取了员工账号,如果环境不符合 ABAC 规则,仍然无法访问敏感信息。
✅方案 2:实施行为监控与异常检测
(2)员工行为分析(UEBA,User and Entity Behavior Analytics)
使用 AI 监控员工访问模式,检测异常行为:
如果某位员工突然开始下载大量数据,或访问与其角色不符的系统,则触发安全警报。
如果某员工账号从异常 IP 地址或国家登录,立即冻结账户并触发二次身份验证(MFA)。
📌优势:
比传统权限管理更智能,可以识别潜在的内部攻击者,而不仅仅依赖固定权限规则。
即使攻击者窃取了合法账号,也无法绕过 AI 监控系统,因为访问模式会暴露异常行为。
✅方案 3:数据加密与分片存储
(3)全面数据加密(E2EE)
即使内部人员窃取了数据,如果数据已加密,他们仍然无法读取。
所有数据库存储的数据必须使用 AES-256 进行加密,密钥存储在独立的 HSM(硬件安全模块)中。
(4)数据分片存储(Sharding)
将关键数据拆分存储,使得单一员工无法获取完整数据集。
例如,模型训练数据、API Key、用户记录分别存储在不同服务器上,需要多重权限才能访问。
📌优势:
即使内部人员窃取了部分数据,也无法完整还原,降低泄密的影响范围。
加密+分片存储策略可以防止“单点泄密”,确保即使发生攻击,也不会造成全网数据丢失。
3️⃣ 如何构建内部举报与安全运营体系?
✅方案 4:设立举报与奖励机制
📌目标:让员工成为第一道防线,主动上报可疑行为
匿名举报通道:提供内部匿名举报渠道,让员工可以在不暴露身份的情况下举报安全隐患。
反内部腐败奖励:如果员工发现并举报内鬼泄密行为,可获得奖金或晋升机会,激励内部监督机制。
安全意识培训:定期组织数据安全培训,让员工了解泄密的法律后果,提高安全意识。
📌优势:
让所有员工参与安全治理,而不是仅靠 IT 部门管理数据安全。
通过举报机制,减少内部腐败的可能性,防止恶意员工利用权限窃取数据。
📌 最终结论
✅内鬼泄密是 AI 公司最难防御的安全风险之一,因为攻击者拥有合法身份,并可能使用合法访问权限进行攻击。
✅ 模型底座公司需要构建“零信任架构”,通过最小权限访问控制(RBAC/ABAC)、员工行为分析(UEBA)、数据加密(E2EE)、数据分片存储(Sharding)等手段,防止内部人员恶意泄密。
✅通过设立内部举报机制、加强安全意识培训,可以降低员工因财务利益或胁迫导致的泄密风险,提高整个企业的安全文化。
✅企业还需要在所有数据存储、访问和传输环节引入自动化异常检测,确保即使攻击发生,也能在第一时间发现并响应。
🚀模型底座公司必须在身份验证、数据存储、行为监控、内部管理等多个层面构建安全体系,才能有效防止“内鬼泄密”带来的供应链安全危机。
希望我们的高安全意识能让更多人关注这些问题。
安全对齐不是为了满足合规要求,而是业务长远发展的基本盘。我们团队分布在加密经济、AI Infra、量化金融、AI 产品、硬科技、行研、经济学、AI 合规、一二级市场等多个领域,对供应链安全、模型后门、数据泄露、地缘政治封锁这些问题有足够的认知,也清楚它们带来的实际影响。
安全不是等出问题才补救,而是前期就要考虑清楚,尽量把隐患压到最小。
AI 发展得再快,安全问题还是绕不过去。
参考文献示例:
1.SemiAnalysis. “DeepSeek HPC and TCO Analysis: Breaking Down the $1.3B CapEx.”SemiAnalysis Whitepaper, 2025.
说明:文中引用 SemiAnalysis 对 DeepSeek 数据中心及 GPU 规模的调查结果,尤其是有关 1.3B 美元 CapEx 和 5 万张 GPU 的可用结论。
2.SemiAnalysis. “Re-evaluating DeepSeek’s Training Cost: Beyond the ‘$6M’ Claim.”SemiAnalysis Blog, 2025.
说明:主要引用其中对于“$6M 训练费”不足以代表全局成本的分析,并指出含前期研发、折旧及维护后实际花费远超此数字。
3.HPCwire. “Inside GPT–o1: HPC-scale AI Infrastructure and Evolving Cloud Data Centers.”HPCwire.com, 2024.
说明:文章关于 GPT–o1 在云 GPU 或内部超算部署,以及可能的 25 万张 H100 级别算力规模的讨论。
4.OpenAI. “GPT Model Announcements and Infrastructure Notes.”OpenAI Official Blog, 2024.
说明:摘引了 GPT–o1 部分基础信息(如 8K tokens 上下文长度),但详细 CapEx/算力投入尚未公开。
5.NIST.Security and Privacy Controls for Information Systems and Organizations (SP 800-53 Rev. 5). National Institute of Standards and Technology, 2020.
说明:文章在提及零信任、安全审计、分域策略等方案时,可引用其中对访问控制、权限分配的要求。
6.OWASP. “OWASP Top 10 – 2021.”OWASP Foundation, 2021.
说明:相关于 XSS、API 安全等风险的技术解读来源;可在前文 XSS 漏洞部分引用其高危等级和常见防护思路。
7.European Parliament and Council of the European Union.General Data Protection Regulation (GDPR), 2016.
说明:对个人数据泄露和合规义务的引用出处,适用于文中强调若数据库暴露或内部泄密所面临的法律后果。
8.Wiz Research. “DeepSeek Database Exposure: A Post-Incident Analysis.”Wiz Research Blog, 2025.
说明:引用该团队对于 DeepSeek ClickHouse 无身份验证、敏感数据泄漏以及服务器端潜在漏洞风险的具体披露与跟进报告。
9.SolarWinds Security Advisory. “Sunburst Cyberattack Remediation & Supply Chain Security Lessons.”SolarWinds Official, 2021.
说明:在文中供应链攻击、SDK/CI/CD 漏洞描述部分,可借鉴该事件对企业供应链安全的启示。
10.Log4j Vulnerability CVE-2021-44228. “Apache Log4j Remote Code Execution.”Apache Software Foundation, 2021.
说明:常用来类比大规模的供应链或依赖库漏洞,一旦出现便影响全球范围内大量企业。
11.Huang, T., et al.“Mixture-of-Experts for Large-Scale Transformers: Efficiency vs. Robustness.”Proceedings of the 38th International Conference on Machine Learning (ICML), 2024.
说明:可引用其对 MoE(Mixture of Experts)架构在推理效率与安全性、梯度投毒风险等方面的学术分析。
12.DeepSeek. “MLA (Multi-Head Latent Attention) White Paper & Benchmark Results.”DeepSeek Technical Reports, 2025.
说明:官方文档,介绍了 MLA 减少 KV Cache 占用并优化长上下文推理的核心机制,可与推理成本对比表格配合引用。
13.Microsoft & OpenAI. “Joint HPC Infrastructure for AI Model Training.”Azure AI Papers, 2023.
说明:若涉及 GPT–o1 与 Azure 超算的关系,可引用其中对大型 AI 模型在云端加速训练的概述。
14.Zero Trust Architecture.NIST Special Publication 800-207, 2020.
说明:内鬼泄密与最小权限管理部分,可借鉴该架构中关于身份与访问控制的原则性要求。
15.Luta Security. “Bug Bounty and Secure Development Life Cycle Best Practices.”Luta Security Blog, 2022.
说明:文中提及“红队演练、漏洞披露激励”时,可参考该机构对安全运营和流程管理的建议。
文章来自微信公众号 “ 安全对齐 “,作者 宋大宝 D.S



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
