# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开发基于大模型的软件应用,就像指挥一支足球队:组件是能力各异的队员,编排是灵活多变的战术,数据是流转的足球。
Eino 是字节跳动开源的大模型应用开发框架,拥有稳定的内核,灵活的扩展性,完善的工具生态,可靠且易维护,背靠豆包、抖音等应用的丰富实践经验。初次使用 Eino,就像接手一支实力雄厚的足球队,即使教练是初出茅庐的潜力新人,也可以踢出高质量、有内容的比赛。
下面就让我们一起踏上新手上路之旅!
Eino 应用的基本构成元素是功能各异的组件,就像足球队由不同位置角色的队员组成:

这些组件抽象代表了固定的输入输出类型、Option 类型和方法签名:
type ChatModel interface {
Generate(ctx context.Context, input []*schema.Message, opts ...Option) (*schema.Message, error)
Stream(ctx context.Context, input []*schema.Message, opts ...Option) (
*schema.StreamReader[*schema.Message], error)
BindTools(tools []*schema.ToolInfo) error
}
真正的运行,需要的是具体的组件实现:
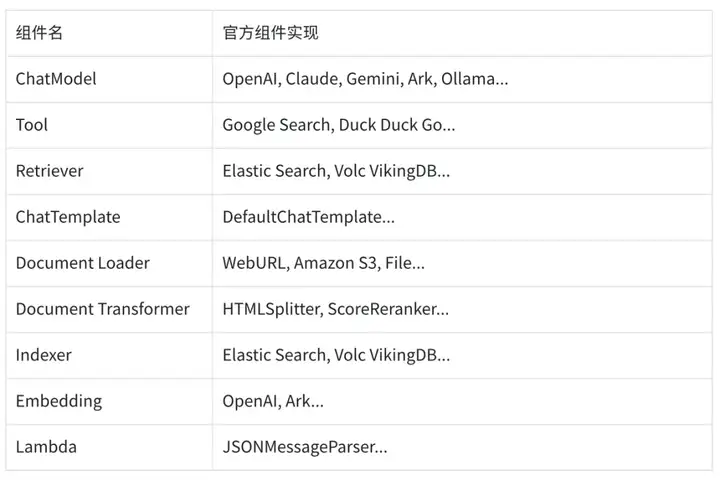
Eino 的开发过程中,首先要做的是决定 “我需要使用哪个组件抽象”,再决定 “我需要使用哪个具体组件实现”。就像足球队先决定 “我要上 1 个前锋”,再挑选 “谁来担任这个前锋”。
组件可以像使用任何的 Go interface 一样单独使用。但要想发挥 Eino 这支球队真正的威力,需要多个组件协同编排,成为一个相互联结的整体。
在 Eino 编排场景中,每个组件成为了 “节点”(Node),节点之间 1 对 1 的流转关系成为了 “边”(Edge),N 选 1 的流转关系成为了 “分支”(Branch)。基于 Eino 开发的应用,经过对各种组件的灵活编排,就像一支足球队可以采用各种阵型,能够支持无限丰富的业务场景。
足球队的战术千变万化,但却有迹可循,有的注重控球,有的简单直接。对 Eino 而言,针对不同的业务形态,也有更合适的编排方式:

Chain,如简单的 ChatTemplate + ChatModel 的 Chain:

chain, _ := NewChain[map[string]any, *Message]().
AppendChatTemplate(prompt).
AppendChatModel(model).
Compile(ctx)
chain.Invoke(ctx, map[string]any{"query": "what's your name?"})
Graph,如 ReAct Agent:
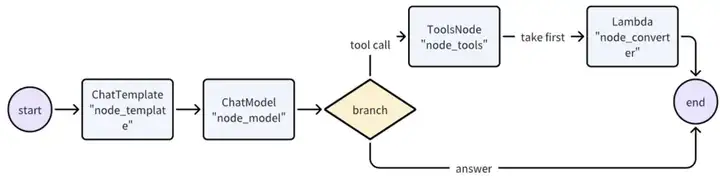
graph := NewGraph[map[string]any, *schema.Message]()
_ = graph.AddChatTemplateNode("node_template", chatTpl)
_ = graph.AddChatModelNode("node_model", chatModel)
_ = graph.AddToolsNode("node_tools", toolsNode)
_ = graph.AddLambdaNode("node_converter", takeOne)
_ = graph.AddEdge(START, "node_template")
_ = graph.AddEdge("node_template", "node_model")
_ = graph.AddBranch("node_model", branch)
_ = graph.AddEdge("node_tools", "node_converter")
_ = graph.AddEdge("node_converter", END)
compiledGraph, err := graph.Compile(ctx)
if err != nil {
return err
}
out, err := r.Invoke(ctx, map[string]any{"query":"Beijing's weather this weekend"})
现在想象下你接手的足球队用了一些黑科技,比如:在每个队员接球和出球的瞬间,身上的球衣可以自动的记录接球和出球的速度、角度并传递给场边的服务器,这样比赛结束后,就可以统计出每个队员触球的情况和处理球的时间。
在 Eino 中,每个组件运行的开始和结束,也可以通过 Callbacks 机制拿到输入输出及一些额外信息,处理横切面需求。比如一个简单的打日志能力:
handler := NewHandlerBuilder().
OnStartFn(
func (ctx context.Context, info *RunInfo, input CallbackInput) context.Context {
log.Printf("onStart, runInfo: % v, input: % v", info, input)
return ctx
}).
OnEndFn(
func (ctx context.Context, info *RunInfo, output CallbackOutput) context.Context {
log.Printf("onEnd, runInfo: % v, out: % v", info, output)
return ctx
}).
Build()
// 注入到 graph 运行中
compiledGraph.Invoke(ctx, input, WithCallbacks(handler))
再想象一下,这个足球队的黑科技不止一种,还可以让教练在比赛前制作 “锦囊” 并藏在球衣里,当队员接球时,这个锦囊就会播放教练事先录制好的妙计,比如 “别犹豫,直接射门!”。
听上去很有趣,但有一个难点:有的锦囊是给全队所有队员的,有的锦囊是只给一类队员(比如所有前锋)的,而有的锦囊甚至是只给单个队员的。如何有效的做到锦囊妙计的分发?
在 Eino 中,类似的问题是 graph 运行过程中 call option 的分发:
// 所有节点都生效的 call option
compiledGraph.Invoke(ctx, input, WithCallbacks(handler))
// 只对特定类型节点生效的 call option
compiledGraph.Invoke(ctx, input, WithChatModelOption(model.WithTemperature(0.5)))
// 只对特定节点生效的 call option
compiledGraph.Invoke(ctx, input, WithCallbacks(handler).DesignateNode("node_1"))
现在,想象一下你的球队里有一些明星球员(中场大脑 ChatModel 和锋线尖刀 StreamableTool)身怀绝技,他们踢出的球速度如此之快,甚至出现了残影,看上去就像是把一个完整的足球切成了很多片!
面对这样的 “流式” 足球,对手球员手足无措,不知道该如何接球,但是你的球队的所有队员,都能够完美的接球,要么直接一个片一个片的接收 “流式” 足球并第一时间处理,要么自动的把所有片拼接成完整的足球后再处理。身怀这样的独门秘笈,你的球队具备了面对其他球队的降维打击能力!
在 Eino 中,开发者只需要关注一个组件在 “真实业务场景” 中,是否可以处理流式的输入,以及是否可以生成流式的输出。根据这个真实的场景,具体的组件实现(包括 Lambda Function)就去实现符合这个流式范式的方法:
// ChatModel 实现了 Invoke(输入输出均非流)和 Stream(输入非流,输出流)两个范式
type ChatModel interface {
Generate(ctx context.Context, input []*Message, opts ...Option) (*Message, error)
Stream(ctx context.Context, input []*Message, opts ...Option) (
*schema.StreamReader[*Message], error)
}
// Lambda 可以实现任意四种流式范式
// Invoke is the type of the invokable lambda function.
type Invoke[I, O, TOption any] func(ctx context.Context, input I, opts ...TOption) (
output O, err error)
// Stream is the type of the streamable lambda function.
type Stream[I, O, TOption any] func(ctx context.Context,
input I, opts ...TOption) (output *schema.StreamReader[O], err error)
// Collect is the type of the collectable lambda function.
type Collect[I, O, TOption any] func(ctx context.Context,
input *schema.StreamReader[I], opts ...TOption) (output O, err error)
// Transform is the type of the transformable lambda function.
type Transform[I, O, TOption any] func(ctx context.Context,
input *schema.StreamReader[I], opts ...TOption) (output *schema.StreamReader[O], err error)
Eino 编排能力会自动做两个重要的事情:
1. 上游是流,但是下游只能接收非流时,自动拼接(Concat)。
2. 上游是非流,但是下游只能接收流时,自动流化(T -> StreamReader [T])。
除此之外,Eino 编排能力还会自动处理流的合并、复制等各种细节,把大模型应用的核心 —— 流处理做到了极致。
好了,现在你已经初步了解了 Eino 这支明星球队的主要能力,是时候通过队员 (组件)、战术 (编排)、工具 (切面、可视化) 来一场训练赛,去亲自体验一下它的强大。
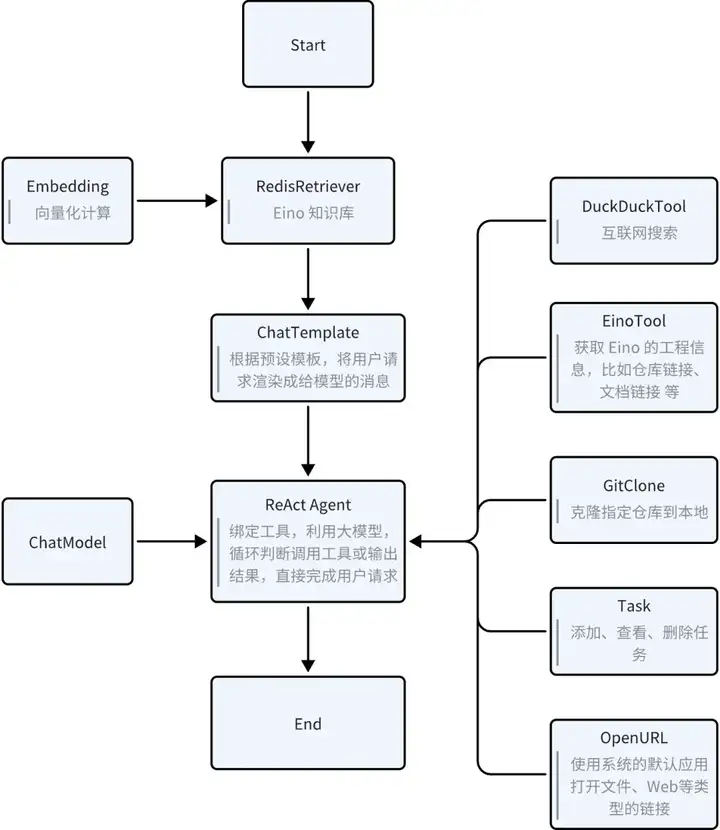
Eino 智能助手:根据用户请求,从知识库检索必要的信息并按需调用多种工具,以完成对用户的请求的处理。工具列表如下:
这里呈现一个 Demo 样例,大家可根据自己的场景,更换自己的知识库和工具,以搭建自己所需的智能助手。
先来一起看看基于 Eino 搭建起来的 Agent 助手能实现什么效果:
构建这个 Eino 智能助手分两步:
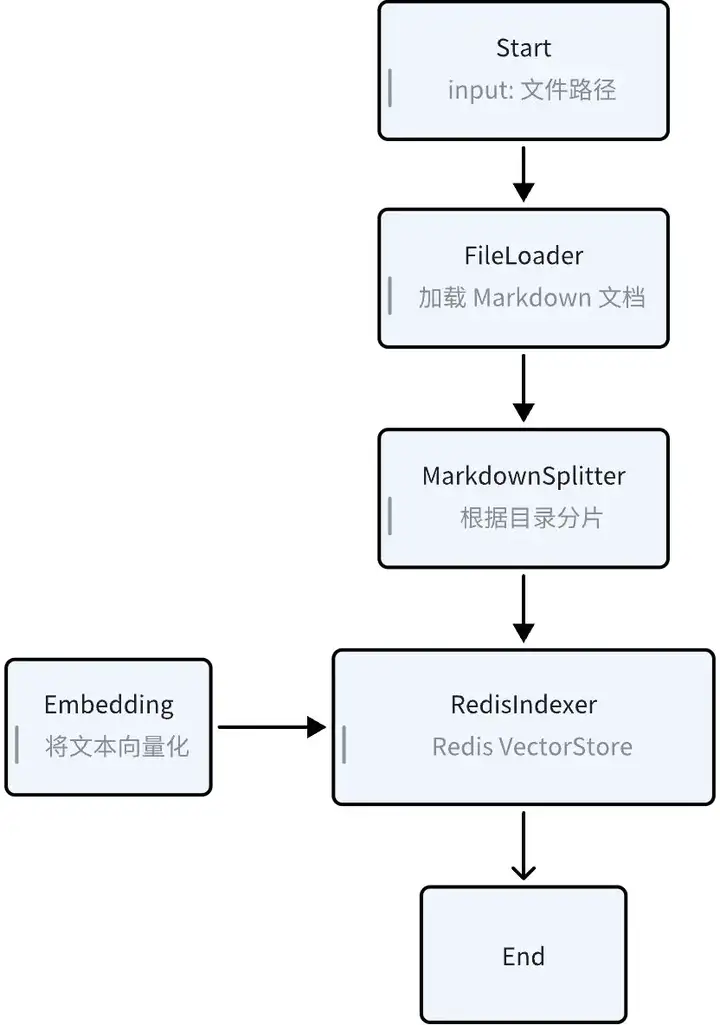
索引知识库 (Knowledge Indexing)
将 Markdown 格式的 Eino 用户手册,以合适的策略进行拆分和向量化,存入到 RedisSearch 的 VectorStore 中,作为 Eino 知识库。
Eino 智能体 (Eino Agent)
根据用户请求,从 Eino 知识库召回信息,采用 ChatTemplate 构建消息,请求 React Agent,视需求循环调用对应工具,直至完成处理用户的请求。
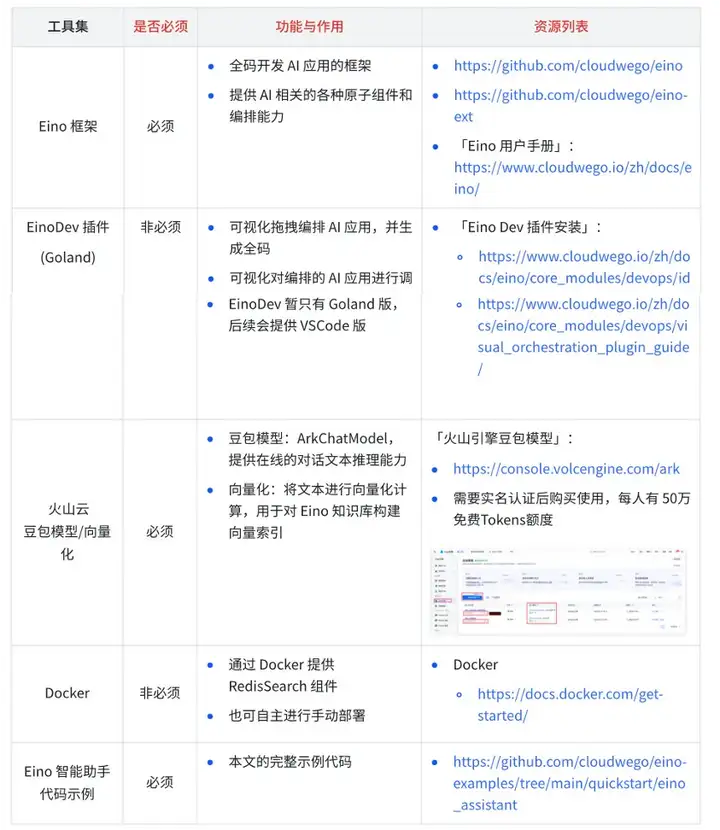
所需工具
在从零开始构建「Eino 智能助手」这个实践场景中,需要下列工具:
示例的仓库路径:https://github.com/cloudwego/eino-examples/tree/main/quickstart/eino_assistant下文中,采用相对于此目录的相对路径来标识资源位置
构建一个命令行工具,递归遍历指定目录下的所有 Markdown 文件。按照标题将 Markdown 文件内容分成不同的片段,并采用火山云的豆包向量化模型逐个将文本片段进行向量化,存储到 Redis VectorStore 中。
指令行工具目录:cmd/knowledge_indexingMarkdown 文件目录:cmd/knowledge_indexing/eino-dcos
开发「索引知识库」应用时,首先采用 Eino 框架提供的 Goland EinoDev 插件,以可视化拖拽和编排的形式构建 KnowledgeIndexing 的核心应用逻辑,生成代码到 eino_graph/knowledge_indexing 目录。
代码生成后,首先手动将该目录下的各组件的构造方法补充完整,然后在业务场景中,调用 BuildKnowledgeIndexing 方法,构建并使用 Eino Graph 实例。
接下来将逐步介绍,KnowledgeIndexing 的开发过程:
火山引擎是字节跳动的云服务平台,可从中注册和调用豆包大模型(有大量免费额度)。
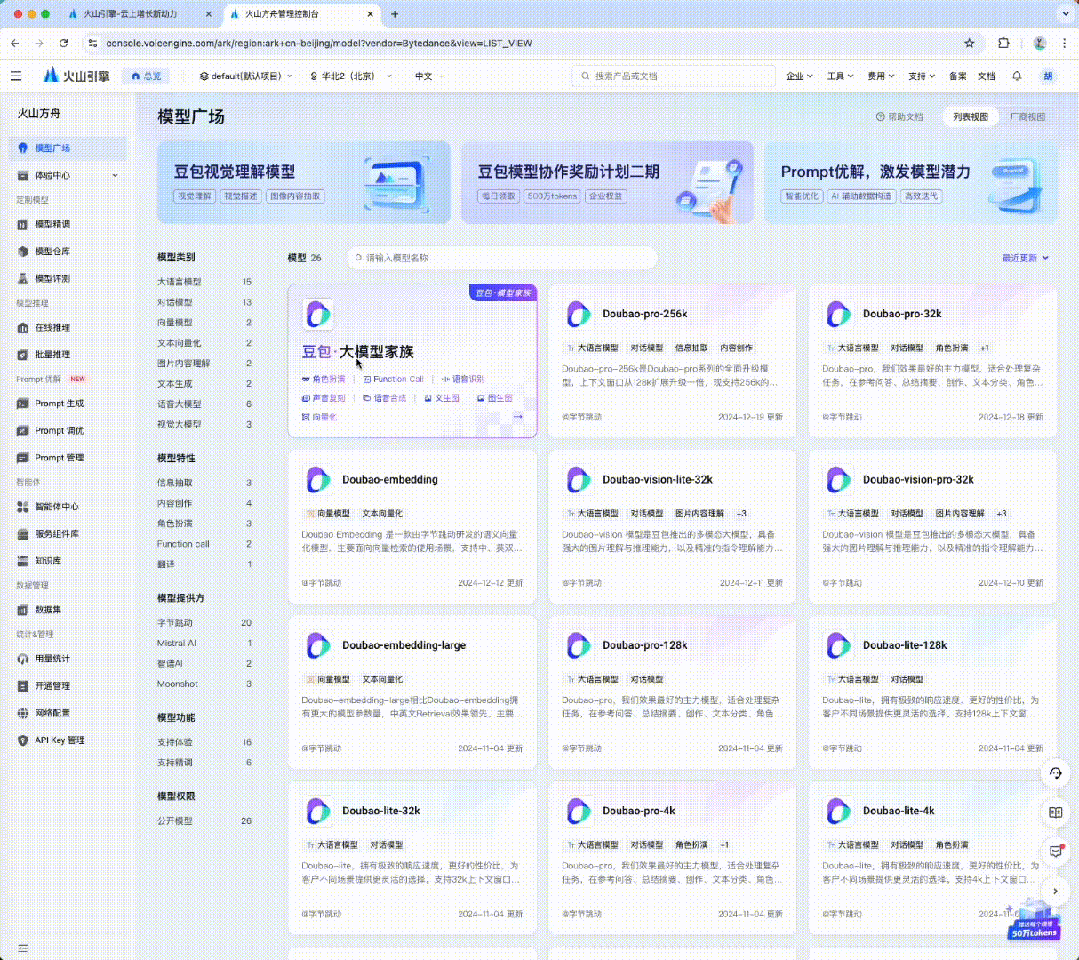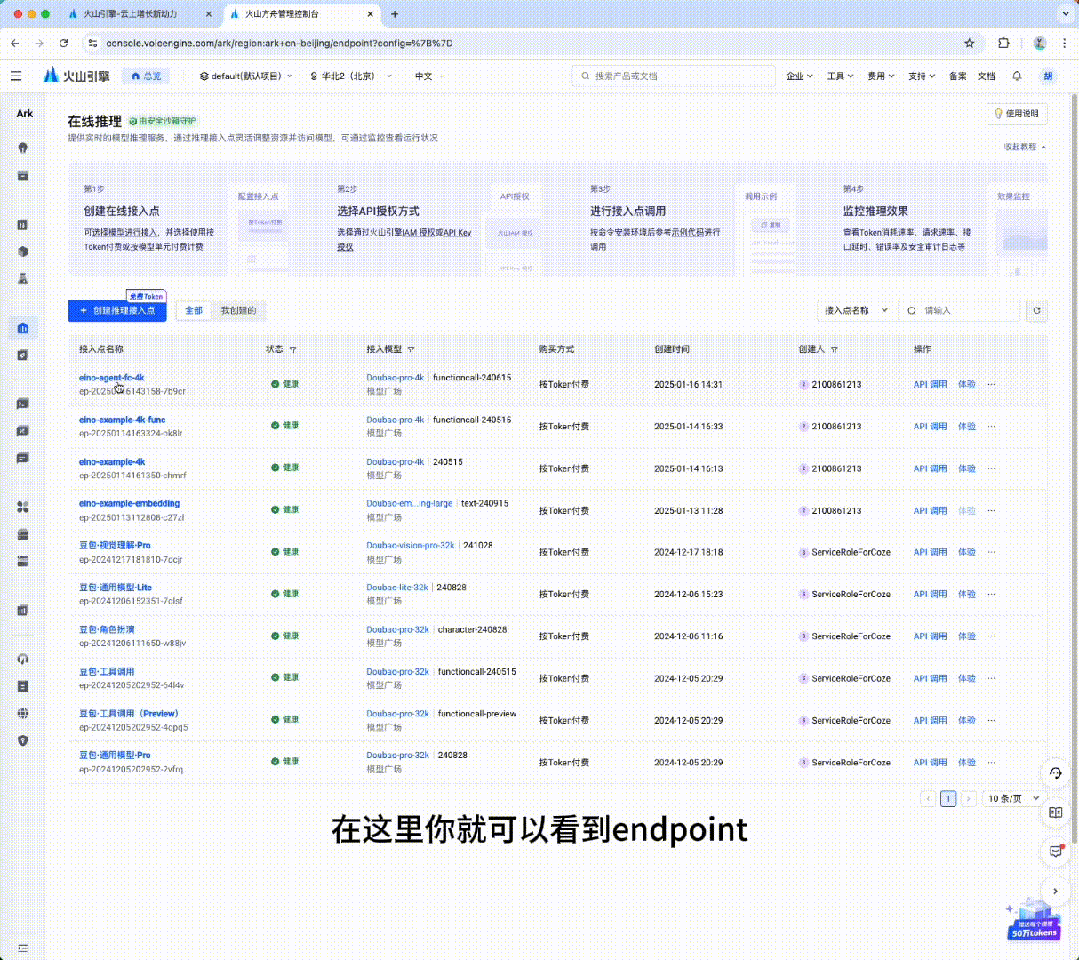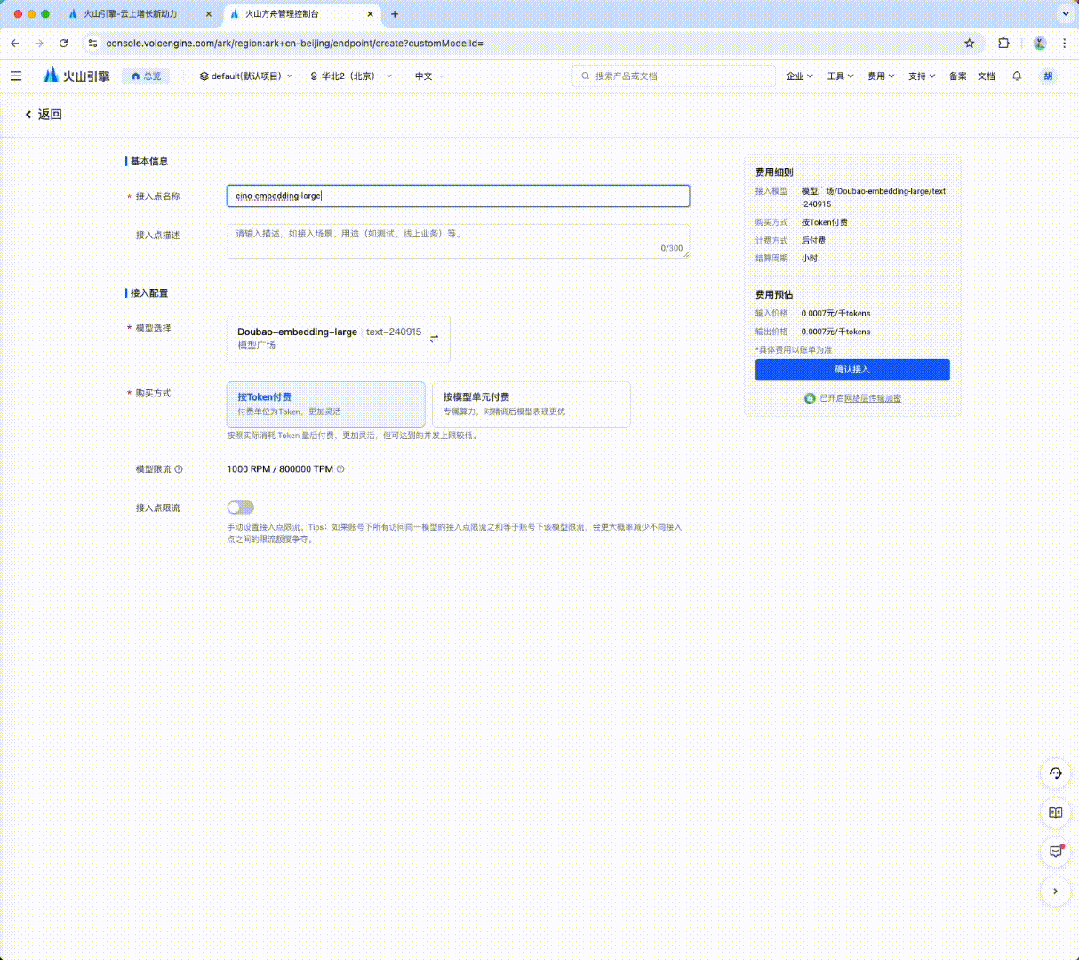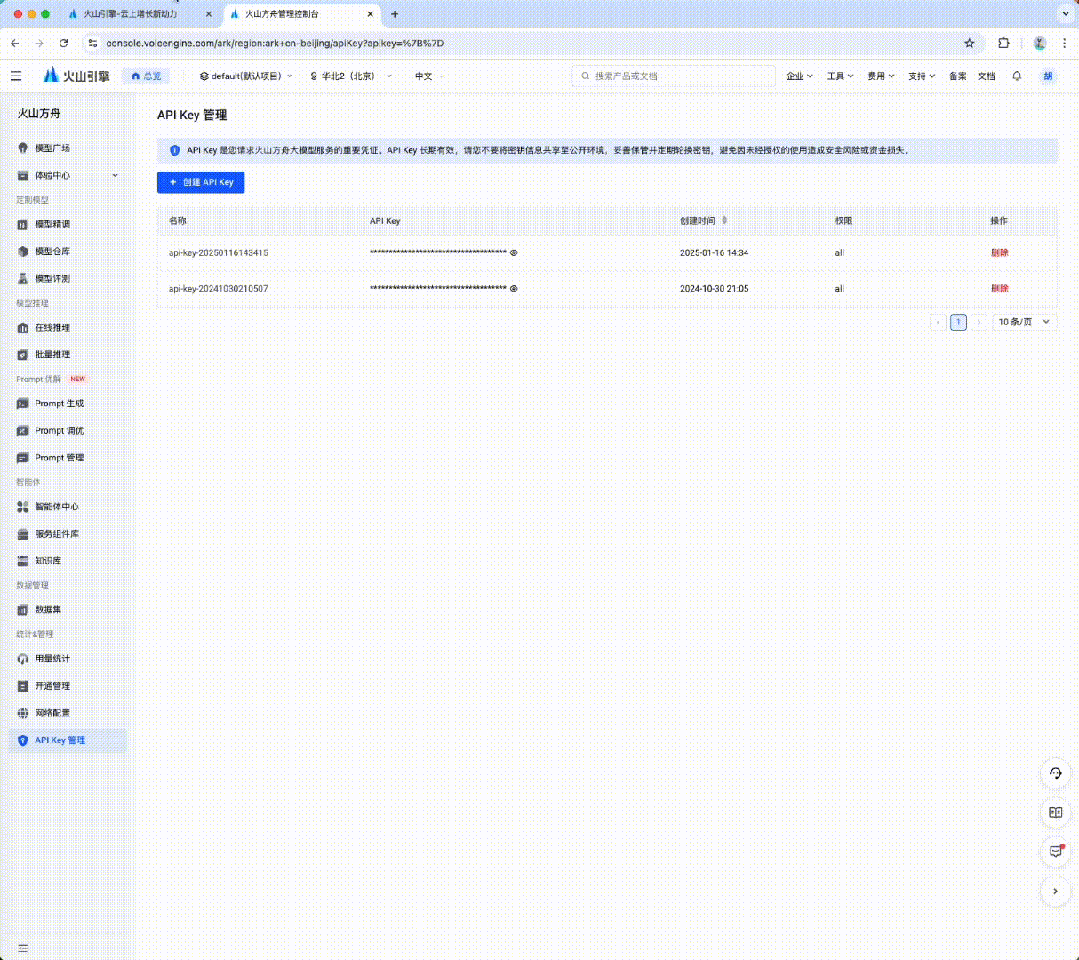
本文将使用 Redis 作为 Vector Database,为方便用户构建环境,Docker 的快捷指令如下:
直接用 redis 官方的 redis stack 镜像启动即可
# 切换到 eino_assistant 目录
cd xxx/eino-examples/quickstart/eino_assistant
docker-compose up -d

在浏览器打开链接:http://127.0.0.1:8001
「Eino 可视化开发」是为了降低 Eino AI 应用开发的学习曲线,提升开发效率。对于熟悉 Eino 的开发者,也可选择跳过「Eino 可视化开发」阶段,直接基于 Eino 的 API 进行全码开发。
1. 安装 EinoDev 插件,并打开 Eino Workflow 功能
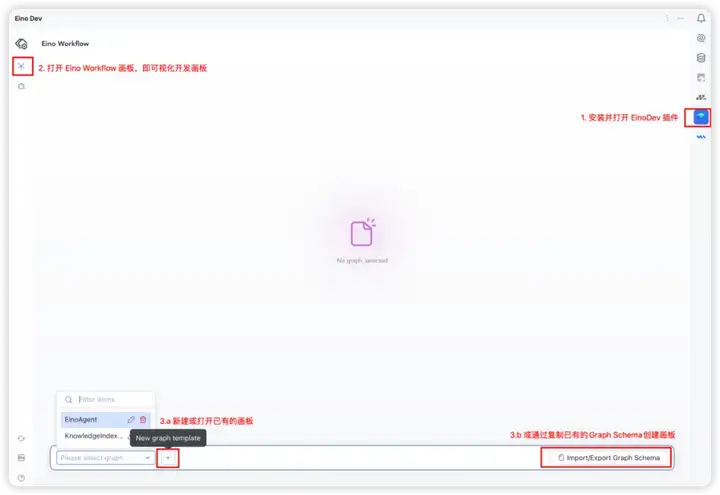
2. 按照上文「索引知识库」中的流程说明,从 Eino Workflow 中选择需要使用的组件库,本文需要用到如下组件:
3. 将选中的组件按照预期的拓扑结构进行编排,完成编排后,点击 “生成代码” 到指定目录。
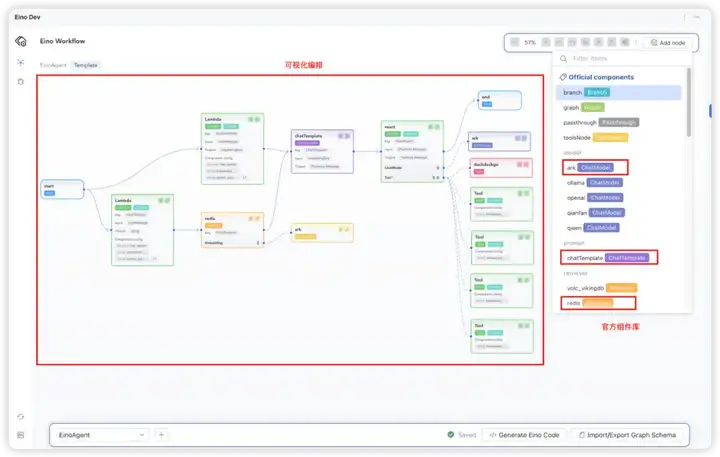
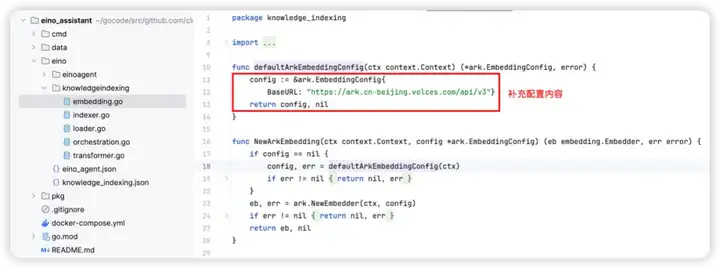
4. 按需完善各个组件的构造函数,在构造函数中补充创建组件实例时,需要的配置内容
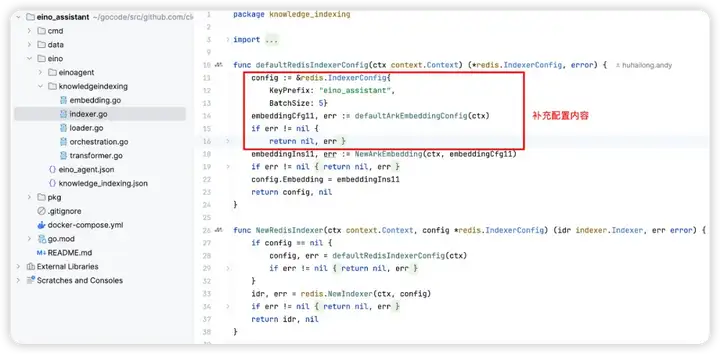
5. 补充好组件的配置内容后,即可调用 BuildKnowledgeIndexing 方法,在业务场景使用
在「索引知识库」的场景下,需要将 BuildKnowledgeIndexing 封装成一个指令,从环境变量中读取模型配置等信息,初始化 BuildKnowledgeIndexing 的配置内容,扫描指定目录下的 Markdown 文件,执行对 Markdown 进行索引和存储的操作。
详细代码可查看:cmd/knowledgeindexing/main.go
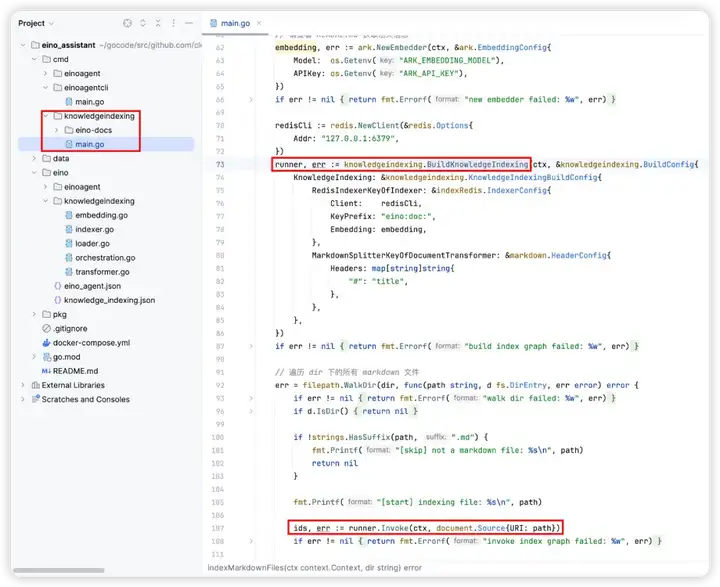
PS: 示例项目中,已经内置了 eino 的一部分文档向量化到 redis 中
1. 在 .env 文件中按照注释说明,获取并填写 ARK_EMBEDDING_MODEL 和 ARK_API_KEY 的值,按如下指令,运行 KnowledgeIndexing 指令
cd xxx/eino-examples/quickstart/eino_assistant # 进入 eino assistant 的 example 中
# 修改 .env 中所需的环境变量 (大模型信息、trace 平台信息)
source .env
# 因示例的Markdown文件存放在 cmd/knowledgeindexing/eino-docs 目录,代码中指定了相对路径 eino-docs,所以需在 cmd/knowledgeindexing 运行指令
cd cmd/knowledgeindexing
go run main.go

2. 执行运行成功后,即完成 Eino 知识库的构建,可在 Redis Web UI 中看到向量化之后的内容
在浏览器打开链接:http://127.0.0.1:8001
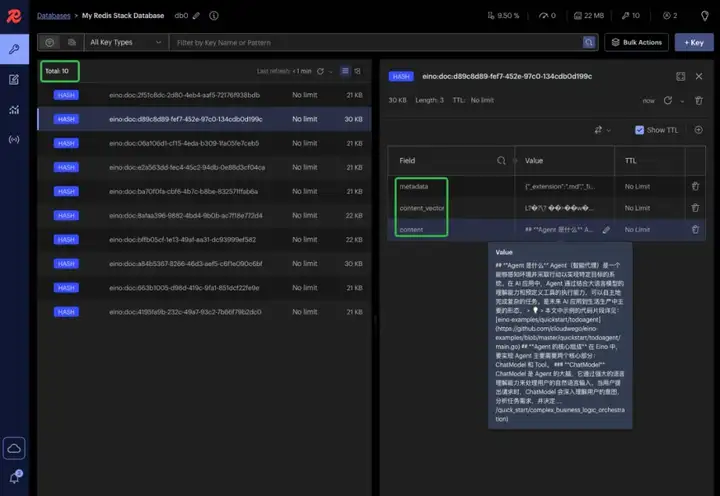
Eino 智能体
示例的仓库路径:https://github.com/cloudwego/eino-examples/tree/main/quickstart/eino_assistant下文中,采用相对于此目录的相对路径来标识资源位置
构建一个基于从 Redis VectorStore 中召回的 Eino 知识回答用户问题,帮用户执行某些操作的 ReAct Agent,即典型的 RAG ReAct Agent。可根据对话上下文,自动帮用户记录任务、Clone 仓库,打开链接等。
大模型资源创建
继续使用「索引知识库」章节中创建的 doubao-embedding-large 和 doubao-pro-4k
启动 RedisSearch
继续使用「索引知识库」章节中启动的 Redis Stack
可视化开发
1. 打开 EinoDev 插件,进入到 Eino Workflow 页面,新建一张画布
2. 按照上文「Eino 智能体」中的流程说明,从 Eino Workflow 中选择需要使用的组件库,本文需要用到如下组件:
(1)将 *UserMessage 消息转换成 ChatTemplate 节点的 map [string] any
(2)将 *UserMessage 转换成 RedisRetriever 的输入 query
3. 将选中的组件按照预期的拓扑结构进行编排,完成编排后,点击 “生成代码” 到指定目录。
4. 按需完善各个组件的构造函数,在构造函数中补充创建组件实例时,需要的配置内容
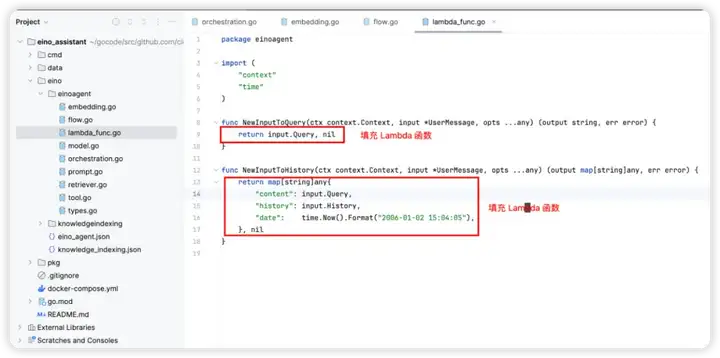
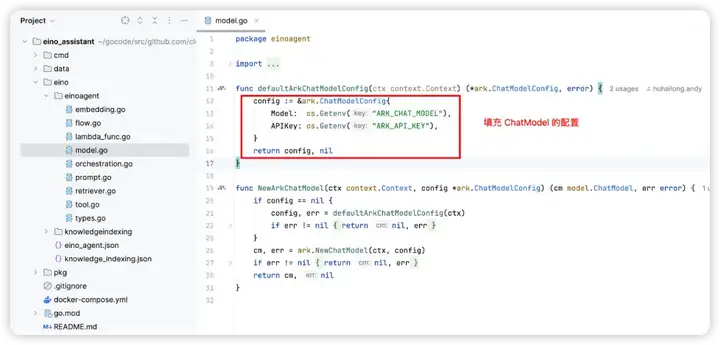
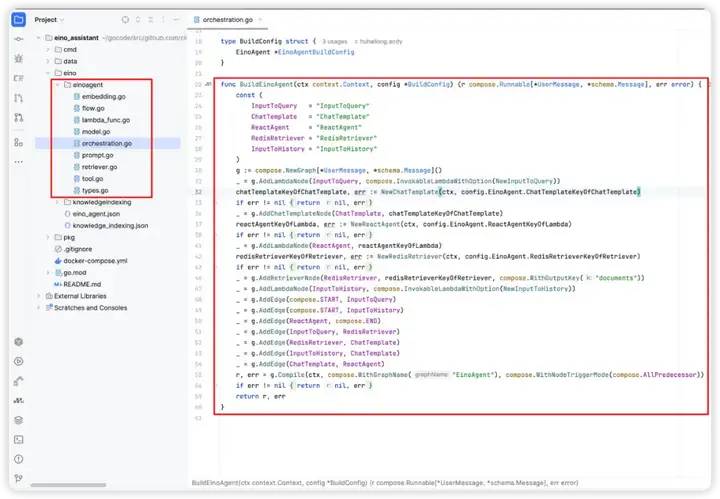
5. 补充好组件的配置内容后,即可调用 BuildEinoAgent 方法,在业务场景使用
在「Eino 智能体」的场景下,BuildEinoAgent 构建的 Graph 实例可做到:根据用户请求和对话历史,从 Eino 知识库中召回上下文, 然后结合可调用的工具列表,将 ChatModel 循环决策下一步是调用工具或输出最终结果。
下图即是对生成的 BuildEinoAgent 函数的应用,将 Eino Agent 封装成 HTTP 服务接口:
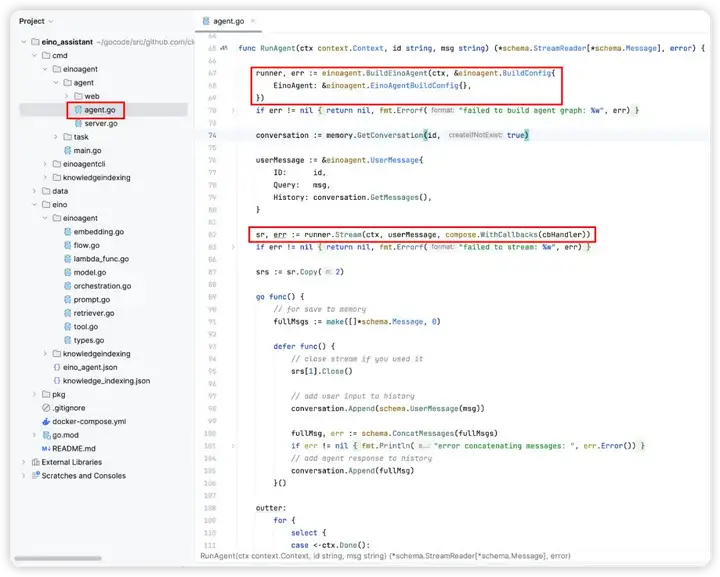
1. 在 .env 文件中按照注释说明,获取并填写对应各变量的值,按如下指令,启动 Eino Agent Server
cd eino-examples/eino_assistant # 进入 eino assistant 的 example 中
# 修改 .env 中所需的环境变量 (大模型信息、trace 平台信息)
source .env
# 为了使用 data 目录,需要在 eino_assistant 目录下执行指令
go run cmd/einoagent/*.go
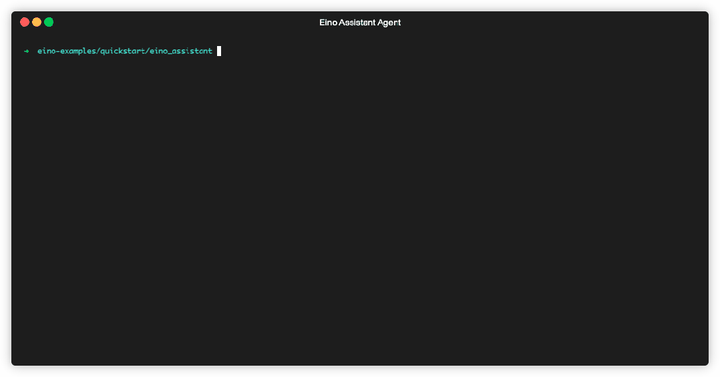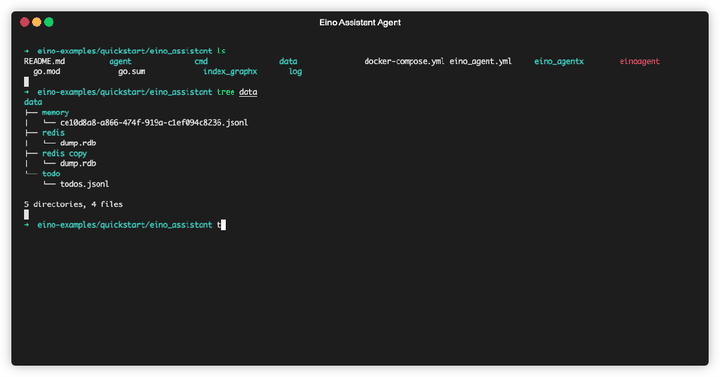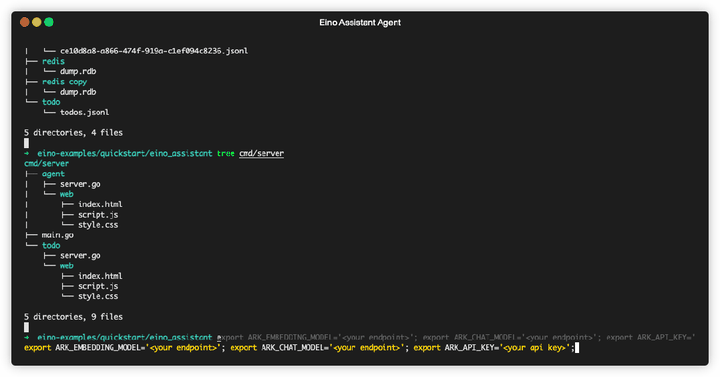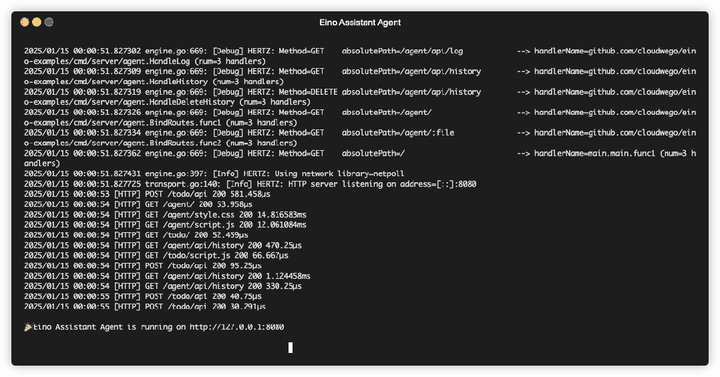
2. 启动后可访问如下链接,打开 Eino Agent Web
Eino Agent Web:http://127.0.0.1:8080/agent/
观测 (可选)
如果在运行时,在 .env 文件中指定了 LANGFUSE_PUBLIC_KEY 和 LANGFUSE_SECRET_KEY,便可在 Langfuse 平台中,登录对应的账号,查看请求的 Trace 详情。
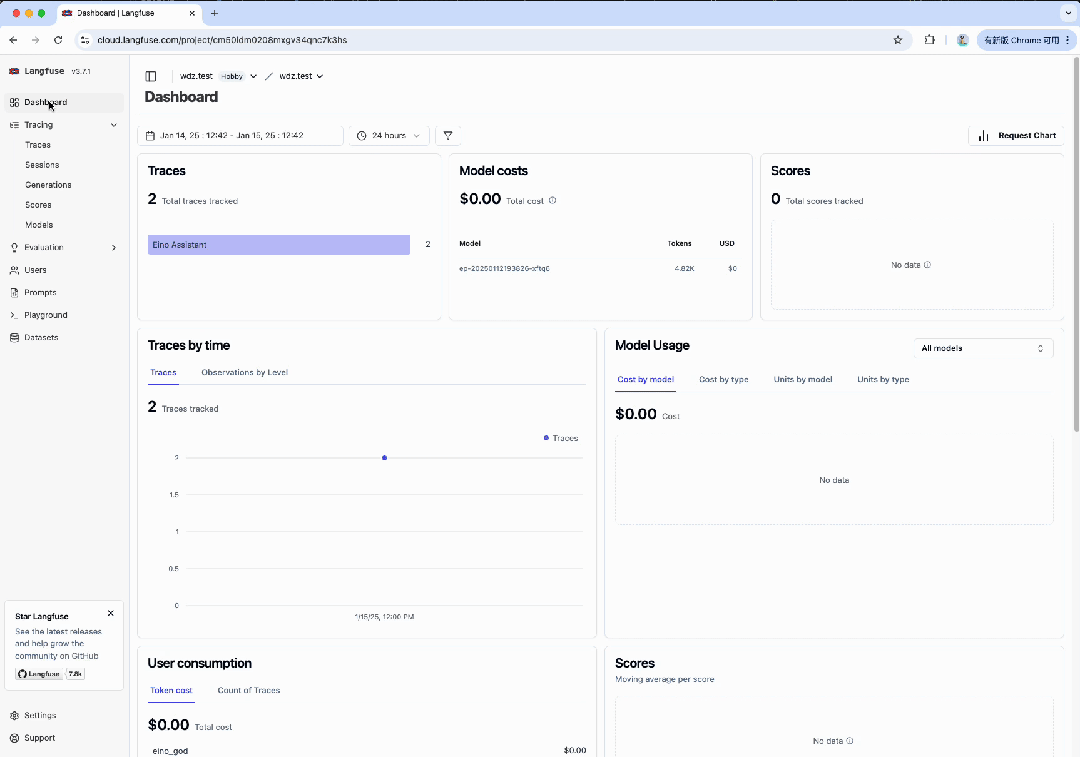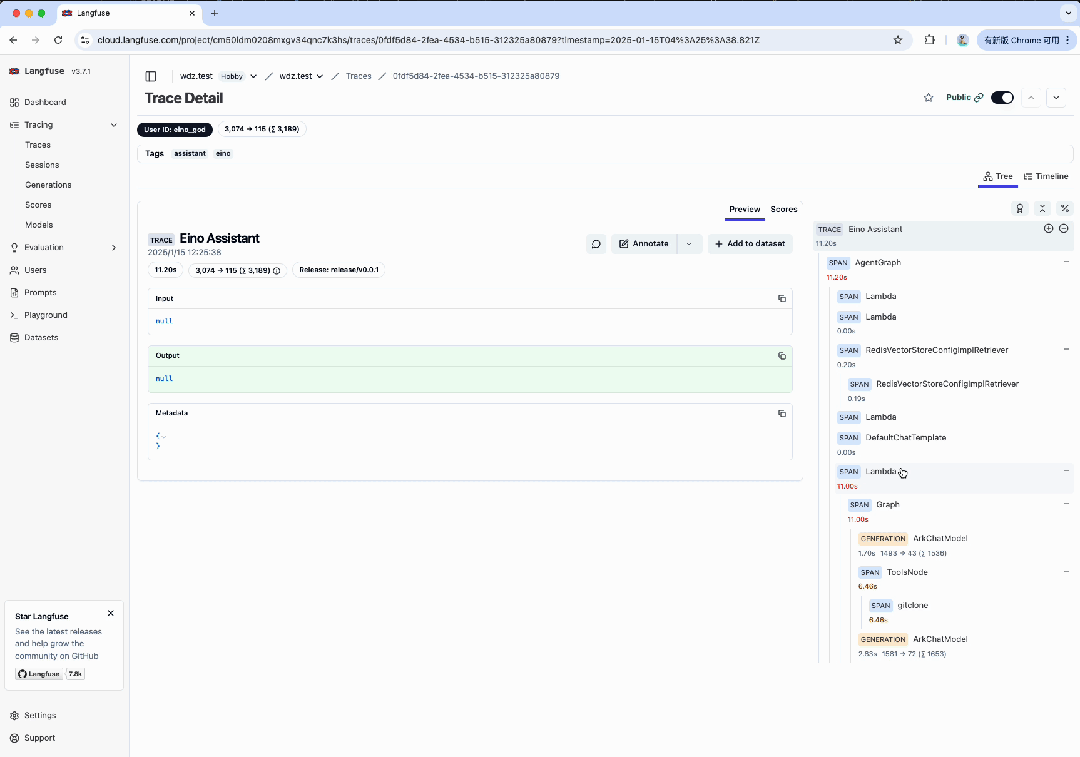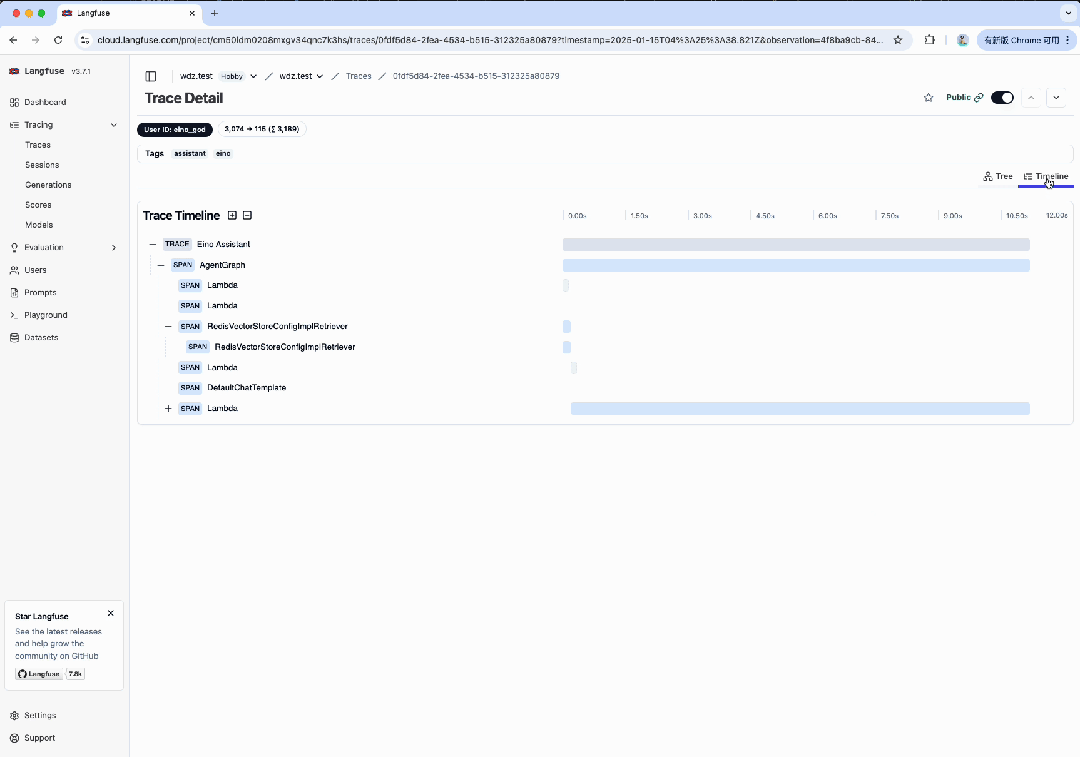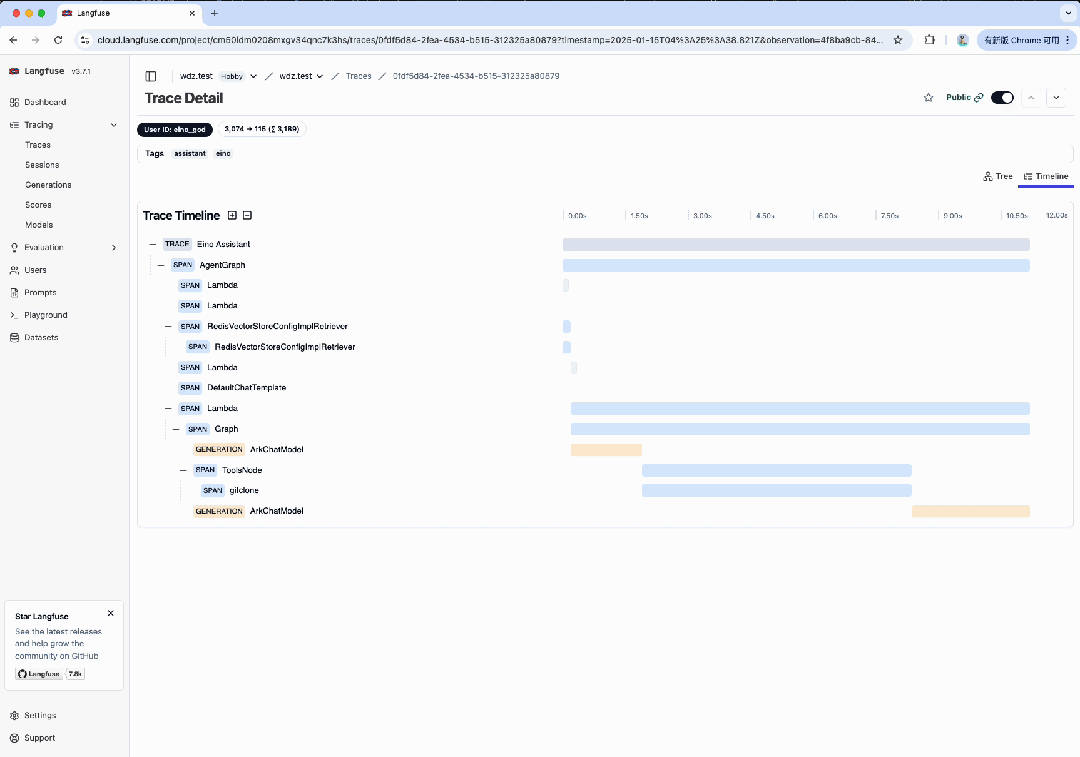
相关链接:
项目地址:https://github.com/cloudwego/eino,https://github.com/cloudwego/eino-ext
Eino 用户手册:https://www.cloudwego.io/zh/docs/eino/
项目官网:https://www.cloudwego.io
文章来自微信公众号 “ 机器之心 ”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
