# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
还记得半年前在 X 上引起热议的肖像音频驱动技术 Loopy 吗?升级版技术方案来了,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman, 其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。
如对下面图片和音频:

OmniHuman 生成的人物可以在视频中自然运动:

从项目主页上可以看到 OmniHuman 对肖像、半身以及全身这些不同人物占比、不同图片尺寸的输入都可以通过单个模型进行支持,人物可以在视频中生成和音频匹配的动作,包括演讲、唱歌、乐器演奏以及移动。对于人物视频生成中常见的手势崩坏,也相比现有的方法有显著的改善。


作者也展示模型对非真人图片输入的支持,可以看到对动漫、3D 卡通的支持也很不错,能保持特定风格原有的运动模式。据悉,该技术方案已落地即梦 AI,相关功能将于近期开启测试。



更多细节和展示效果,请查看:
https://arxiv.org/abs/2502.01061
研究问题
基于扩散 Transformer(DiT)的视频生成模型通过海量视频 - 文本数据训练,已能输出逼真的通用视频内容。其核心优势在于从大规模数据中学习到的强大通用知识,使模型在推理时展现出优异的泛化能力。在细分的人像动画领域,现有技术主要聚焦两类任务:音频驱动的面部生成(如语音口型同步)和姿势驱动的身体运动合成(如舞蹈动作生成)。2023 年后端到端训练方案的突破,使得现有技术方案通常能够对具有固定尺寸和人像比例的输入图像生成动画,实现精准的口型同步与微表情捕捉。
然而,技术瓶颈日益凸显:当前模型依赖高度过滤的训练数据(如固定构图、纯语音片段),虽保障了训练稳定性,却引发 "温室效应"— 模型仅在受限场景(如固定构图、真人形象)中表现良好,难以适应不同画面比例、多样化风格等复杂输入。更严重的是,现有数据清洗机制在排除干扰因素时,往往也丢失了大量有价值的数据,导致生成效果自然度低、质量差。
这种困境导致技术路线陷入两难:直接扩大数据规模会因训练目标模糊(如音频信号与肢体运动的弱相关性)导致模型性能下降;而维持严格筛选策略又难以突破场景限制。如何既能保留有效运动模式学习,又能从大数据规模学习中受益成为当前研究重点。
技术方案
据技术报告,OmniHuman,面向端到端人像驱动任务中高质量数据稀缺的问题,采用了一种 Omni-Conditions Training 的混合多模态训练策略,并相应的设计了一个 OmniHuman 模型,通过这种混合多模态训练的设计,可以将多种模态的数据一起加入模型进行训练,从而大幅度的增加了人像驱动模型的可训练数据,使得模型可以从大规模数据中受益,对各种类似的输入形式有了比较好的支持。
Omni-Conditions Training. 在模型训练过程中,作者将多种模态按照和运动的相关性进行区分,依序进行混合条件训练。这个多模态训练遵循两个原则:
原则 1: 较强条件的任务可以利用较弱条件的任务及其数据来扩展训练数据规模。例如,由于口型同步准确性、姿态可见性和稳定性等过滤标准,音频和姿态条件任务中排除的数据可以用于文本和图像条件任务。因此,在早期阶段舍弃音频和姿态条件,在后期逐步加入。
原则 2: 条件越强,训练比例应越低。较强的运动相关条件(如姿态)由于歧义较少,训练效果通常优于较弱的条件(如音频)。当两种条件同时存在时,模型倾向于依赖较强条件进行运动生成,导致较弱条件无法有效学习。因此,需要确保较弱条件的训练比例高于较强条件。
基于以上原则设计他们构建了多个阶段的训练过程,依次增加文本、图像、音频以及姿态模态参与模型训练,并降低对应的训练占比。

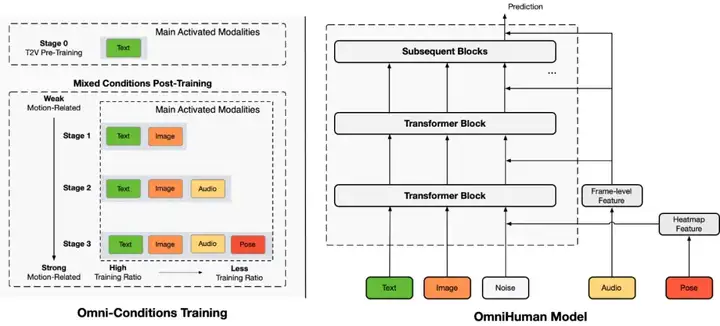
OmniHuman 技术框架图
Omni-Conditions Model. 除了 Omni-Conditions Training 训练策略以外,OmniHuman 采用了基于 DiT 架构的视频生成框架,使得模型兼容多种模态的条件注入方式,包括文本、图像、音频和姿态,多模态的条件被区分为两类:驱动条件和外观条件。
对于驱动条件,作者对音频特征通过 cross attention 实现条件注入,对于姿态特征通过 Heatmap 特征编码后和 Noise 特征进行拼接实现条件注入,对于文本特征,则保持了 MMDiT 的条件注入方式。
对于外观条件,作者没有像现有工作一样采用一个单独的参考图网络 (Reference Net),而是直接利用去噪声网络 (Denoising Net) 对输入图像进行特征编码,复用了 backbone 的特征提取方式,参考图特征会和 Noise 特征进行拼接实现条件注入
效果对比
作者给出了和目前行业领先的方案的效果对比,通过单个模型同时对比了针对不同人物占比的专有模型,仍然可以取得显著的整体效果优势。
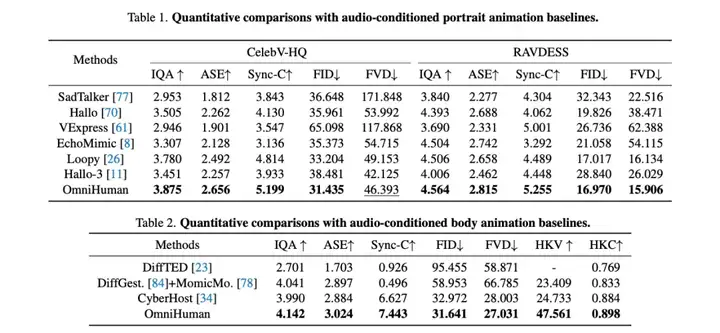
除了数值分析以外,作者也分析基于 Omni-Conditions Training 可以改善在人体手势生成、多样性输入图像上的视频生成效果,并展示了混合多模态训练可以使得单个模型同时兼容多种模态驱动,生成可控的生动人像视频的例子。
结论
OmniHuman 是一个端到端的多模态条件人像视频生成框架,能够基于单张图像和运动信号(如音频、视频或两者)生成人像动画视频。它提出了一个多模态混合训练的技术方案,并调研了具体的训练策略,设计了相应的多模态混合控制的人像视频生成模型,从而克服了以往方法面临的高质量数据稀缺问题,从大规模数据训练中受益,学习自然的运动模式。OmniHuman 显著优于现有方法,能够从弱信号(尤其是音频)生成生动的人类视频。它支持任意纵横比的图像(如肖像、半身或全身),在各种场景下提供生动、高质量的结果。
团队介绍
字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术中台,通过建设领先的计算机视觉、音视频编辑、特效处理等技术,支持抖音、剪映、头条等公司内众多产品线;同时为外部 ToB 合作伙伴提供业界最前沿的智能创作能力与行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。
文章来自于微信公众号“机器之心”



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LivePortrait项目可以实现高效的人像动画,通过拼接和重定向控制技术,使一个静态人像或动物图像能够变成动态的视频,变成动画形式。
项目地址:https://github.com/KwaiVGI/LivePortrait?tab=readme-ov-file
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
