# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

就在刚刚,OpenAI首席科学家Ilya领衔的超级对齐团队,发布了成立以来的首篇论文!
团队声称,已经发现了对超人类模型进行实证对齐的新研究方向。
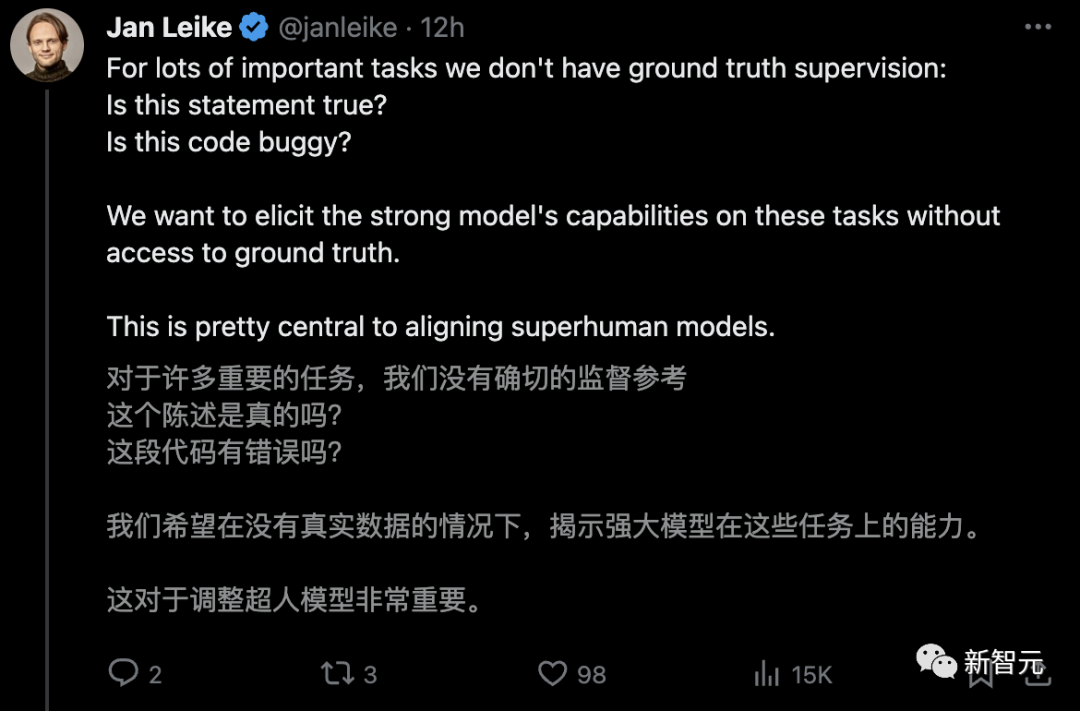
未来超级AI系统对齐的一个核心挑战——人类需要监督比自己更聪明人工智能系统。
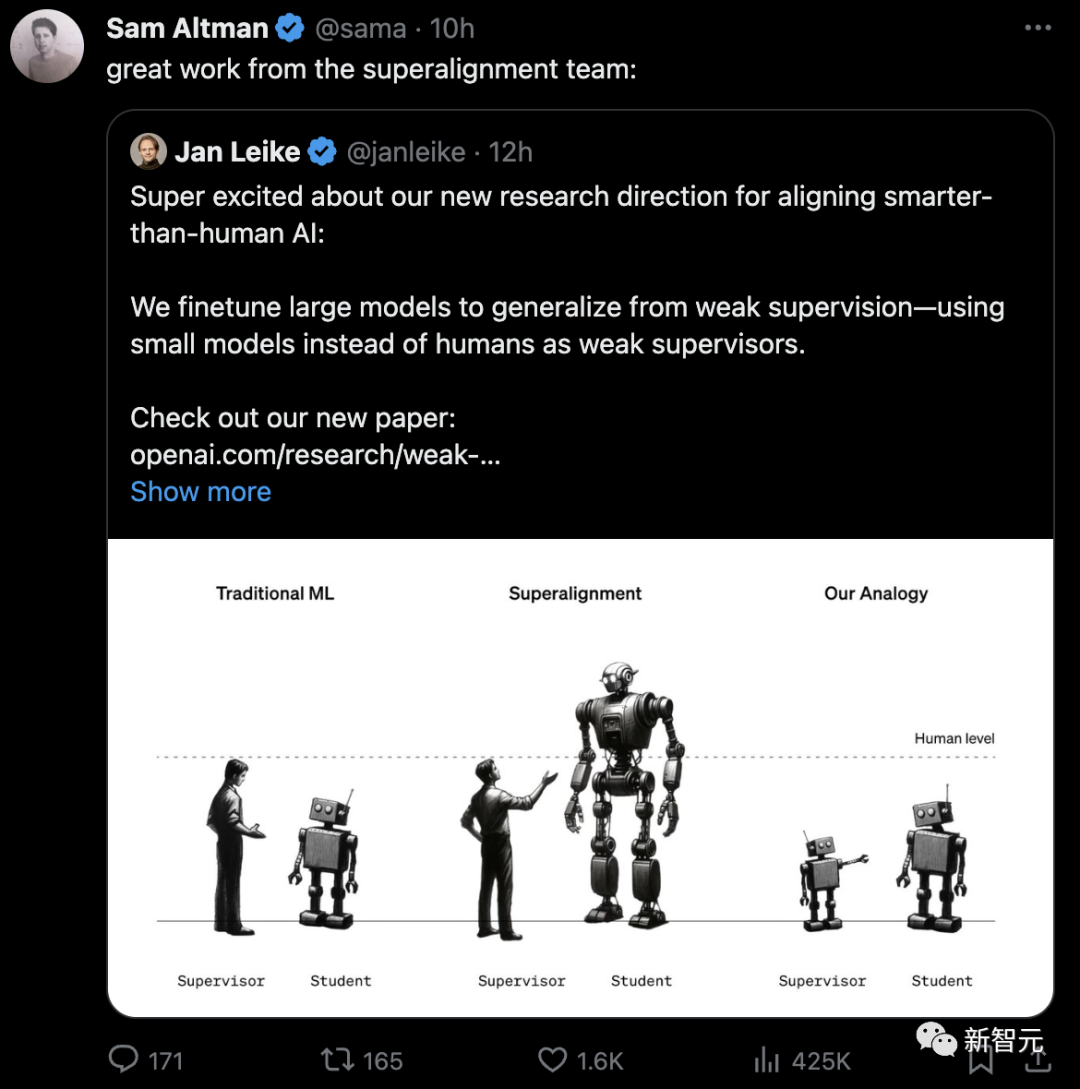
OpenAI的最新研究做了一个简单的类比:小模型可以监督大模型吗?

论文地址:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
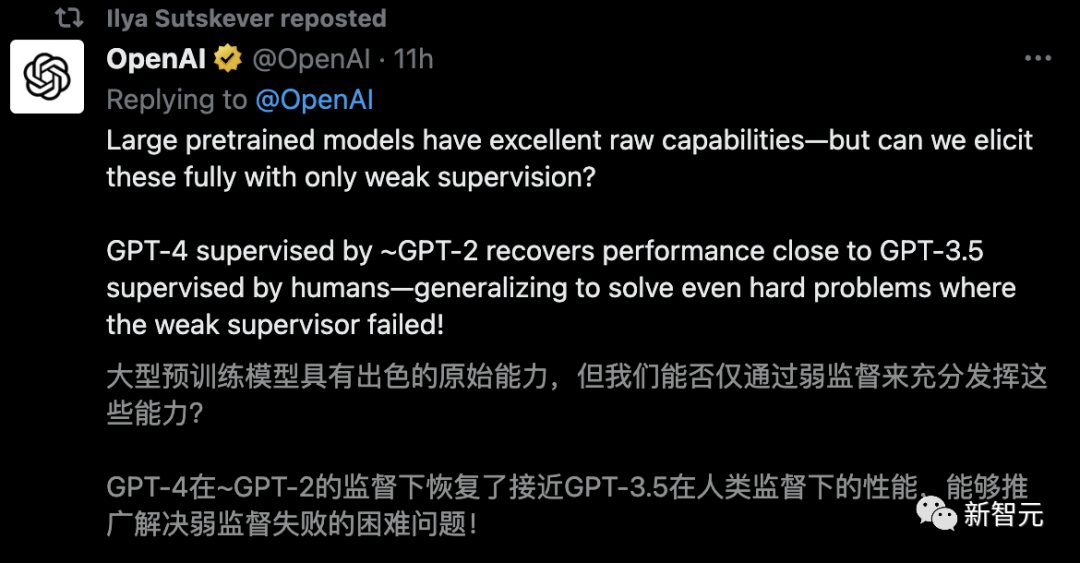
经验证,通过GPT-2可以激发出GPT-4的大部分能力(接近GPT-3.5的性能),甚至可以正确地泛化到小模型失败的难题上。
OpenAI此举开辟了一个新的研究方向,让我们能够直接解决一个核心挑战,即调整未来的超级AI模型,同时在迭代的实证中取得进展。
为了便于大家理解,超级对齐共同负责人Jan Leike,也发表了对这项研究的简要概括:

OpenAI认为,超级智能(比人类聪明得多的人工智能),很可能在未来十年内出现。
然而,人类却仍然不知道,该如何可靠地引导和控制超人AI系统。
这个问题,对于确保未来最先进的AI系统安全且造福人类,是至关重要的。
解决这个问题对于确保未来最先进的人工智能系统仍然安全并造福人类至关重要。

为此,今年7月OpenAI成立了「超级对齐团队」,来解决这类超级智能的对齐难题。
5个月后,团队发表第一篇论文,介绍了实证对齐超人模型的新研究方向。
当前的对齐方法,例如基于人类反馈的强化学习 (RLHF),非常依赖于人类的监督。
但未来的人工智能系统,显然能够做出极其复杂且极具创造性的行为,而这将使人类很难对其进行可靠的监督。
比如,超人模型写出了数百万行新颖的且具有潜在危险的计算机代码,即便是专业人士也难以完全理解,这时人类该怎么办呢?
可见,相比于超人的AI模型,人类将成为一个「弱监督者」。
而这正是AGI对齐的核心挑战——「弱小」的人类,如何信任并控制比他们更智能的AI系统?
为了在这个核心挑战上取得进展,OpenAI提出了一可以实证研究的类比:能否用一个更小(能力较弱)的模型来监督一个更大(能力更强)的模型?

超级对齐的简单类比:在传统的ML中,人类监督的人工智能系统比自己弱(左)。为了对齐超级智能,人类将需要监督比他们更聪明的人工智能系统(中)。我们今天无法直接研究这个问题,但我们可以研究一个简单的类比:小模型能否监督大模型(右图)?
我们可能会天真的认为,一个强大的模型不会比提供训练信号的弱监督表现得更好。它可能只是学会模仿弱监督所犯的所有错误。
另一方面,强大的预训练模型具有出色的原始能力——不需要从头开始教它们新任务,只需要引出其潜在知识。
那么关键的问题是:强模型是否会根据弱监督的潜在意图进行泛化,利用其全部能力来解决任务,即使是在弱监督只能提供不完整或有缺陷的训练标签的难题上?
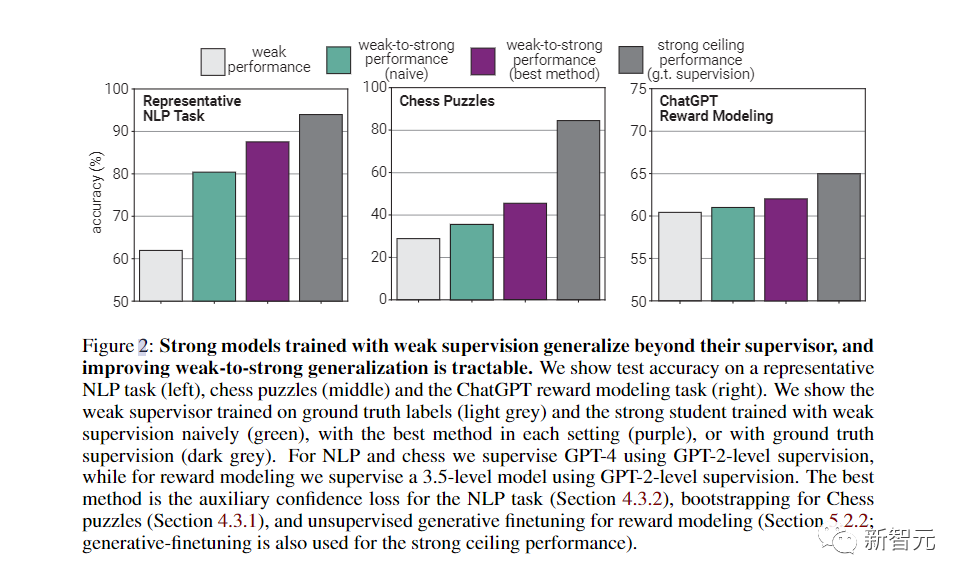
对此,团队使用了NLP基准测试的典型弱到强泛化——用GPT-2级别的模型作为弱监督,来微调GPT-4。
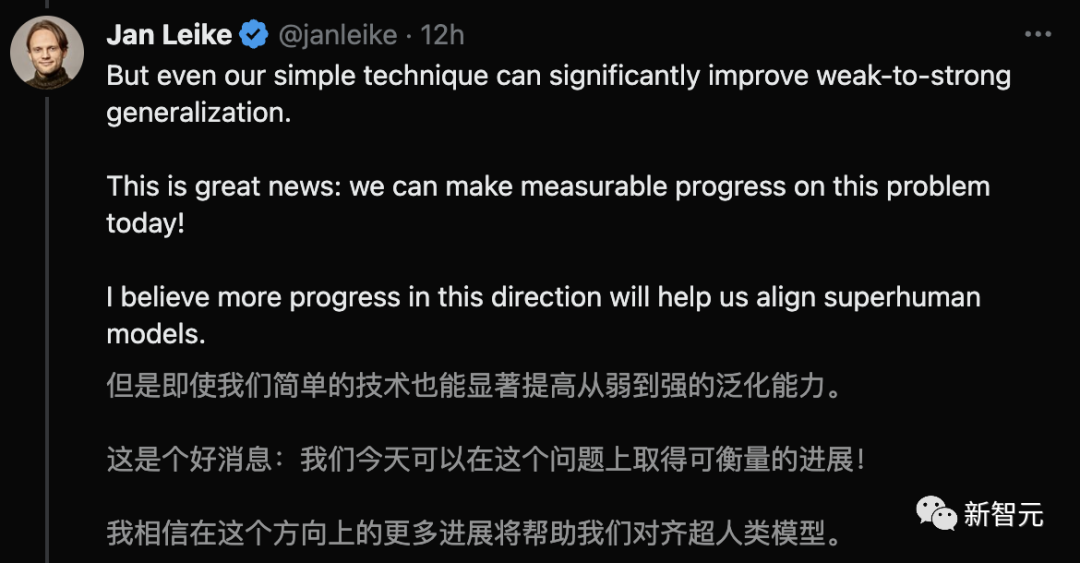
在很多情况下,这种方法都能显著提高泛化能力。
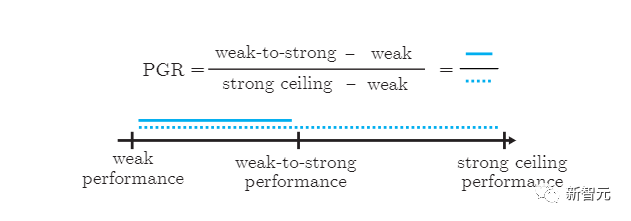
使用一种简单的方法,就鼓励性能更强的模型更加自信,包括在必要时自信地说出与弱监督意见不同的意见。
在NLP任务上使用这种方法用GPT-2级模型监督GPT-4时,生成的模型通常在GPT-3和GPT-3.5之间。
而在更弱的监督下,就可以恢复GPT-4的大部分功能。
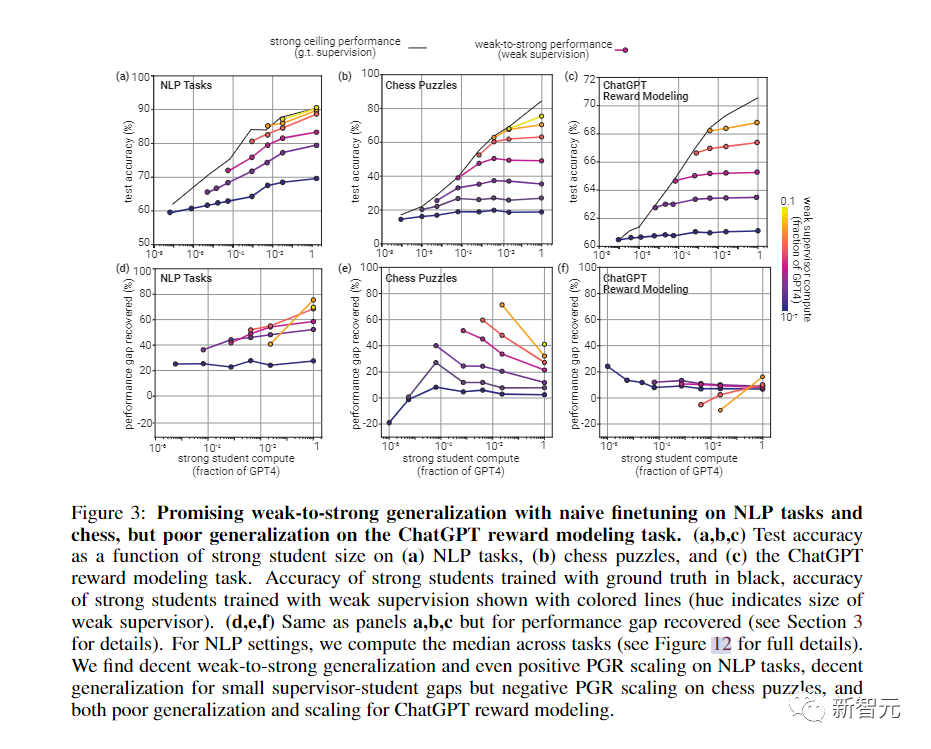
当然,这种方法更像是概念证明,具有很多局限性,比如,它并不适用于ChatGPT偏好数据。
不过,团队也发现了其他方法,比如最佳的早期停止和从小型到中型再到大型模型的引导。
总的来说,结果表明,(1)幼稚的人类监督(比如RLHF)可以在没有进一步工作的情况下。很好地扩展到超人模型,但(2)大幅改善弱到强的泛化是可行的。
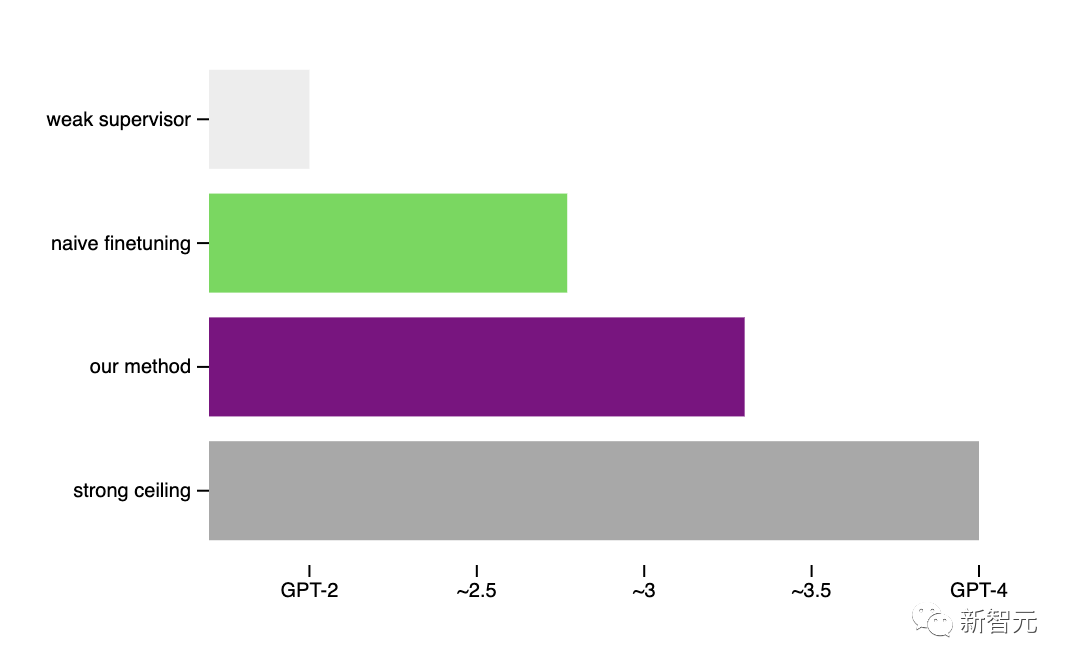
OpenAI目前的经验设置与对齐超级模型的终极问题之间,仍然存在重要的差异。
比如,未来的模型可能比当前强模型,模仿当前的弱模型错误更容易,这可能会使未来的泛化更加困难。
尽管如此,OpenAI团队相信实验设置,抓住了对齐未来超级模型的一些关键难点,使OpenAI能够在这个问题上取得可以验证的进展。

同时,他们还透露了未来工作方向,包括修正设置,开发更好的可扩展方法,以及推进对何时以及如何获得良好的「弱到强」泛化的科学理解。
OpenAI表示,他们正在开源代码,让机器学习社区研究人员立即轻松开始从弱到强的泛化实验。

这次,OpenAI还与Eric Schmidt合作,启动了一个价值1000万美元的资助计划,支持确保超人类AI系统对齐并安全的技术研究:

- OpenAI为学术实验室、非营利组织和个人研究人员提供10万至200万美元的资助。
- 对于研究生,OpenAI设立了为期一年、总额为15万美元的OpenAI Superalignment奖学金,包括7.5万美元的津贴和7.5万美元的计算及研究资金。
- 申请者无需有对齐工作经验;OpenAI会特别支持首次从事对齐研究的研究人员。
- 申请过程简洁高效,具体回复将会在申请截止后的四周内给出。
OpenAI尤其关注以下几个研究方向:
- 弱到强的泛化:面对超人类模型,人类将是相对弱势的监督者。人类能否理解并控制强大模型是如何从弱监督中学习和泛化的?
- 可解释性:人类如何理解模型的内部工作原理?人类能否利用这种理解来开发像AI谎言检测器这类的工具来帮助人类?
- 可扩展的监督:人类如何利用AI系统帮助人类评估其他AI系统在复杂任务上的表现?
- 还有包括但不限于以下方向的多个研究领域:诚实度、思维链的诚实度、对抗鲁棒性(adversarial robustness)、评估和测试平台等等方向。
参考资料:
https://openai.com/research/weak-to-strong-generalization
https://openai.com/blog/superalignment-fast-grants
文章来自于微信公众号 “新智元”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
