# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天,一篇多机构联合发表的论文,在AI圈引起轰动。
凭借重新思考计算最优的测试时Scaling,1B模型竟然超越了405B?
随着OpenAI o1证明了测试时扩展(TTS)可以通过在推理时分配额外算力,大幅增强LLM的推理能力。测试时计算,也成为了当前提升大模型性能的最新范式。
那么,问题来了:
2.扩展计算在多大程度上可以提高大语言模型在复杂任务上的表现,较小的语言模型能否通过这种方法实现对大型模型的超越?
对此,来自清华、哈工大、北邮等机构的研究人员发现,使用计算最优TTS策略,极小的策略模型也可以超越更大的模型——
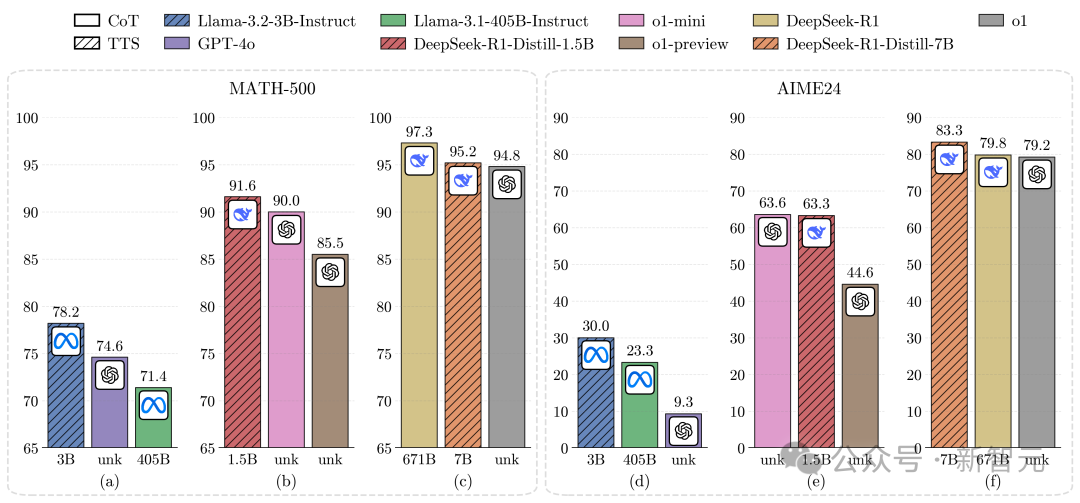
在MATH-500和AIME24上,0.5B模型的表现优于GPT-4o;3B模型超越了405B模型;7B模型直接胜过o1和DeepSeek-R1,还具有更高的推理性能。

论文地址:https://arxiv.org/abs/2502.06703
这就表明,TTS是增强LLM推理能力的一种极有前途的方法。
同时,这也体现了研究真正的「弱到强」方法,而非当前的「强到弱」监督,对策略优化的重要性。
重新思考「计算最优」的测试时Scaling
计算最优的测试时Scaling,旨在为每个问题分配最优计算资源。
根据此前的研究,一种方法是使用单一的PRM作为验证器在策略模型的响应上训练PRM并将其用作验证器,以对同一策略模型进行TTS;另一种方法则是使用在不同策略模型上训练的PRM来进行TTS。
从强化学习(RL)的角度来看,前者获得的是在线PRM,后者则是离线PRM。
在线PRM能为策略模型的响应产生更准确的奖励,而离线PRM由于分布外(OOD)问题往往会产生不准确的奖励。
对于计算最优TTS的实际应用而言,为每个策略模型训练一个用于防止OOD问题的PRM在计算上是昂贵的。
因此,研究人员在更一般的设置下研究计算最优的TTS策略,即PRM可能是在与用于TTS的策略模型不同的模型上训练的。
对于基于搜索的方法,PRM指导每个响应步骤的选择,而对于基于采样的方法,PRM在生成后评估响应。
这表明:(1)奖励影响所有方法的响应选择;(2)对于基于搜索的方法,奖励还会影响搜索过程。
为分析这些要点,团队使用Llama-3.1-8BInstruct作为策略模型,RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B作为PRM,进行了一项初步的案例研究。

奖励会显著影响生成的过程和结果
RLHFlow-PRM-Mistral-8B对短响应给予高奖励,却产生了错误的答案;而使用RLHFlow-Deepseek-PRM-8B进行搜索虽然产生正确答案,但使用了更多token。
基于以上发现,研究人员提出奖励应该被整合到计算最优的TTS策略中。将奖励函数表示为ℛ,奖励感知计算最优TTS策略表述如下:
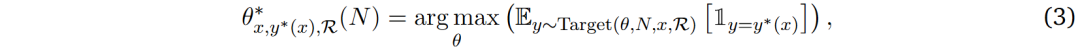
其中Target(𝜃, 𝑁, 𝑥, ℛ)表示在计算预算𝑁和提示词𝑥条件下,由奖励函数ℛ调整的策略模型𝜃输出分布。对于基于采样的扩展方法,Target(𝜃, 𝑁, 𝑥, ℛ) =Target(𝜃,𝑁,𝑥)。
这种奖励感知策略确保计算最优扩展能够适应策略模型、提示词和奖励函数,从而为实际的TTS提供了一个更具普适性的框架。
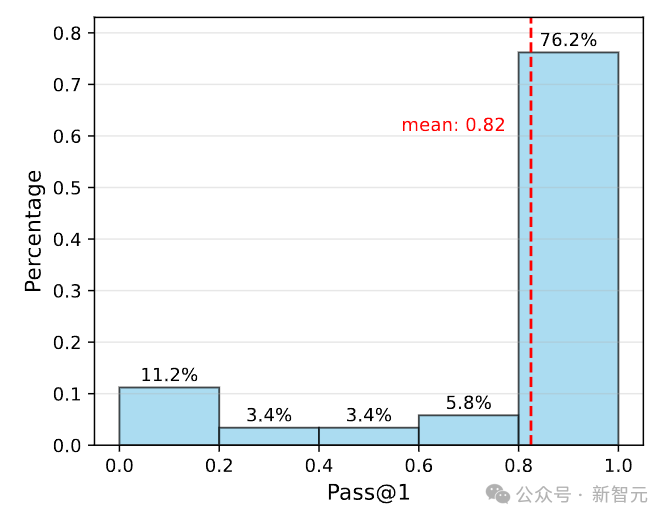
团队发现,使用来自MATH的难度等级或基于Pass@1准确率分位数的oracle标签并不有效,这是因为不同的策略模型存在不同的推理能力。
如下图所示,Qwen2.5-72B-Instruct在76.2%的MATH-500问题上实现了超过80%的Pass@1准确率。
因此,团队选择使用绝对阈值,而不是分位数来衡量问题难度。即基于Pass@1准确率,定义三个难度等级:简单(50%~100%)、中等(10%~50%)和困难(0%~10%)。
如何最优地Scaling测试时计算?
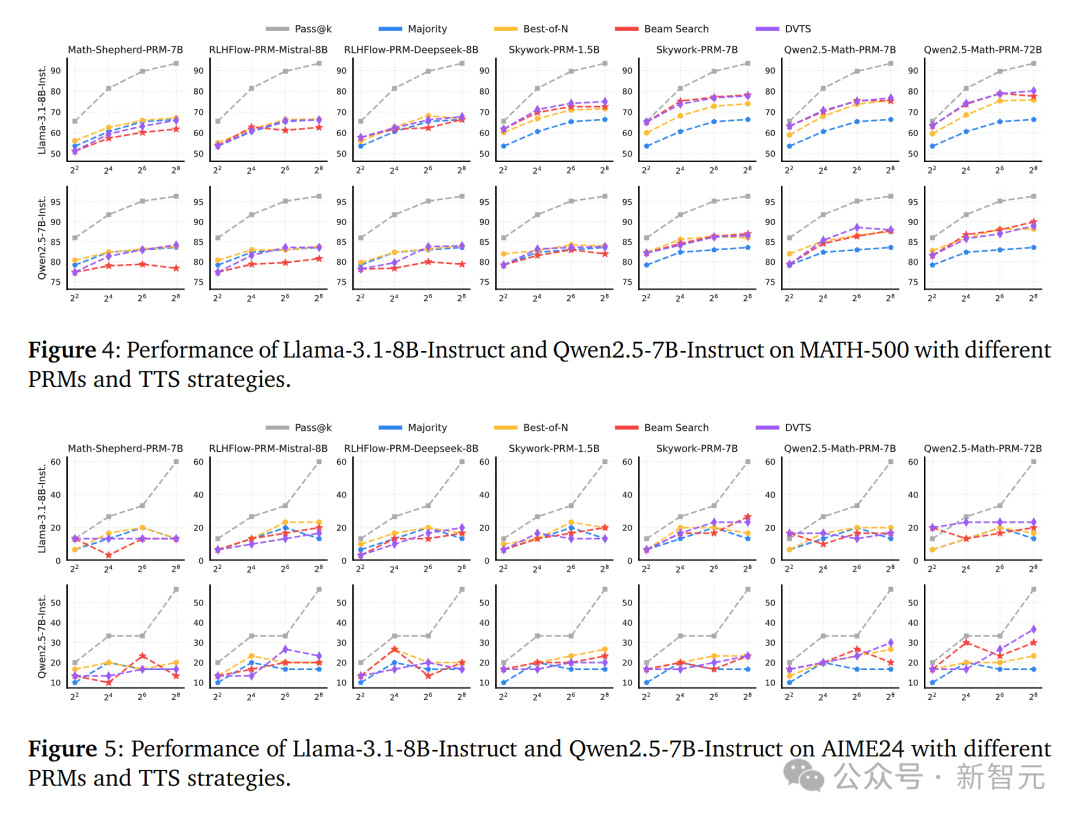
对于Llama-3.1-8B-Instruct模型,研究团队使用Skywork和Qwen2.5-Math PRM的搜索方法在计算预算增加时性能显著提升,而使用Math-Shepherd和RLHFlow PR的搜索方法则效果较差。
对于Qwen2.5-7B-Instruct模型,使用Skywork-PRM-7B和Qwen2.5-Math PRM的搜索方法性能随计算预算增加而提升,而使用其他的PRM性能仍然较差。
在AIME24数据集上,虽然两个策略模型的Pass@k准确率随着计算预算的增加而提高,但TTS的性能改进仍然有限。
这表明PRM在不同策略模型和任务间的泛化能力是一个挑战,尤其是在更复杂的任务上。
研究团队发现当使用Math-Shepherd和RLHFlow PRM时,Best-of-N (BoN) 方法通常优于其他策略。
而当使用Skywork和Qwen2.5-Math PRM时,基于搜索的方法表现更好。
这种差异可能源于PRM在处理OOD(超出分布)策略响应时效果不佳,因为PRM在不同策略模型间的泛化能力有限。
使用OOD PRM进行每一步的选择时可能会导致答案陷入局部最优,从而降低性能。
不过,PRM的基础模型也可能是一个影响因素,例如,使用Qwen2.5-Math-7B-Instruct训练的PRM比使用Mistral和Llama作为基础模型的PRM泛化能力更好。
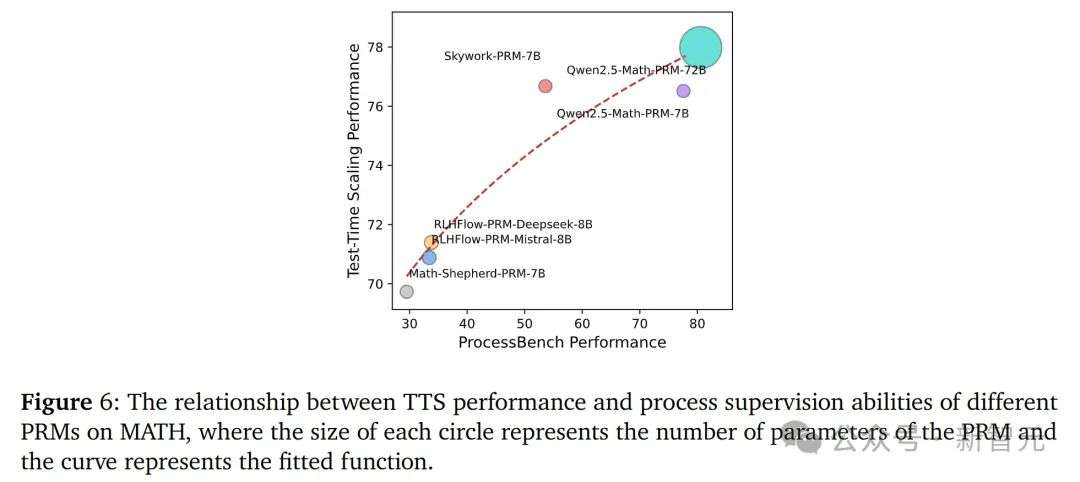
下图4和5说明了PRM的选择对于TTS的效果至关重要,并且最佳的TTS策略会随着使用的PRM的不同而改变,同时验证了PRM在不同策略模型和数据集之间的泛化
能力也是一个挑战。
研究团队发现,TTS的性能与PRM的过程监督能力之间存在正相关。具体来说,PRM的过程监督能力越强,其在TTS中通常能带来更好的性能。
团队拟合了一个函数来描述这种关系,结果说明了 PRM 的过程监督能力对TTS性能的重要性。
下图6表明,PRM的过程监督能力是决定其在TTS中性能的关键因素。这为开发更有效的PRM提供了方向:应该注重提高PRM的过程监督能力,而不仅仅是增加参数
量。
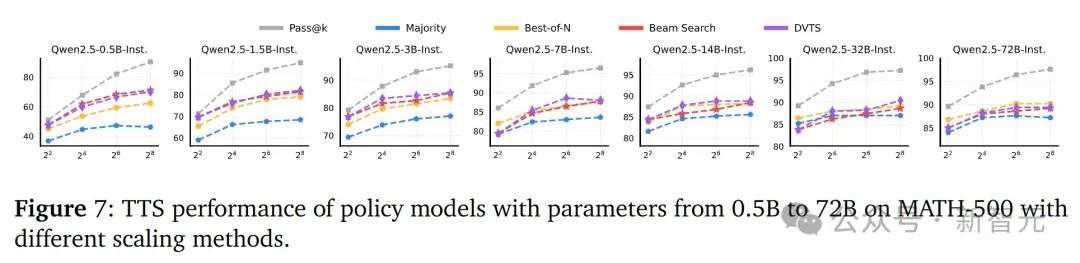
为了得到最优的TTS方法,研究中使用了Qwen2.5系列的不同大小LLM(从0.5B到72B)进行实验。
结果显示,对于小型策略模型,基于搜索的方法优于BoN3。而对于大型策略模型,BoN比基于搜索的方法更有效。
这可能是因为大型模型具有更强的推理能力,不需要验证器逐步选择。而小型模型则依赖于验证器来选择每一步,以确保中间步骤的正确性。
下图7表明最优的TTS方法依赖于策略模型的大小,在选择TTS方法时需要考虑模型的推理能力。
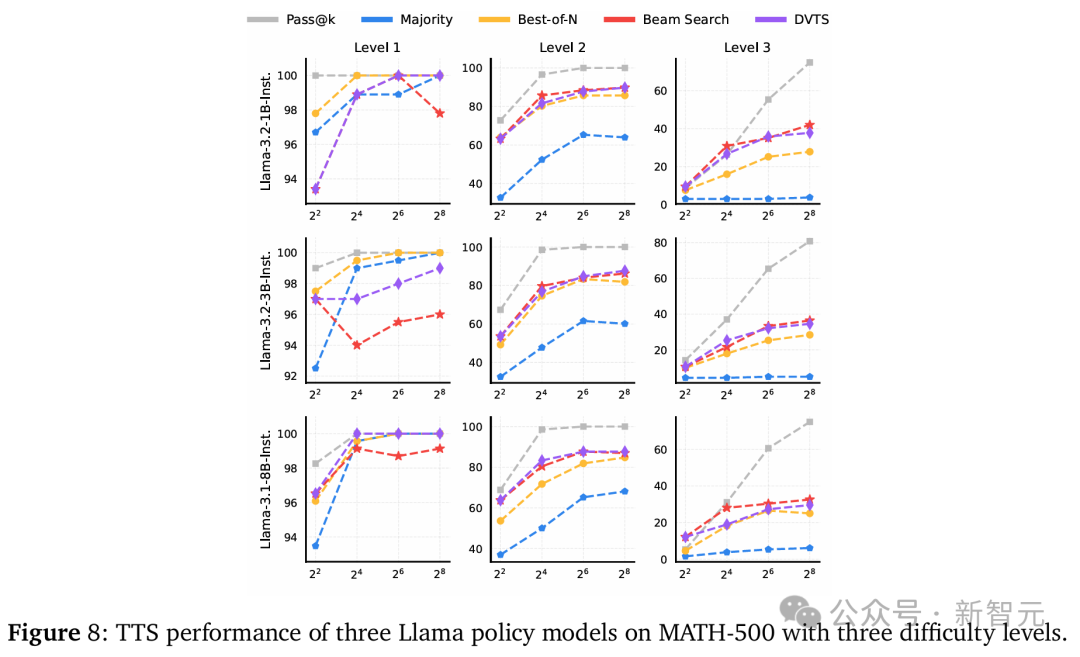
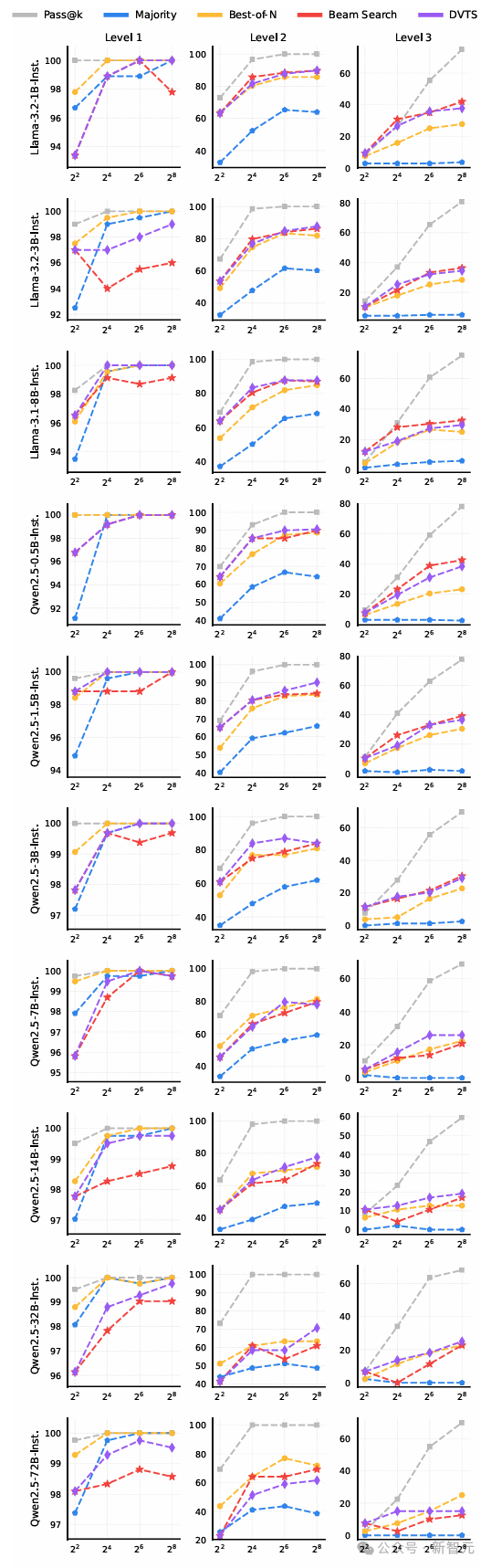
如前所述,团队基于Pass@1准确率的绝对值将难度级别分为三组:简单(50%~100%)、中等(10%~50%)和困难(0%~10%)。
最优的TTS方法随难度级别的不同而变化,结果如下图所示。
研究团队发现,即使在实验中使用相同的计算预算进行TTS,使用不同PRM在推理中产生的token数量差异显著。
例如,在相同预算和相同策略模型的情况下,使用RLHFlow-PRM-Deepseek-8B进行扩展的推理token数量始终比使用RLHFlow-PRM-Mistral-8B多近2倍。
这种差异与 PRM 的训练数据有关。RLHFlow系列PRM的训练数据来自不同的大语言模型,这可能导致它对输出长度产生偏差。
为了验证这一观点,研究团队分析了RLHFlow-PRM-Mistral-8B3和RLHFlow-PRM-Deepseek-8B4训练数据的几个特性。
如表1所示,DeepSeek-PRM-Data的每个响应平均token数和每个步骤平均token数都大于Mistral-PRM-Data,这表明RLHFlow-PRM-Deepseek-8B的训练数据比
RLHFlow-PRM-Mistral-8B的更长。这可能导致对输出长度的偏差。
研究团队还发现,使用Qwen2.5-Math-7B进行扩展的推理token数量大于使用Skywork-PRM-7B的数量,但性能非常接近,这表明使用Skywork-PRM-7B进行搜索更
有效率。

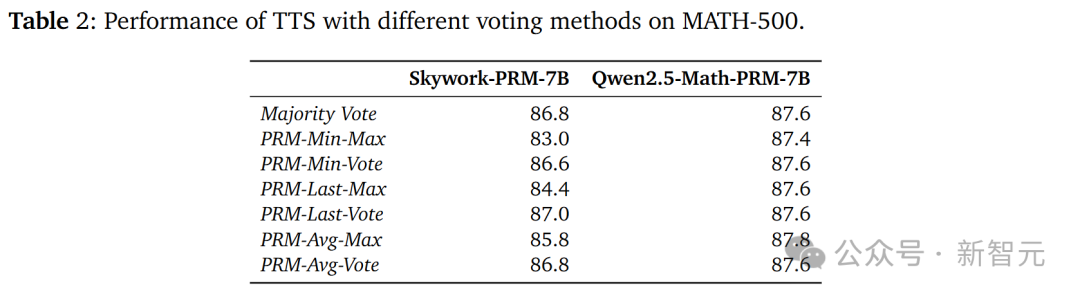
从表2的结果可以看出,Skywork-PRM-7B使用PRM-Vote比使用PRM-Max效果更好,而Qwen2.5-Math-PRM-7B对投票方法不太敏感。
这主要是因为Qwen2.5-Math PRM的训练数据经过了LLM-as-a-judge(将大语言模型作为判断器)处理,该处理移除了训练数据中被标记为正样本的错误中间步骤,
使得输出的高奖励值更可能是正确的。
这表明PRM的训练数据对提升其在搜索过程中发现错误的能力具有重要意义。
「计算最优」的测试时Sclaing
在计算最优TTS策略下,研究人员就另外三大问题,进行了实验评估。
对小型策略模型进行测试时计算的扩展,对提升LLM的推理性能至关重要。
那么,较小的策略模型能否通过计算最优的TTS策略,超越更大的模型,如GPT-4o、o1、DeepSeek-R1?
如下表3所示,研究人员得出了4点关键的洞察:
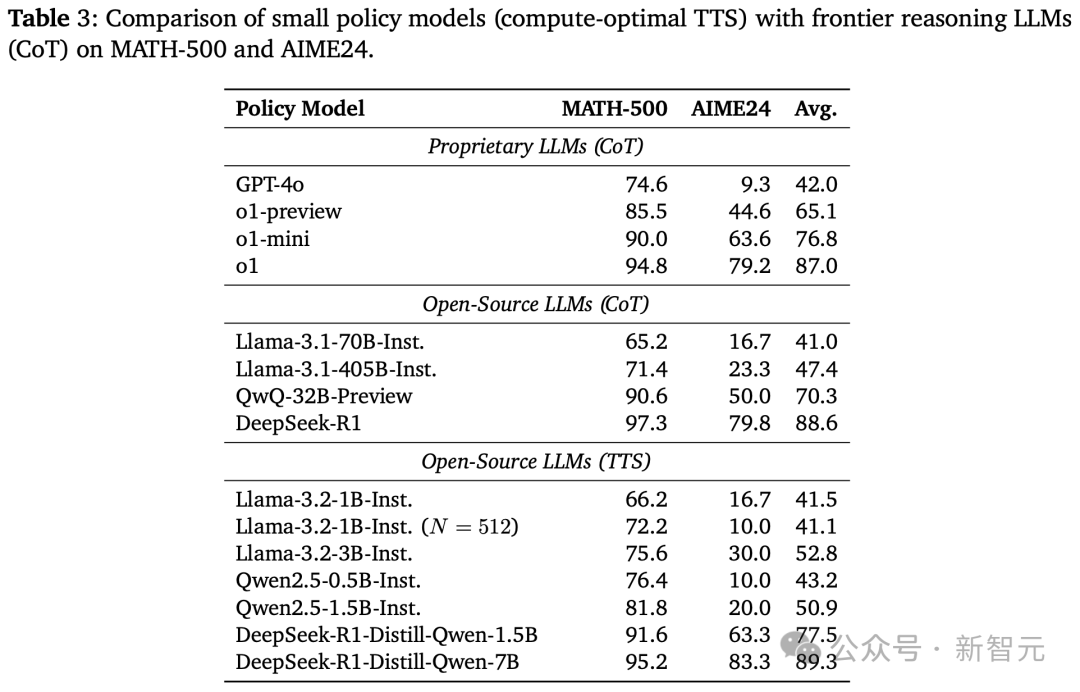
1. 采用计算最优TTS策略后,在两大数学基准MATH-500和AIME24上,Llama-3.2-3B-Instruct性能碾压Llama-3.1-405B-Instruct。
从这点可以看出,较小模型通过计算最优TTS策略,可超越大135倍的模型。
与此前谷歌Charlie Snell团队等TTS相关研究相比,新方法将结果提升了487.0%(23倍→135倍)。
2. 将计算预算增加到N=512,同样采用计算最优TTS的Llama-3.2-1B-Instruct,在MATH-500基准上击败了Llama-3.1-405B-Instruct。
奇怪的是,在AIME24上,它的性能又不如Llama-3.1-405B-Instruct。
3. 采用计算最优TTS,Qwen2.5-0.5B-Instruct、Llama-3.2-3B-Instruct均超越了GPT-4o。
这表明,小模型可以通过计算最优TTS策略,也能一举超越GPT级别的大模型。
4. 在同样策略和基准下,DeepSeek-R1-Distill-Qwen-1.5B竟能碾压o1-preview、o1-mini。
同时,DeepSeek-R1-Distill-Qwen-7B还能击败o1和DeepSeek-R1。
以上这些结果表明,经过推理增强的小模型可以,通过计算最优TTS策略超越前沿推理大模型。
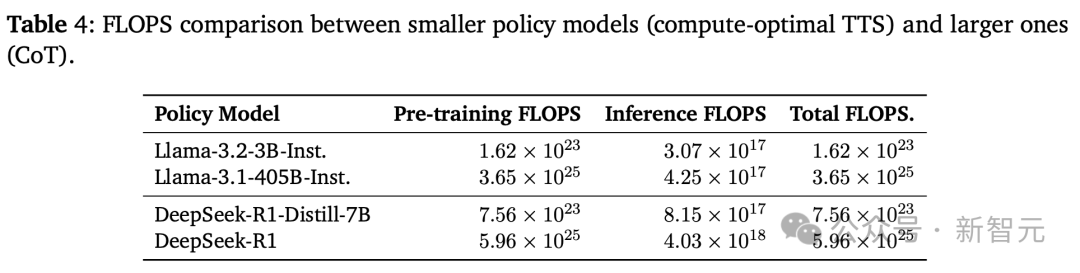
再来看下这些模型FLOPS比较,如下表4所示,小型策略模型即使在使用更少推理FLOPS的情况下,也能超越大型模型,并将总FLOPS减少了100-1000倍。
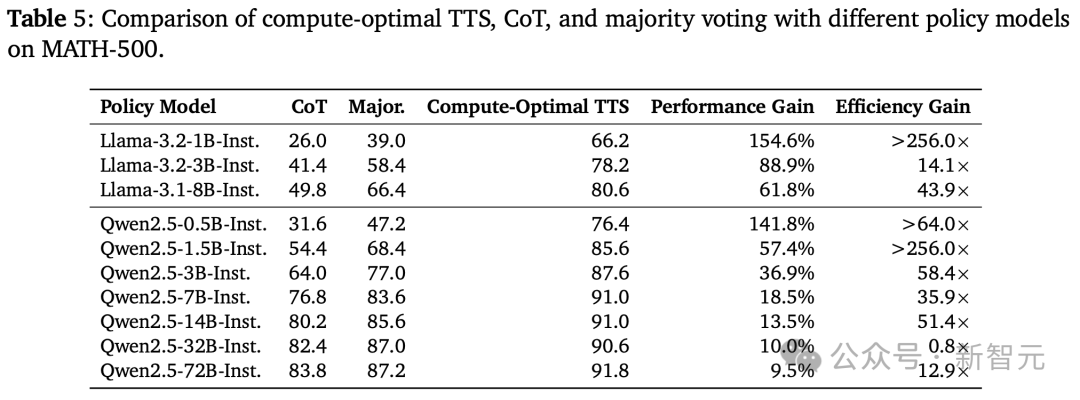
如下表5展示了,每个策略模型在MATH-500上的计算最优TTS结果。
结果发现,计算最优TTS的效率可以比多数投票高256倍,并且相比CoT提升了154.6%的推理性能。
这些结果表明,计算最优TTS显著增强了LLM的推理能力。
然而,随着策略模型参数数量的增加,TTS的改进效果逐渐减小。这表明,TTS的有效性与策略模型的推理能力直接相关。
具体来说,对于推理能力较弱的模型,Scaling测试时计算会带来显著改进;而对于推理能力较强的模型,提升效果则较为有限。
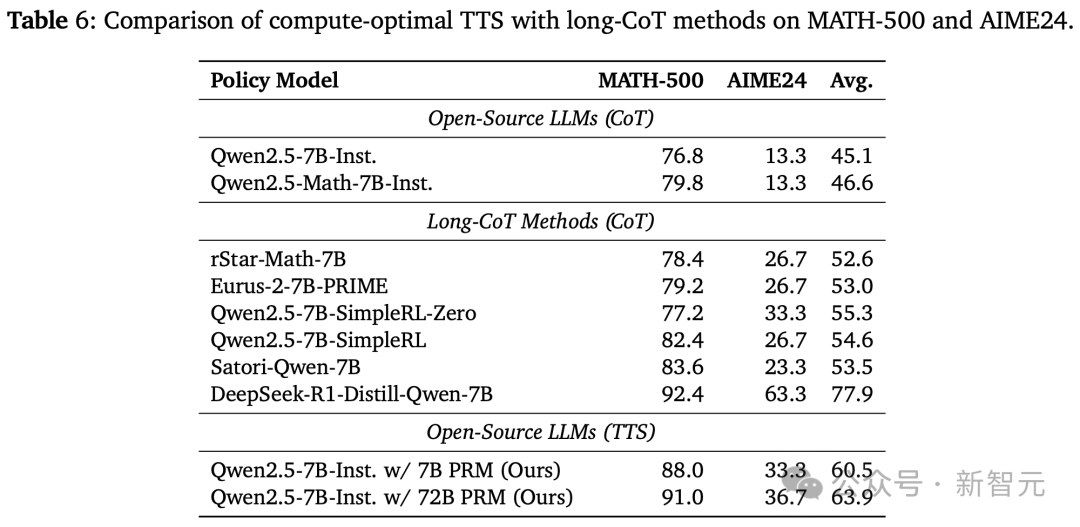
如下表6所示,研究人员发现,在MATH-500和AIME24基准上,使用Qwen2.5-7B-Instruct的TTS都优于rStar-Math、Eurus-2、SimpleRL和Satori。
然而,虽然TTS在MATH-500上的表现,接近DeepSeek-R1-Distill-Qwen-7B,但在AIME24上表现出明显下降。
这些结果表明,TTS比直接在MCTS生成数据上,应用RL或SFT的方法更有效,但不如从强大的推理模型中进行蒸馏的方法有效。
另外,TTS在较简单的任务上,比在更复杂的任务上更有效。
作者介绍
Runze Liu

Runze Liu是清华大学深圳国际研究生院的二年级硕士生,导师是Xiu Li教授。他曾于2023年6月获得山东大学的荣誉学士学位。
目前,他也在上海AI Lab大模型中心担任研究实习生,由Biqing Qi博士指导。
Runze Liu的研究重点是大模型和强化学习(RL)。目前,他对提高大模型的推理和泛化能力特别感兴趣,同时也在探索将大模型整合以增强RL算法的潜力,特别是
在人类/AI反馈强化学习(RLHF/RLAIF)情况下。
参考资料:
https://arxiv.org/abs/2502.06703
https://ryanliu112.github.io/compute-optimal-tts/
文章来自于 微信公众号“新智元”,作者 HNYZ




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
