# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,昆仑万维正式发布了一款全新自研的Matrix-Zero世界模型。
Matrix-Zero世界模型包含两款子模型:昆仑万维自研的3D场景生成大模型与昆仑万维自研的可交互视频生成大模型。包括两部分功能:
至此,昆仑万维正式成为中国第一家同时推出3D场景生成、可交互视频生成模型的探索空间智能的企业。

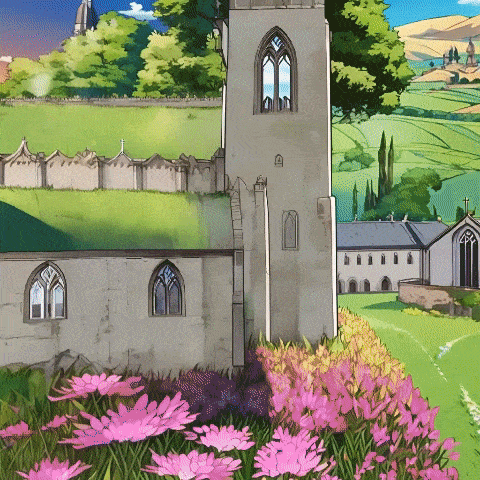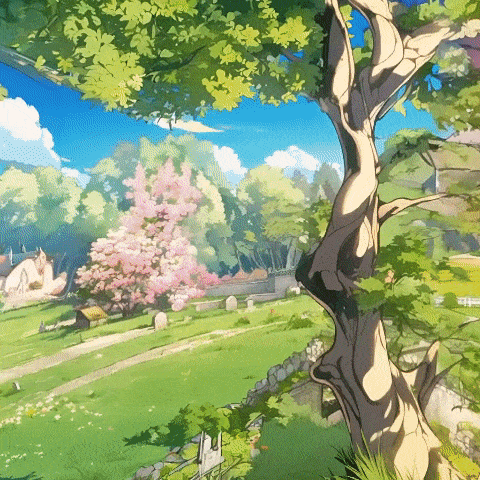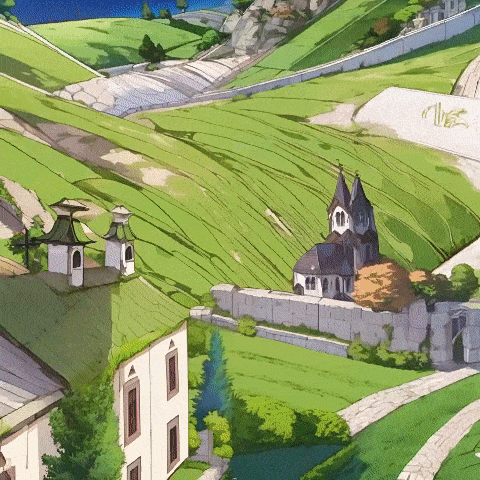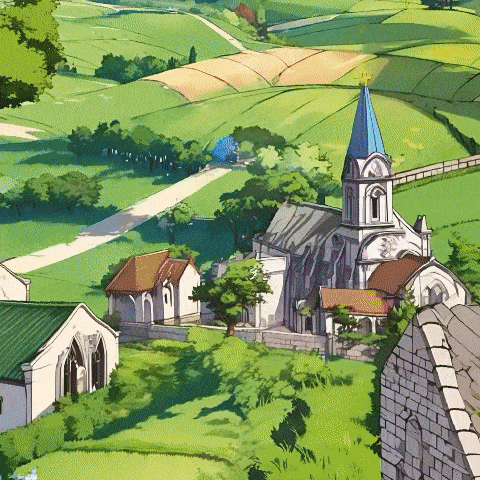
大模型赛道卷了两年,谁都在观望,下一个破局的方向在何方。
李飞飞躬身入局,仅3个月就估值10亿的World Labs令业内恍然大悟:AI教母瞄准的,就是能进行推理的空间智能!
2024年12月3日,World Labs的首个成果——一张单个图像即可生成3D图像的世界模型,立刻技惊四座。
紧接着,谷歌DeepMind也在2024年12月5日发布了基础世界模型Genie 2,单图就能生成1分钟的游戏世界。
各家的重磅布局说明,做3D场景生成、视频生成模型、空间智能的必要性,已经迫在眉睫。
诚如英伟达高级计算机科学家Jim Fan所言,「空间智能,是计算机视觉和实体智能体的下一个前沿」。
空间智能,几大痛点亟待突破
不过仔细看就会发现,目前市面上相关的技术路线,尚存一些痛点未被解决。
比如市面上的一些2D图像或视频生成工具,仍然受制于像素空间和3D空间的差异,生成结果往往不一致、物理不合理。

由于2D图像或视频仅限于二维,创建复杂的动作和摄像机角度就极有挑战性,不适合动作场景
而TripoAI、Meshy等3D工具,则更关注单个物体的生成,因而无法生成完整、合理的3D场景。
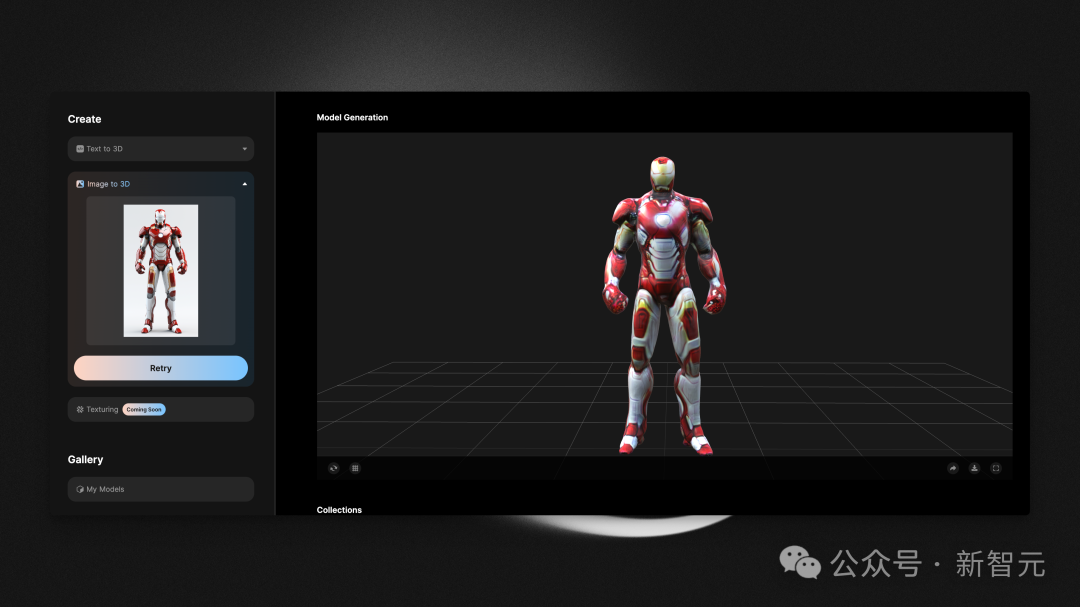
即使已经走在前面的WorldLabs,也存在不少限制。比如在探索空间上的不足,就会极大地影响游戏制作和视频渲染。

有没有一种技术路线,能将上述痛点全部解决?
巧了,看完Matrix-Zero,你会收获大大的惊喜!
360度无死角生成,还可交互
这次昆仑万维推出的Matrix-Zero,主要包括3D场景生成和可交互视频生成两部分。
首先,它支持将用户输入的图片,转化为可自由探索的真实合理的3D场景,同时极大避免了一些视频模型或自回归方法中极易出现的前后不一致现象。
那么如何从3D场景渲染出视频的呢?正如下图所示,在3D场景中放置一个摄像机(橘红色线框所示),并指定其运动控制。

3D场景中的相机运动轨迹
每一个时刻都可以根据相机位置和朝向将3D场景渲染为图片,将这些图片拼接即可得到视频。
最后,我们就能够得到3D场景渲染出的视频。

渲染视频效果
这样,不仅视频内容非常符合用户意图,还能拓展在虚拟环境、交互式应用和沉浸式体验中的应用场景,可以用在3D游戏场景中快速可控建模,以及在具身智能中
快速搭建模拟场景。


另外,Matrix-Zero可以支持在场景中进行任意方向长距离、大范围的探索,这就为电影、短剧场景镜头生成,提供更多可能。
在这些场景中,你可以先环视再前进、前进后右转、360度俯视、180度回头等等,各种操作只有你想不到,没有它做不到。


而且,无论你输入的是卡通或写实风格的图片,都能生成合理的3D场景。



Matrix-Zero还支持风格迁移,我们可以把一张写实图片转化为卡通风格,或者干脆把房屋变为红瓦白墙。


最后,Matrix-Zero生成3D的场景中的动态物体,也绝对令人惊喜。
无论是光照、海浪、云雾、水流,动态都极度符合真实世界的物理规律,因而可以由之构建真正的世界模型。


为何Matrix-Zero的3D场景生成能有如此惊艳的效果?
这都要归功于昆仑万维自研的3D场景生成大模型。
它包含了两个核心模块,场景布局生成模块和纹理生成模块。
前者能借助可微渲染和扩散模型技术,创造出和输入图片一致的3D场景布局;后者则是在图片生成模型和视频生成模型基础上训练的,能实现符合场景布局的纹理
材质生成。
而用户在场景中运动时,3D场景生成大模型就会不断对场景缺失区域进行几何和纹理的补全,因此用户无论在任何位置、任何角度,都能看到合理、一致的场景。
AI视频模型不断推陈出新,但真正能让创作者「身临其境」地参与生成过程的AI,却是凤毛麟角。
Matrix-Zero,正是打破这一僵局的革命性产品。
无论是在虚拟环境、交互应用,还是沉浸式场景中,它都能以惊人的效率输出高质量视频。
更重要的是,生成的视频始终保持流畅连贯,符合情境逻辑。
在案例中,它展现出令人惊叹的自由度,以及更加真实的3D场景生成。
当你在键盘上点击方向键,或是移动鼠标,AI会立即响应你的指令,生成与你意图完美契合的画面。
好比这张街景图生成的视频画面,你可以前后左右移动,随心所欲地调整视角,就像在真实世界中探索一样。


还有这张科幻风图片的交互,瞬间给人一种错觉:这不就是Martix中的世界么。


团队的方法建立在自研的生成式视频模型之上,依托大规模开放数据的预训练模型,同时结合了自主研发的用户输入交互模型。
最终,实现了一种以用户指令输入为核心驱动的空间智能视频生成方案。
这就保证了在开放视频领域生成能力的同时,进一步增强了对视频内容中视角移动的精确控制,从而更符合用户的交互需求和预期。
具体来说,Matrix-Zero包括基础视频生成模型和用户输入交互模型两个核心部分。
Matrix-Zero 主要由两个核心部分组成:一个是视频生成模型,另一个是用户交互模型。
前者是整个系统的核心,相当于一位「元帅」。而后者,则是一位「军师」。
元帅负责根据初始视频帧生成连贯的视频内容,军师则负责解析用户输入信息,转化为视频调整信号。这样,Matrix-Zero就既能生成清晰、稳定、有逻辑的视频,还
能准确响应,让交互更直观流畅。
具体来说,视频生成模型包含以下关键技术:
而用户交互模型则包含四个核心部分:
2.「连续视角控制模块」用于实时处理视角变化等连续控制信号;
3.「3D场景位置追踪模块」通过空间定位技术确保视角转换的稳定性;
4.「滑动窗口机制」利用历史输入预测用户操作,优化控制响应。
总之,以上特性让Matrix-Zero真正成为一款足够实用性的产品,在电影、短剧、游戏、具身智能等领域有广泛的应用空间。
游戏开发者和影视剧从业者等相关人员,可以用它实现明显的降本增效。
比如,游戏开发者可以用它轻松实现3D游戏场景搭建。
《黑神话:悟空》中的场景令人心潮澎湃
影视剧从业者,则可以轻松生成电影/短剧中的镜头。为了一个镜头动辄烧上百万甚至上千万美元经费的情况,从此可以彻底告别。

《阿凡达:水之道》是史上经费最高的电影之一,整部电影的预算为4.6亿美元左右,但单个VFX的成本可能就达到每秒数百万美元
由此显露的产品领先性也体现出,昆仑万维在科研、产品、应用上具备足够的前瞻性,已经形成了闭环的产业链。
空间智能,AI下一个里程碑
何谓空间智能?
在「AI教母」李飞飞看来,空间智能不仅仅是让AI看见世界,还要让AI理解三维世界,并具备与之互动的能力。
ImageNet所代表,只是对「智能」一半的理解,另一半还存在于物理世界中。
回顾AI发展历程,我们见证了其从文本到2D图像、视频的跨越。
以往的一些经验也告诉我们一个深刻的道理:高维度的理解和生成,绝非低维度模型所能企及。
不论是LLM还是多模态语言模型(MLLM),其底层架构仍局限于一维的表征。
这种一维表示在处理语言方面得心应手,但当处理图像、视频等其他模态数据时,本质上不过是将多维信息「压缩」进一维序列中,就不会可避免地造成信息损失。
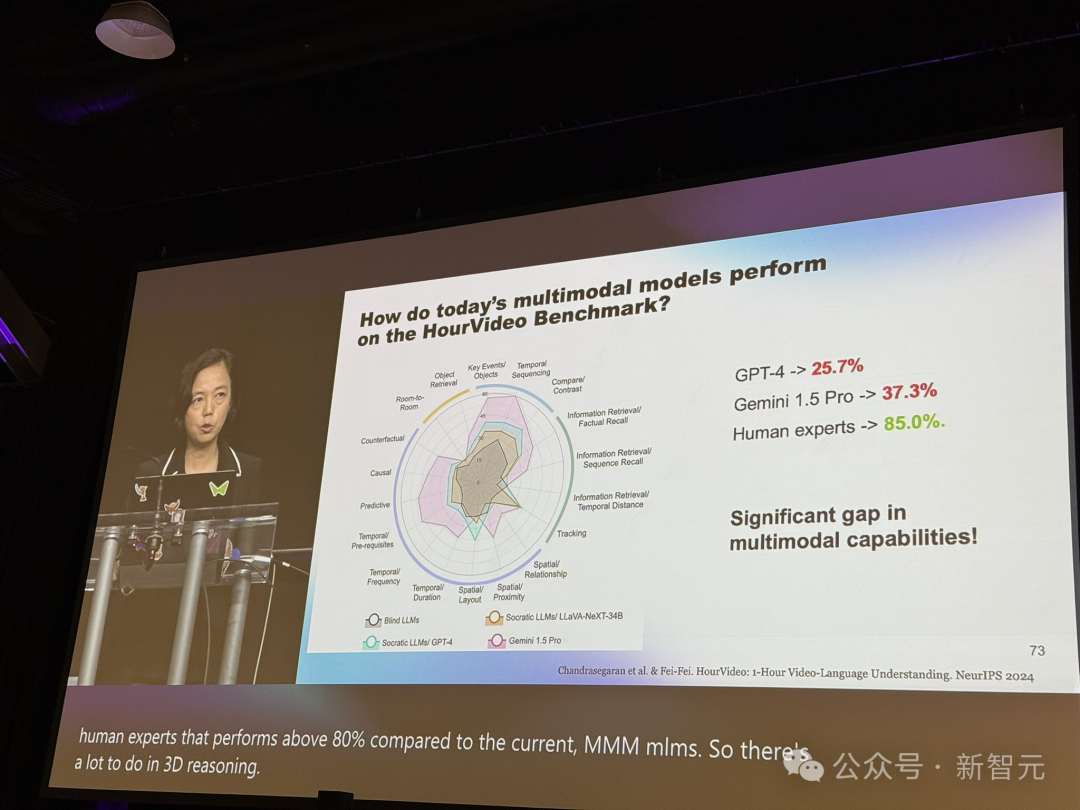
NeurIPS 2024上,李飞飞提到最领先的多模态模型在HourVideo基准上依旧与人类有很大差距
就像文字难以完整描绘出图像的细节,2D模型在处理3D世界时也面临着严峻的挑战。
举个栗子,当前AI生成的视频中,在涉及物体/人物大幅度移动变化的情景下,往往难以保持一致性。
这恰恰暴露出这些低维度的模型,对3D世界理解的局限性。
当然,空间智能也绝不止于简单的3D生成,如果仅依靠维度scaling是远远不够的。
我们还需要做的是,在大模型训练过程中,还需要将3D世界的几何和物理规则系统植入,从而让AI拥有对这个世界的推理、理解、生成能力。
空间智能这一愿景,在2024年底已见雏形。
除了李飞飞World Labs、谷歌Genie 2,在国内,一些团队也做了类似的研究,比如中科院等团队的SceneX、智源研究院的See3D等等。
与他们不同的是,昆仑万维走正出自己独一份的空间智能路线。
从生成的视频中不难看出,Matrix-Zero自由探索的范围任意大,任意广。而且,可以直接交互输出视频,在稳定一致性方面做到业界领先。
那么,能做到中国第一家自研,第一家发布空间智能大模型的上市公司,具备了怎样的优势?
全矩阵布局,All in AGI
2020年,GPT-3横空出世后,昆仑万维做出了一个重要的决定——全面布局大模型。
两年后,AIGC全系列算法与模型「昆仑天工」首次亮相,其能力覆盖了图像、音乐、文本等多模态内容的生成能力。
2023年,自研双千亿级「天工1.0」大模型推出,正式奠定了国产大模型崛起之路。
多模态大模型Skywork-MM在MME基准中,1.0拿下了综合排名第一的成绩。他们还开源了百亿级大语言模型天工Skywork-13。
同年,基于「天工」大模型,这家公司打造了一系列颠覆性AI产品。
到了2024年2月,基座大模型迎来了最大升级,采用MoE架构「天工2.0」在处理复杂任务更强、响应速度更快、训练推理效率更高。
紧接着4月,「天工3.0」震撼发布,采用4000亿参数MoE架构,性能较上一代飞升,数学代码飙升超30%。
与此同时,AI音乐生成大模型「天工SkyMusic」开启公测,向情感AGI又迈进一步。
8月,集成视频大模型与3D大模型的AI短剧平台SkyReels发布。
今年1月,天工大模型4.0 o1版/4o版正式上线天工网页端和APP,免费无限用,性能直接对标OpenAI。
截至目前,昆仑万维已自研出「五大模型」体系:文本大模型、多模态大模型、3D大模型、视频大模型和音乐大模型。
与此同时,在2024年AIGC应用用户规模TOP榜中,昆仑万维旗下天工AI强势入围。

这种全方位的技术布局,为其在AI领域持续创新提供了坚实的基础。
2023年,昆仑万维曾立下豪言壮志:All in AGI和AIGC,并将其作为未来十年的战略方向。
五大模型体系,正在为这个终极目标不断铺路。
从行业发展的角度来看,多模态大模型正经历这一场深刻的变革。
多模态技术已经从早期的简单图文理解,逐步演进至复杂的跨模态推理和生成。
在其未来发展中,我们可以预见在多模态领域几个关键的突破方向。
首先是多模态融合进一步深化,未来的模型将不再满足于简单多模态并列,而是要实现真正模态间的深度理解和转换。
比如,模型不仅要「看懂」一段视频,还要能准确理解视频中运动规律,并将这种理解应用到其他场景中。
其次,新一代模型架构需要能够同时整合空间、时间、物理等多维度信息,这种整合不是简单的叠加,而是要在更深层次上实现知识互通和迁移。
而空间智能的到来,将推动模型在多个维度上的升级同时展开。
未来,空间智能模型的落地场景将更加丰富多样。
在教育领域,它可以创造沉浸式学习体验,让抽象的知识变得直观可感;在工业领域,它能更精准控制机器人和自动化生产;在创意领域,它甚至可以革新内容创作
的方式,带来前所未有的视觉体验。
AI写诗十四行诗很有趣,用AI辅助心脏手术则是颠覆性的变革
从更宏观角度来看,空间智能代表了AI向着更高维度认知能力进化的方向。
在这场AI进化的马拉松中,昆仑万维展现出了罕见的战略定力和技术魄力。据悉,Matrix-Zero世界模型将于4月份上线。
从ALL in AGI的宏大愿景,到空间智能的前瞻布局,这家公司正用实际行动诠释着技术创新的深层内涵。
文章来自于微信公众号 “新智元”,作者 :编辑部 HYZ



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/

