邢波再出手:上次「骂」完世界模型,这次轮到智能体了
邢波再出手:上次「骂」完世界模型,这次轮到智能体了去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
来自主题: AI技术研报
6521 点击 2026-07-01 15:43
 搜索
搜索
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

Prompt还没退场,Loop已经开始接管AI叙事。

Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。

新时代的 Physical AI 公司,不是本体公司,也不是模型公司。
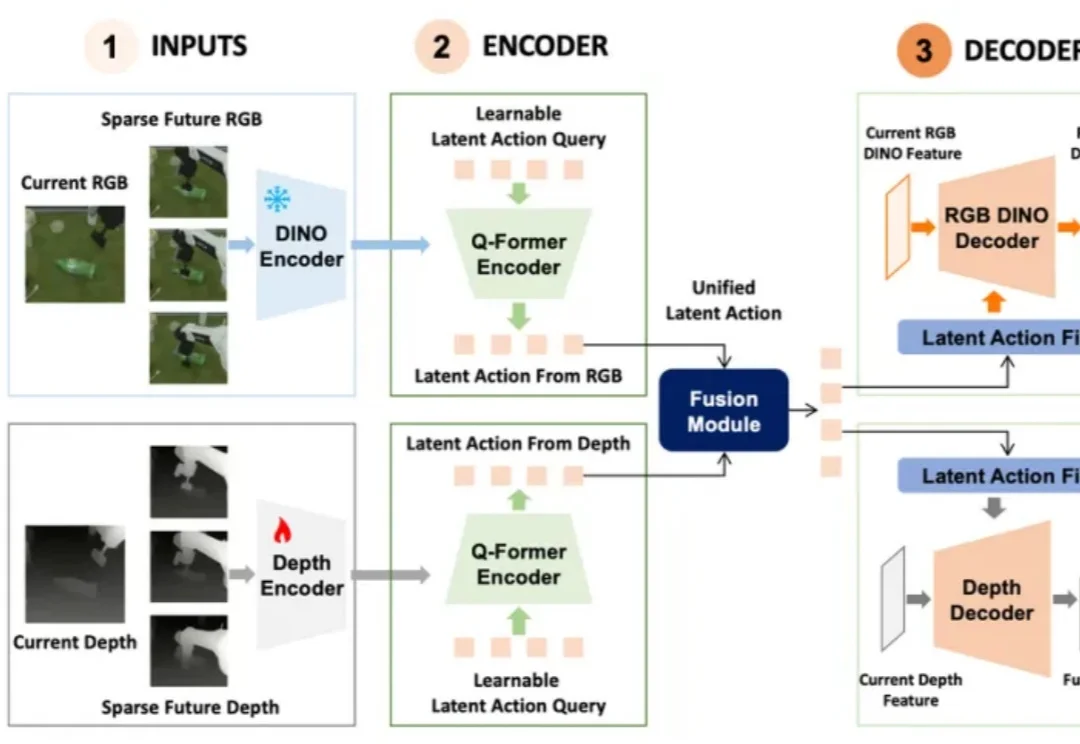
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。

独家获悉,清华系初创公司「厘清智能」宣布完成数亿元种子轮融资,投资方阵容堪称豪华:由顺为资本、红杉中国、高瓴创投、峰瑞资本、星连资本、水木清华校友种子基金、SEE FUND等一线基金,与智元机器人、灵心巧手、世纪金源等产业资本共同投资。其中,顺为资本与红杉中国更是连续多轮追加投资。

你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
近期,基点起源完成了数亿元融资。半年前,我们第一次和基点起源创始人兼 CEO 戴宗宏交流时,这家逆流入局 B 端定制化的AI公司,刚刚推进了 7、8 个项目。戴宗宏对《智能涌现》透露,基点起源的订单数翻了一番,订单合同金额较半年前提升了一个数量级,AI 解决方案已经落地到了冶金、化工、精密制造、半导体、纺织等 10 多个行业。