# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当下的技术领域中,人像视频生成(Human-Video-Animation)作为一个备受瞩目的研究方向,正不断取得新的进展。人像视频生成 (Human-Video-Animation) 是指从某人物的视频中获取肢体动作和面部表情序列,来驱动其他人物个体的参考图像来生成视频。
随着视频生成技术的迅猛发展,特别是生成模型的持续更新迭代,该领域迎来了前所未有的进步。鉴于其在数字艺术、社交媒体以及虚拟人等众多领域广泛的应用前景,人像视频生成吸引了越来越多研究人员的目光。
目前的研究工作普遍采用并行 U-Net 结构的扩散模型 (Diffusion Model) 和额外的参考网络 (ReferenceNet) 来编码参考图像特征。尽管生成的人像视频动作精准度相比于生成对抗网络 (GAN) 有所提高,但此类方法往往无法捕捉复杂的视觉动态细节,导致背景静止缺乏真实感。
这一缺陷来自于参考网络的并行 U-Net 结构设计包含了过强的控制模块,其空间注意力机制 (Spatial-Attention) 限制了模型的动态细节生成能力。
也有其他工作直接采用视频模型 (例如 Stable-Video-Diffusion) 作为骨干网络在真实的人像数据上训练,但是这类方法需要对骨干网络进行微调,因此缺少对其它类型的参考图像 (例如卡通人物) 的泛化能力。除此之外,实现精准的表情控制也是该领域研究的重点之一。
为有效解决这些问题,来自南加州大学、字节跳动、斯坦福大学、UCLA 和 UCSD 的研究团队提出了 X-Dyna,让生成模型在保持人物肢体动作和面部表情迁移准确性的前提下,同时产生人物前景(例如头发和衣物的运动)以及自然背景(例如瀑布、烟火和海浪),以实现自然逼真的人像视频生成。

话不多说,先来看看 X-Dyna 的效果:
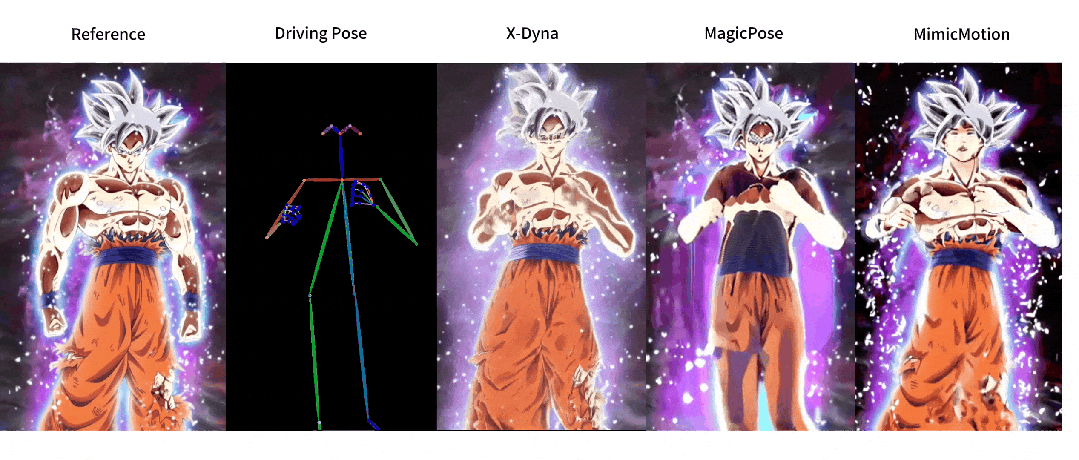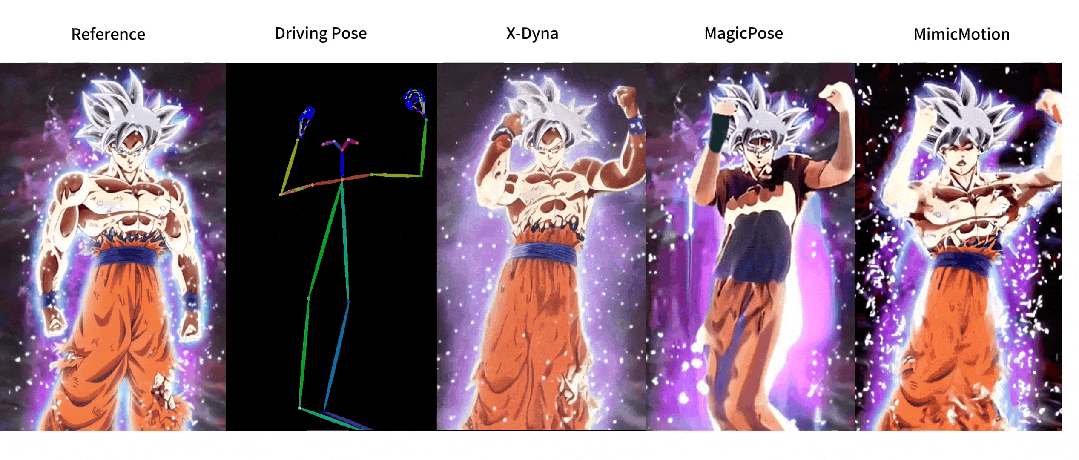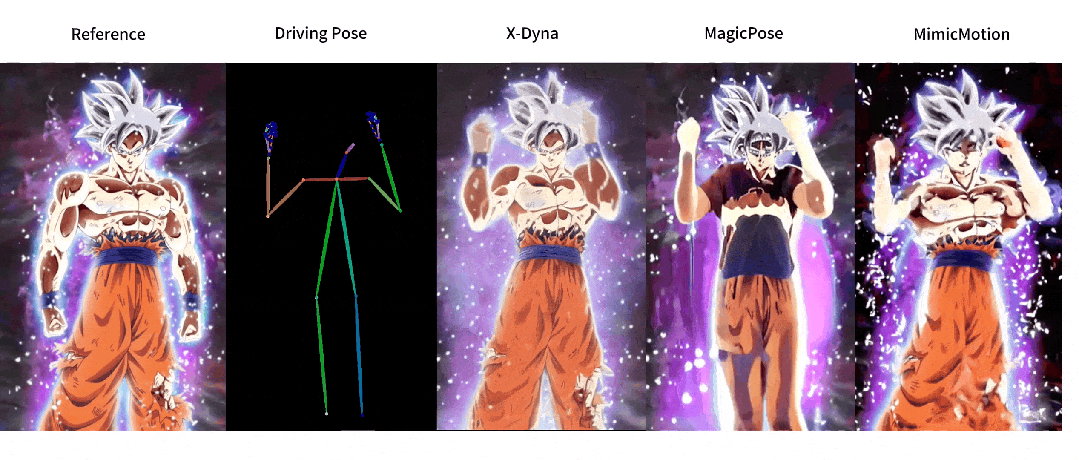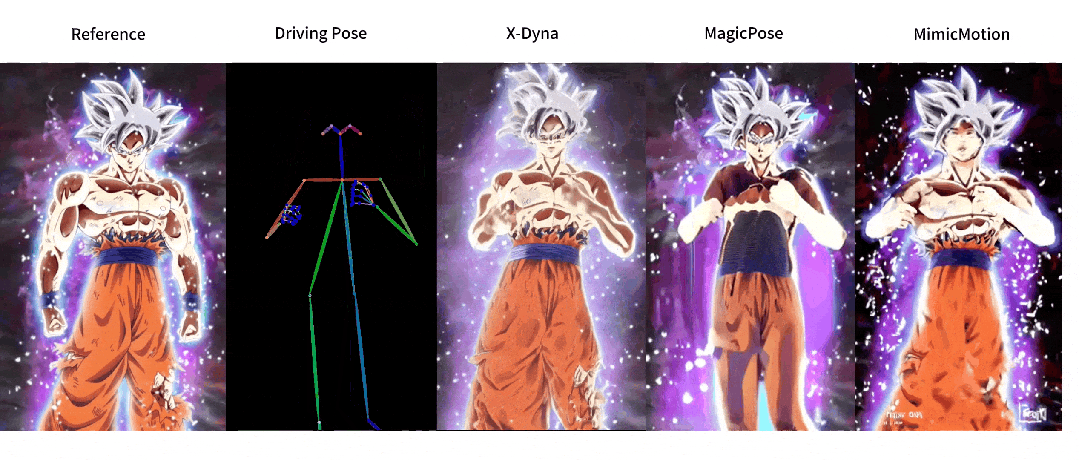

这回,让照片动起来的时候终于不是人物在前面自嗨,背景在后面尴尬地当「静态壁纸」了,现在的画面,从主角到背景都能一起嗨起来。
技术方案
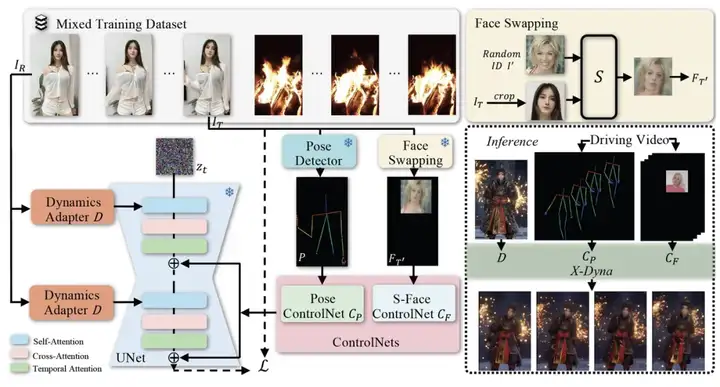
X-Dyna 是一个端到端的框架,它主要包含三个部分,分别是 :
1)轻量跨视频帧的注意力模块 Dynamics-Adapter,它将参考图像与噪声序列并行输入扩散模型的骨干网络,并通过自注意力机制 (Self-Attention) 把参考图像中的语义信息加入到去噪过程。
2)人脸局部控制模块 S-Face ControlNet, 它通过训练时对驱动视频进行人脸局部检测和换脸来分离人物的 ID 和面部表情,以此提升表情迁移的准确性。测试时无需换脸,驱动视频只需要进行人脸检测即可作为输入。
3)人物肢体运动控制模块 Pose ControlNet,它使用人体骨架作为输入来实现动作迁移。
与 ReferenceNet 的结构设计不同之处是, Dynamics-Adapter 引入了极少的额外训练参数,它可以有效地将人物外观和自然背景上下文从参考图像注入到骨干网络,并且不会导致骨干网络丧失动态细节的生成能力。
与 IP-Adapter 结构相比,Dynamics-Adapter 能更好地保持输入图像的 ID 和人物外观。具体实现和动态细节生成效果如下图所示:
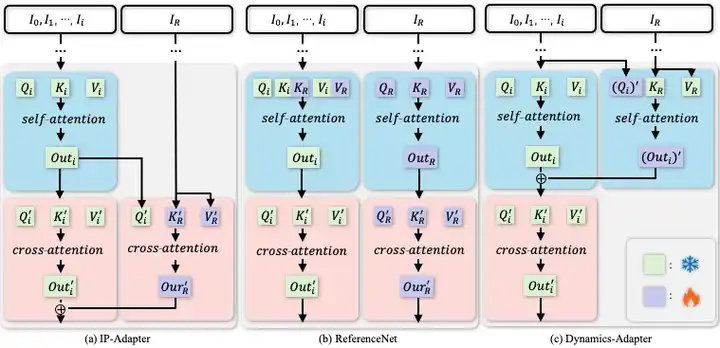
a) IP-Adapter 通过 CLIP 将参考图像编码,并将信息作为残差注入主干网络中的交叉注意力层。b) ReferenceNet 是一个可训练的并行 U-Net,他通过连接自注意力层特征将语义信息输入骨干网络。c) Dynamics-Adapter 使用部分共享权重的 U-Net 对参考图像进行编码,外观控制是通过在自注意力层中学习残差来实现,所有其他部分与骨干网络共享相同的冻结权重。
效果展示
与之前方法的对比

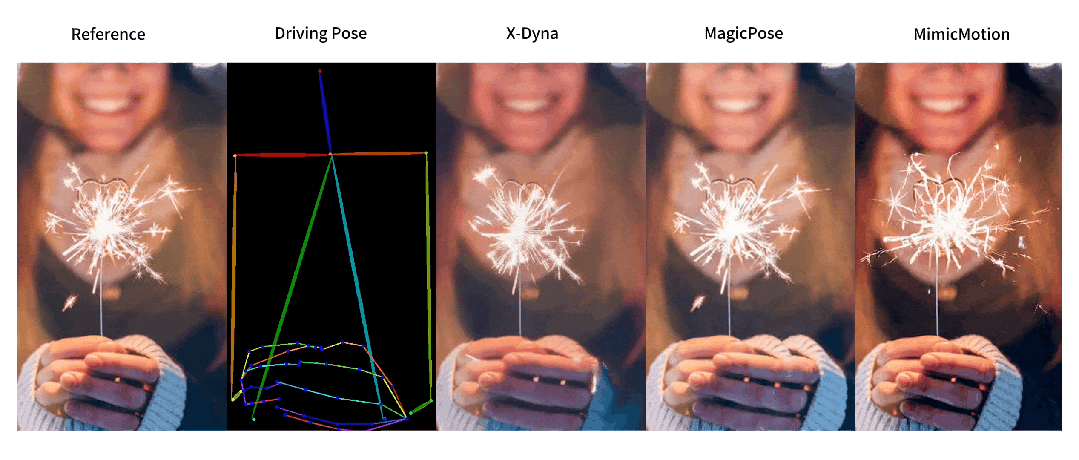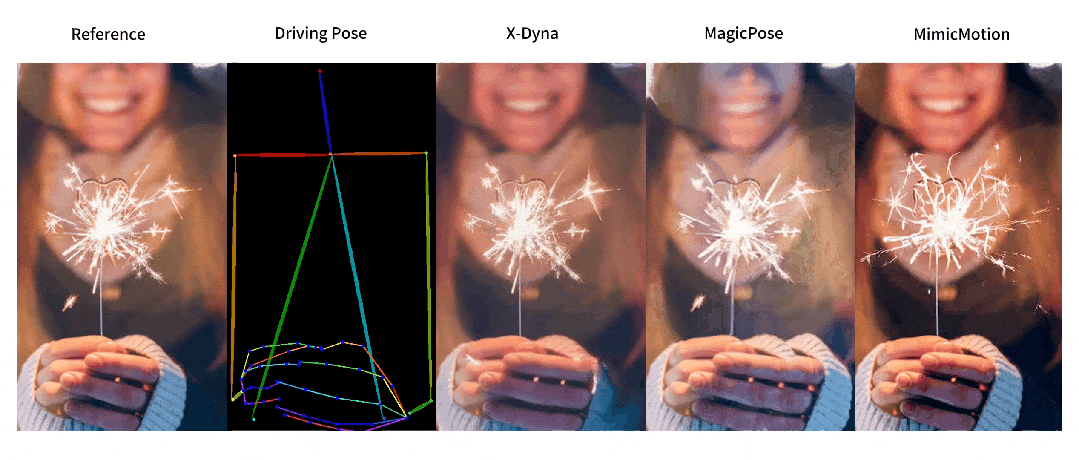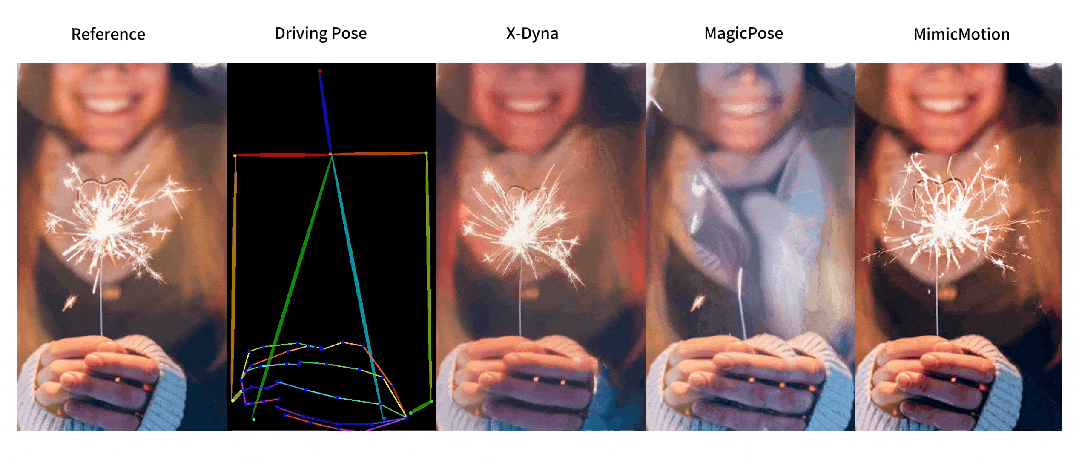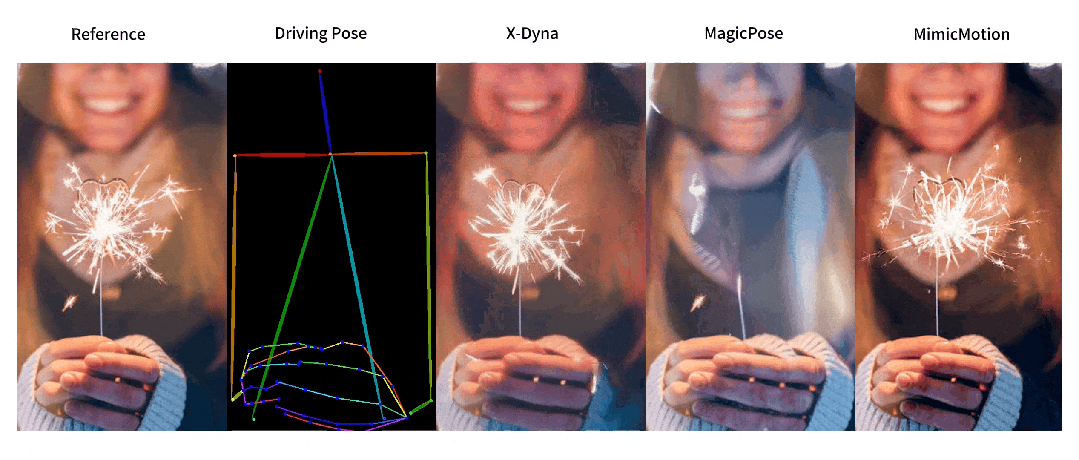
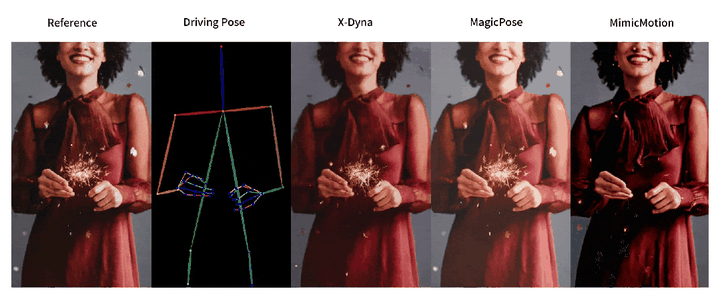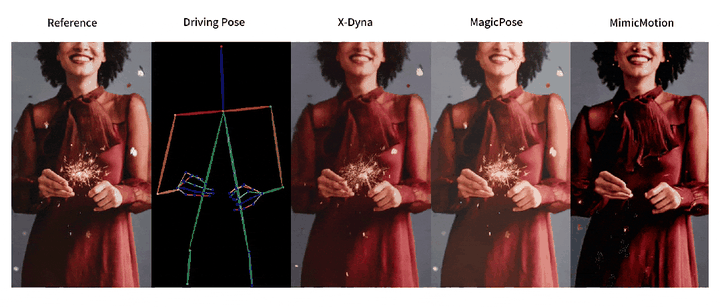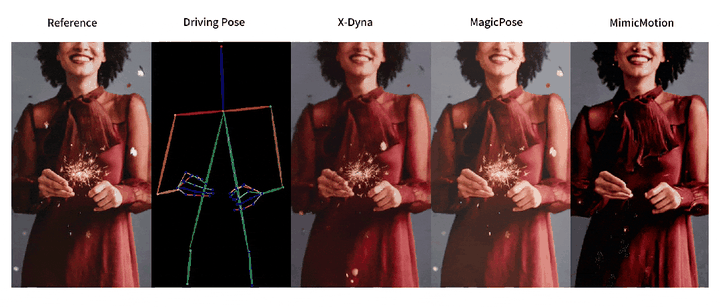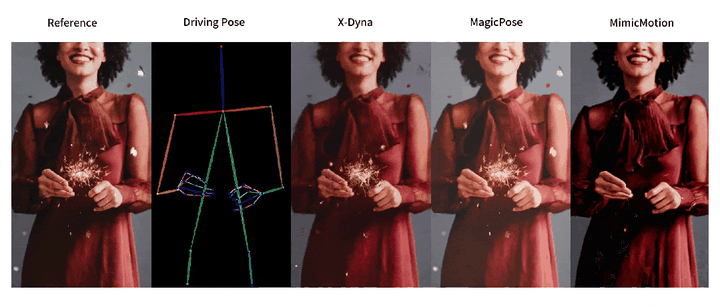





人像视频生成

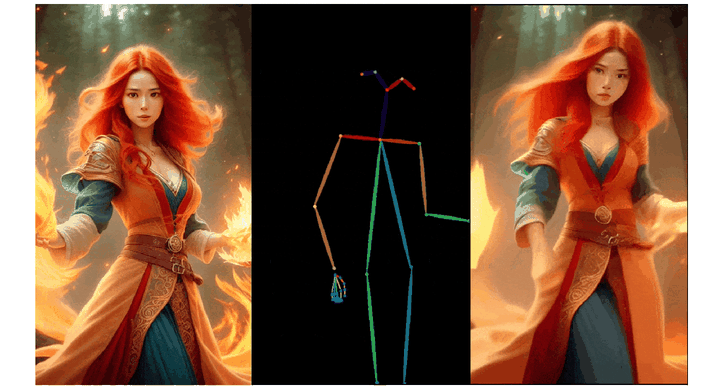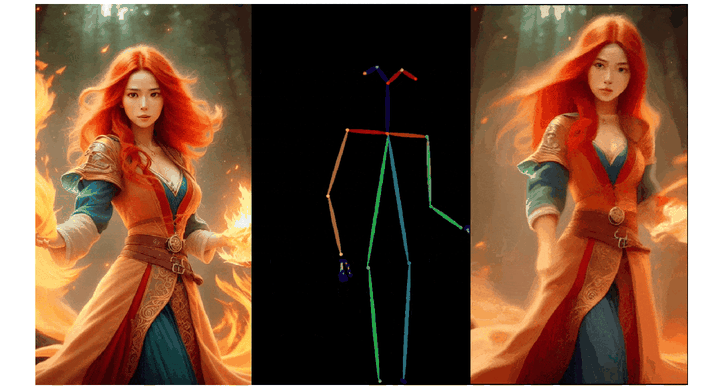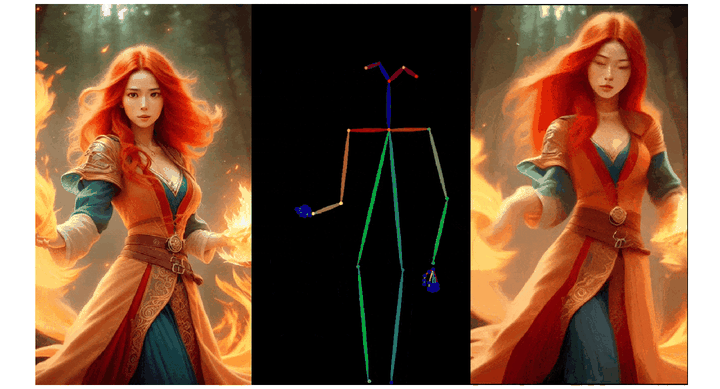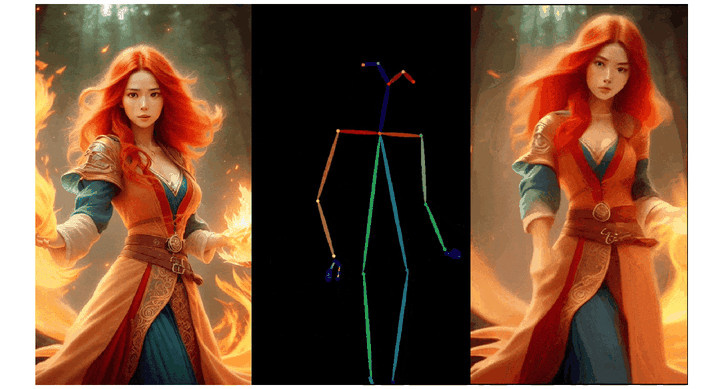

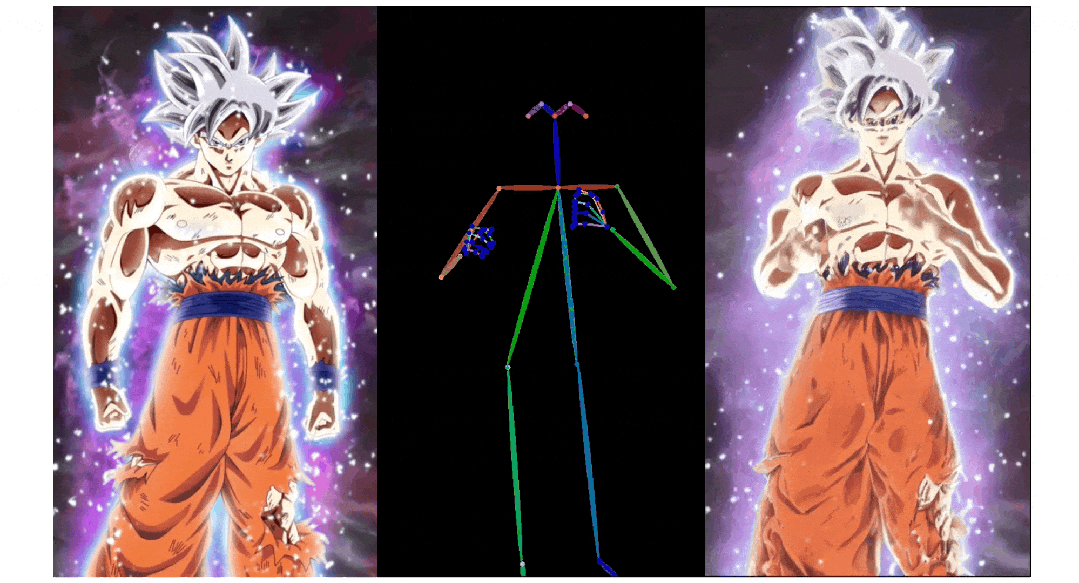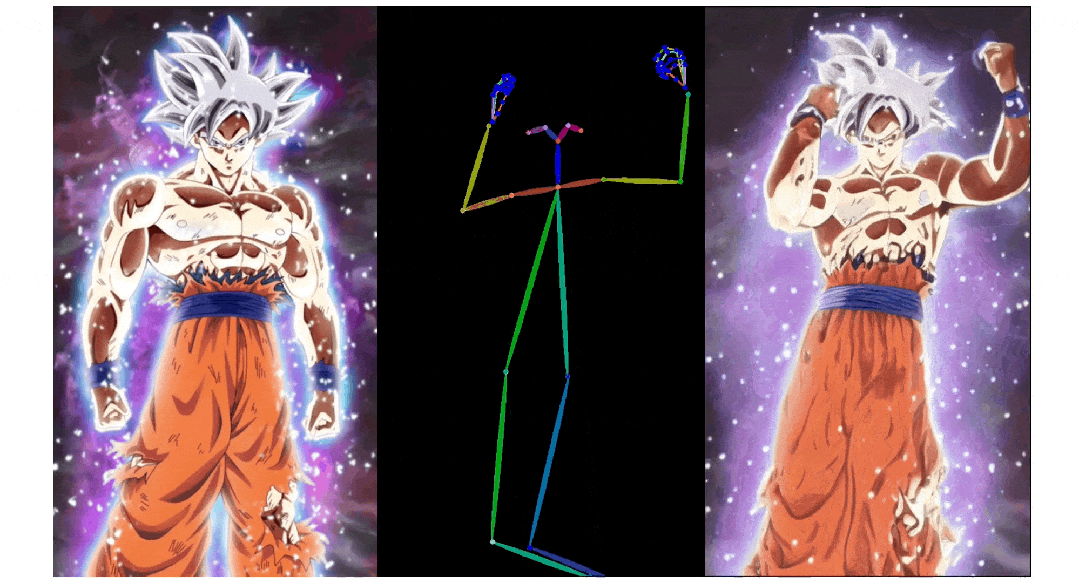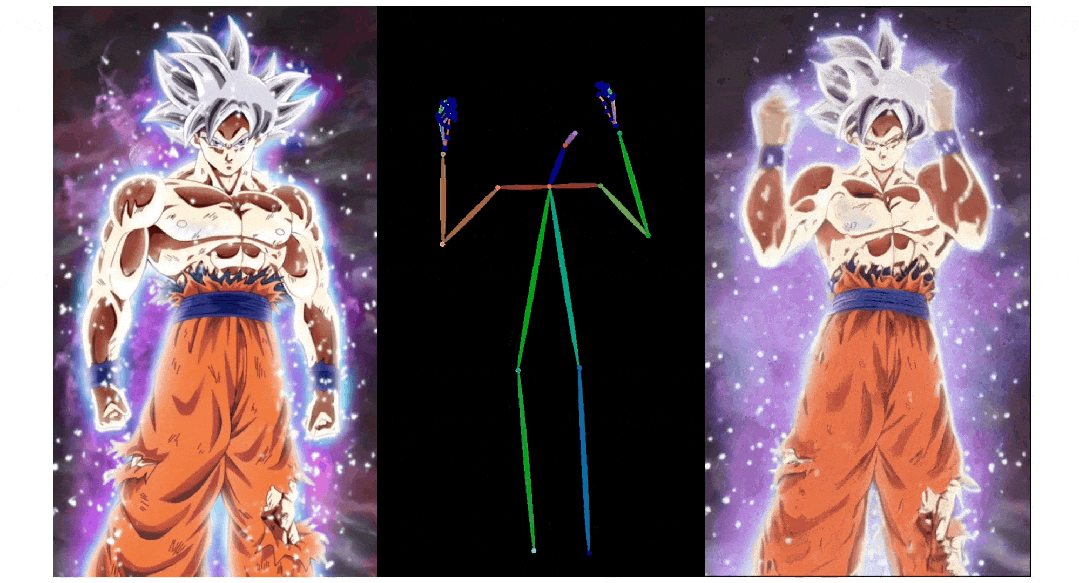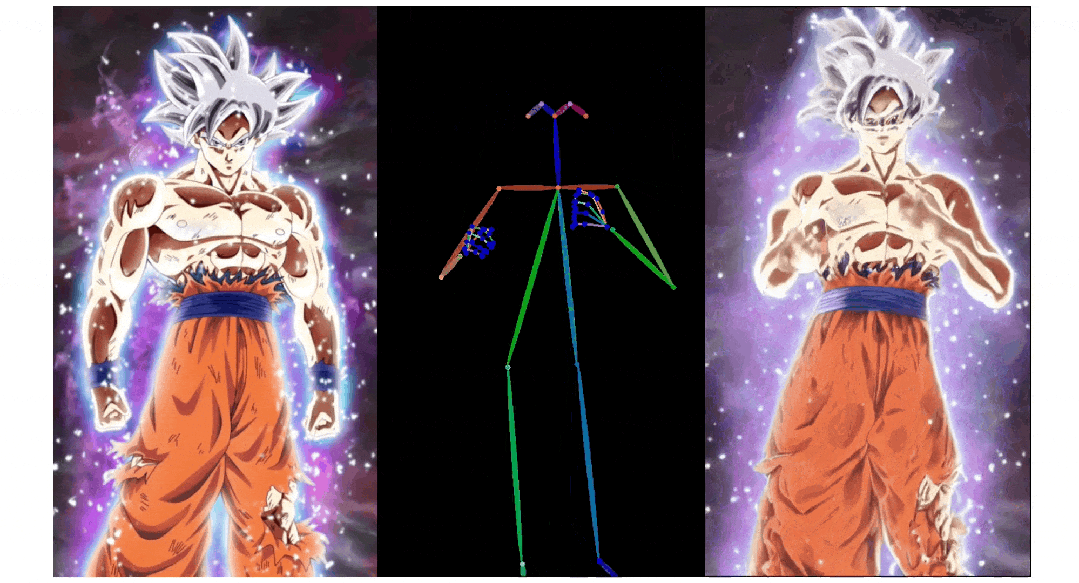

实验结果
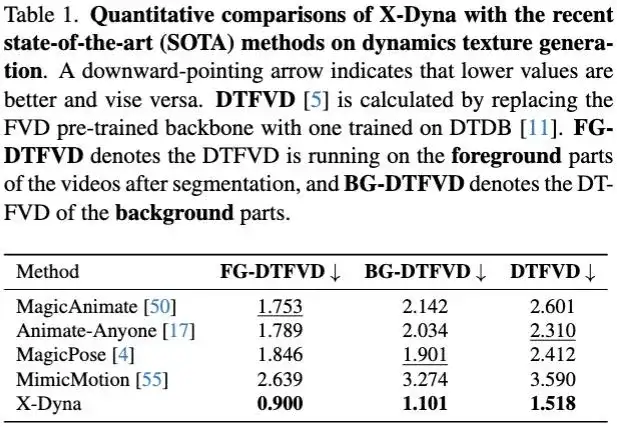
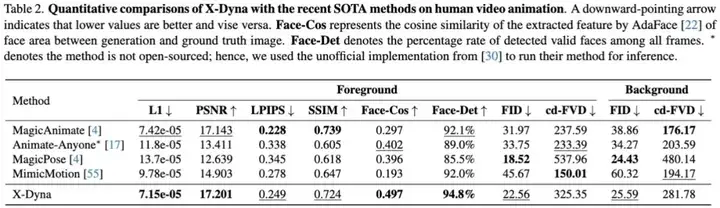
在实验章节中,文中从多个方面详细对比了 X-Dyna 和其它市面上的 SOTA 框架,以此来证明该方法的有效性。对于动态细节的生成能力,X-Dyna 使用 DTFVD 指标分别对人物前景,自然背景和整体生成质量进行评测。
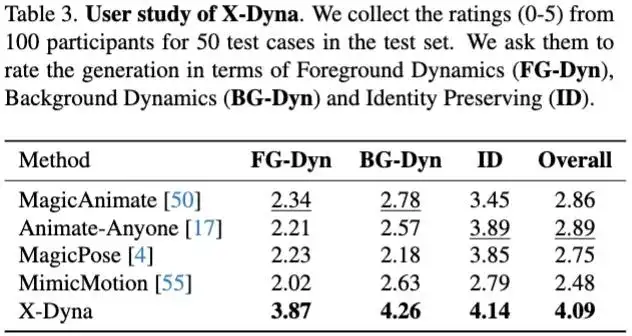
文中还对实验结果进行了 User Study 来进一步评测:
此外,文中对 X-Dyna 进行了与现有方法人物动作和脸部表情生成的定量对比实验:
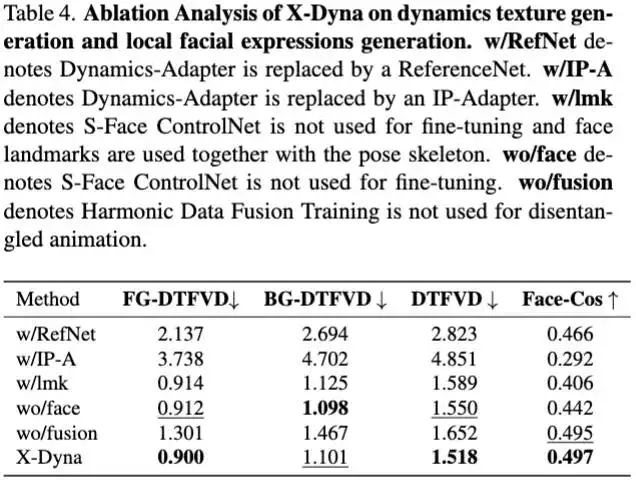
消融实验

此工作仅以学术研究为目的。上述示例是从公开数据集获取的,仅为展示模型效果。如有侵权或冒犯,请联系论文作者(dichang@usc.edu),将及时删除。
字节跳动智能创作数字人团队参与了 X-Dyna 的研究。智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。
目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中。
文章来自于微信公众号“机器之心”




【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
