# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。这种方法通过预测下一个词的方式拆解语言联合概率,形式化如下:
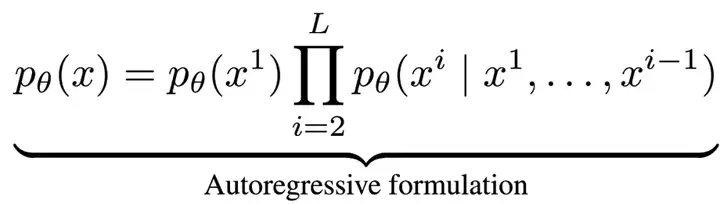
最近,人大高瓴李崇轩、文继荣团队和蚂蚁集团的研究员提出了一种新的洞察:大语言模型展现的语言智能(如上下文学习、指令遵循、推理和多轮对话等能力)并非自回归机制独有,而在于背后所遵循的生成建模原则,即通过最大似然估计(或最小化 KL 散度)来逼近真实语言分布。

正是基于这一理念,团队开发了 LLaDA(Large Language Diffusion with mAsking)—— 一种基于掩码扩散模型的语言生成方法。与传统自回归模型不同,LLaDA 采用了前向掩码加噪和反向去噪的机制,不仅突破了单向生成的局限,还通过优化似然下界,提供了一种不同于自回归的、原理严谨的概率建模方案。
通过大规模实验,LLaDA 8B 在可扩展性、下游语言任务中全面媲美现代大语言模型,如 Llama3 8B。这些结果一定程度上表明,LLMs 的核心能力(如可扩展性、上下文学习和指令遵循)并非自回归模型独有,而是源自于合理的生成建模策略和充分的模型数据规模。LLaDA 不仅提出了一种新的大语言模型的概率建模框架,也有助于我们进一步理解语言智能。

团队预计近期开源推理代码和 LLaDA 8B Base 权重,后续还将开源 LLaDA 8B Instruct 权重。
卓越的可扩展性。在多个语言任务上,LLaDA 和自回归模型基线进行了严格对比。实验表明,在相同的数据条件下,LLaDA 在 MMLU、GSM8K 等多个任务上展现了与自回归模型相当的表现,证明了其在高计算成本下的强大扩展能力。即使在某些相对薄弱的任务上,随着模型规模的增大,LLaDA 也能迅速缩小与自回归模型之间的性能差距。
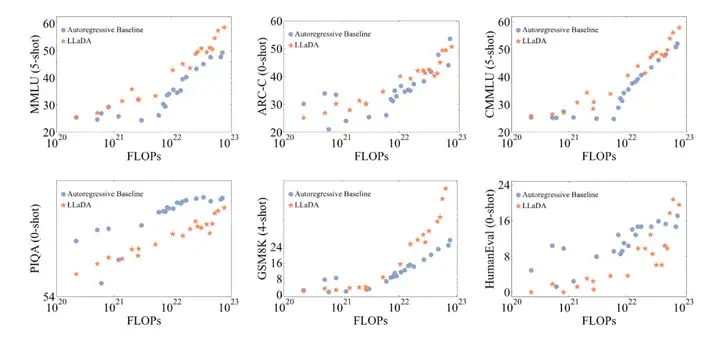
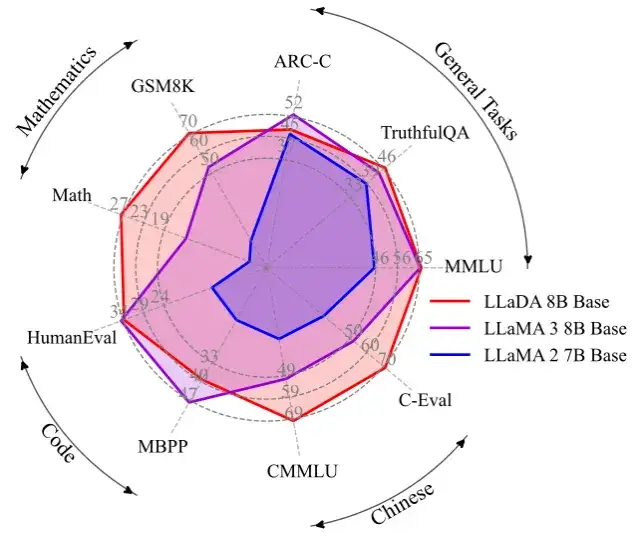
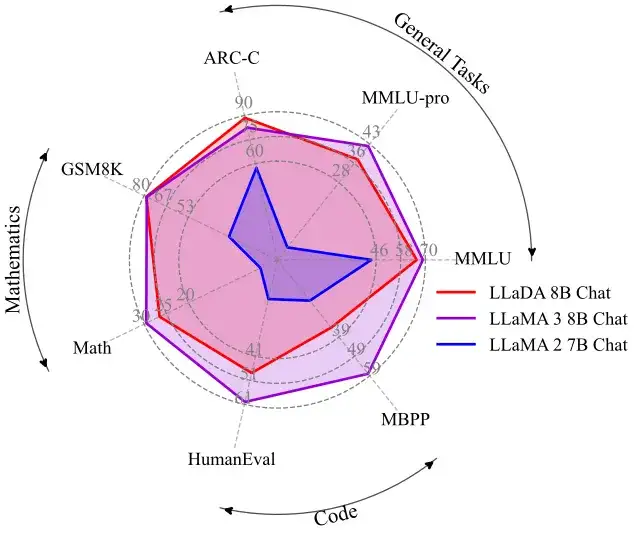
出色的上下文学习与指令遵循能力。在涵盖 15 个热门基准测试(包括通用任务、数学、代码及中文任务)的评测中,预训练了 2.3T tokens 的 LLaDA 8B Base 模型凭借强大的 zero/few-shot 学习能力,整体表现超越了 LLaMA2 7B Base (预训练 tokens 2T),并与 LLaMA3 8B Base (预训练 tokens 15T)媲美。在经过监督微调(SFT)后,LLaDA 的指令遵循能力得到了显著提升,能在多轮对话及跨语种生成任务中保持连贯性和高质量输出,充分展现了其对复杂语言指令的良好理解和响应能力。
下图是在一些热门基准上 LLaDA 和 LLaMA3 以及 LLaMA2 的性能对比,详细结果请参见论文。
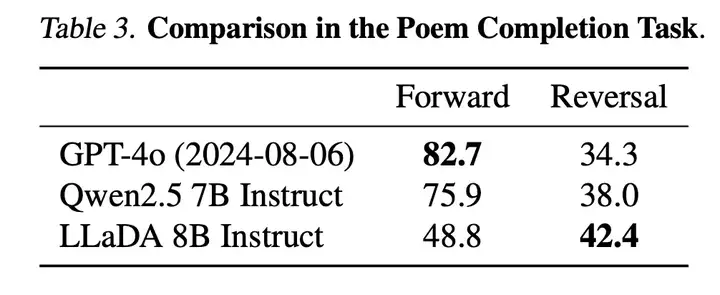
平衡的正向与逆向推理能力。传统自回归模型在逆向推理任务中常常存在「逆向诅咒」[3] 问题,好比当模型在「A is B」数据上训练之后无法回答「B is A」。而 LLaDA 则通过双向的概率建模机制,有效克服了这一局限。在诗歌补全任务中,LLaDA 在正向生成与逆向生成上均取得了均衡表现,尤其在逆向任务中明显超越了 GPT-4o 和其他对比模型,展现了强大的逆向推理能力。
多场景下的实际应用效果。除了标准测试指标外,我们在多轮对话、数学题解和跨语言文本生成等实际应用场景中也看到了 LLaDA 的出色表现。无论是复杂问题求解、指令翻译,还是创意诗歌生成,LLaDA 都能准确把握上下文并生成流畅、合理的回答,充分验证了其在非自回归生成模式下的应用前景。
下图是 LLaDA 在回答用户提问的一个例子,用户输入的 prompt 是「Explain what artificial intelligence is」。LLaDA 采取了一种不同于自回归模型从左到右的生成方式。

下图是 LLaDA 同用户进行多轮对话的场景。LLaDA 不仅正确回答了诗歌《未选择的路》的前两句,而且成功将英文翻译成中文和德语,并且按照用户要求创作了一首五行,且每一行均以字母 C 开头的诗歌。

下图展示了 LLaDA 的预训练、监督微调以及采样过程。


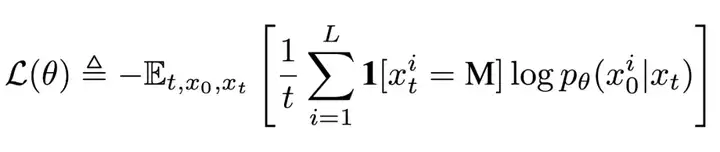
前期工作 [2] 已证明该目标函数为负对数似然的上界,从而为生成建模提供了严格的理论依据。

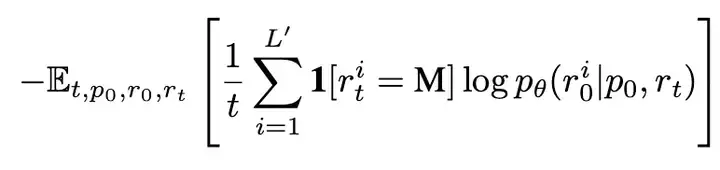

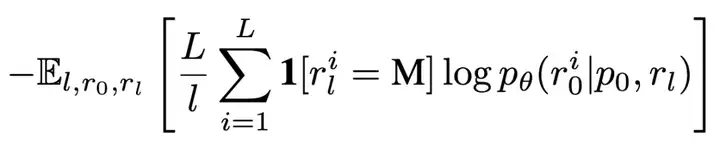

扩散语言模型 LLaDA 首次展示了通过前向掩码加噪与反向去噪机制,同样可以实现大语言模型的核心能力。实验表明,LLaDA 在可扩展性、上下文学习和指令遵循等方面表现优异,具备与传统自回归模型相媲美甚至更优的性能,同时其双向生成与增强的鲁棒性有效突破了自回归建模的固有限制,从而挑战了「大语言模型的智能必然依赖自回归生成」的传统观念。
参考文献
[1] Ou J, Nie S, Xue K, et al. Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data. To appear in ICLR, 2025.
[2] Nie S, Zhu F, Du C, et al. Scaling up Masked Diffusion Models on Text. To appear in ICLR, 2025.
[3] Berglund L, Tong M, Kaufmann M, et al. The reversal curse: Llms trained on"a is b" fail to learn"b is a"[J]. arXiv preprint arXiv:2309.12288, 2023.
文章来自于“机器之心”,作者“李崇轩、文继荣教授团队和蚂蚁集团”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
