# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这次不是卷参数、卷算力,而是卷“跨界学习”——
让Stable Diffusion当老师,教多模态大模型(如Llama-3.2)如何“看图说话”!
性能直接飙升30%。
中国研究员联合DeepMind团队的最新研究《Lavender: Diffusion Instruction Tuning》,通过简单的“注意力对齐”,仅需1天训练、2.5%常规数据量,即可让Llama-3.2等模型在多模态问答任务中性能飙升30%,甚至能防“偏科”(分布外医学任务提升68%)。
且代码、模型、训练数据将全部开源!
下面具体来看。
当前遇到的问题是:
传统多模态大模型(VLM)的“视觉课”总不及格?数据不够、过拟合、细节抓不准……像极了考前突击失败的学渣。

对此,团队提出了新的解决方案:
让Stable Diffusion这位“图像生成课代表”,直接共享它的“学霸笔记”——注意力分布。
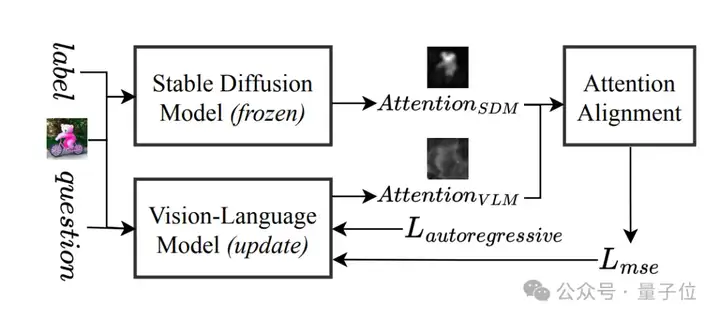
展开来说,其跨界教学可分为三步走:
Step1:拜师学艺。VLM(如Llama-3.2)向Stable Diffusion学习如何“看图”,通过轻量级对齐网络(Aligner)模仿其交叉注意力机制。
Step2:高效补课:仅用13万样本(常规数据量的2.5%)、8块GPU训练1天,不卷数据不烧卡。
Step3:防偏科秘籍。引入LoRA技术“轻装上阵”,保留原模型能力的同时,专攻薄弱环节。

然后来看下具体效果。
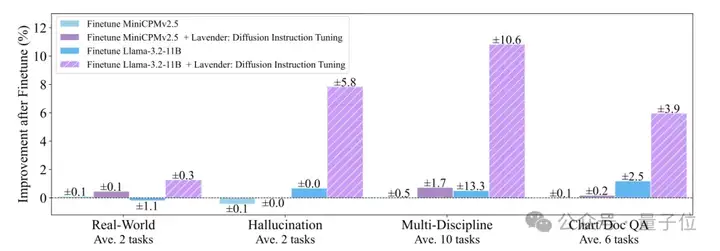
从论文晒出的成绩单来看,在16项视觉-语言任务中,Lavender调教后的Llama-3.2,性能大有提升——
在预算有限的小模型赛道上,超过SOTA(当前最优模型)50%。
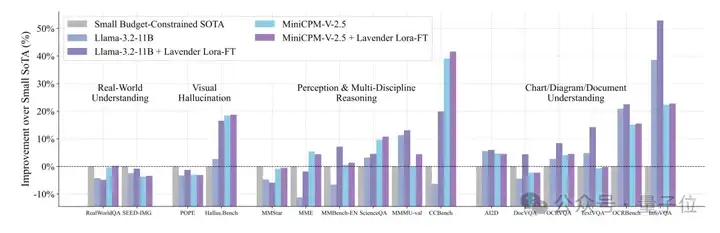
在超大模型圈子里,Lavender调教的Llama-3.2-11B居然能和那些“巨无霸”SOTA打得有来有回。
要知道,这些对手的体量一般在它的10倍以上。
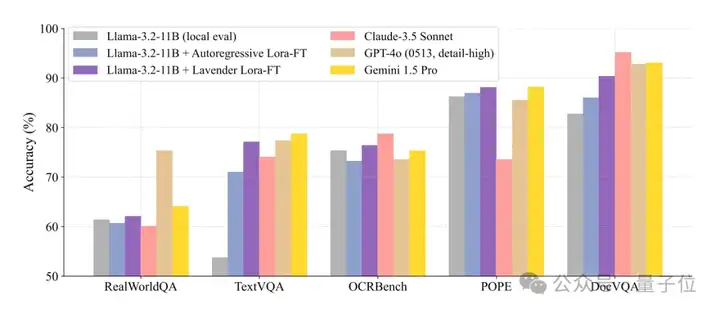
更令人惊讶的是,Lavender连医学数据都没“补习”,就直接让Llama-3.2-11B在WorldMedQA这个“超纲考试”中成绩暴涨68%。
具体分数见图表(柱状图已标出)
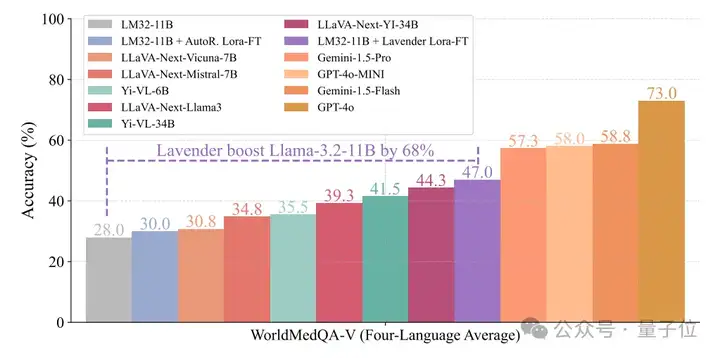
小结一下,新研究主要技术亮点如下:
1、注意力对齐:Stable Diffusion的“独家教案”
传统VLM的注意力机制像“散光患者”,而Stable Diffusion的注意力分布则是“高清显微镜”。Lavender通过MSE损失函数,让VLM学会Stable Diffusion的“聚焦技巧”,直接提升视觉理解精度。
2. 数据不够?知识蒸馏来凑
无需海量标注数据,直接从图像生成模型中蒸馏视觉知识,堪称“小样本学习神器”。正如论文团队调侃:“这大概就是AI界的‘名师一对一补习班’。”
3. 防过拟合Buff:LoRA+注意力约束
通过低秩适配(LoRA)锁定核心参数,避免模型“死记硬背”。实验显示,Lavender在分布外任务上的鲁棒性吊打传统SFT方法,具备“抗偏科体质”。
另外,从具体应用场景来看,Lavender的视觉理解能力直接拉满。
无论是表格标题还是图表里的小数据点,Lavender都能一眼锁定关键信息,不会“偏题”;且对于复杂图形、大小位置关系,Lavender也能避免视觉误导,轻松拿捏。
实验显示,从医学病灶定位到多语言问答,Lavender不仅看得准,还答得对,连西班牙语提问都难不倒它。

目前,团队不仅公开了论文,代码/模型/训练数据也全部开源了。
对于上述研究,团队负责人表示:
我们希望证明,高效、轻量的模型优化,比无脑堆参数更有未来。
论文:
https://arxiv.org/abs/2502.06814
项目主页:
https://astrazeneca.github.io/vlm/
文章来自于“量子位”,作者“靳晨”。



