# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
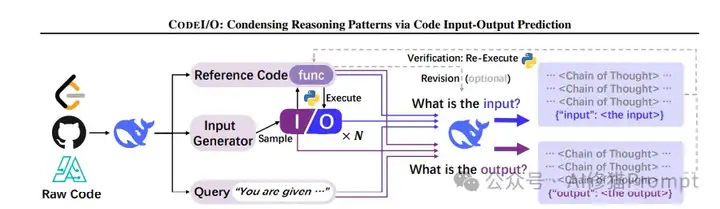
我们正见证一场静默的推理革命。传统AI训练如同盲人摸象,依赖碎片化文本拼凑认知图景,DeepSeek-AI团队的CODEI/O范式首次让机器真正"理解"了推理的本质——它将代码执行中蕴含的逻辑流,转化为可解释、可验证的思维链条,犹如为AI装上了解剖推理过程的显微镜。
这种以代码I/O为训练基石的创新,颠覆了自然语言处理的传统路径。通过双向预测机制,模型不仅掌握"给定问题求解答"的正向推理,更习得"根据结果溯原因"的逆向思维,展现出惊人的泛化能力。更革命性的是,其内置的验证闭环让AI首次实现了"知行合一",代码执行结果即时反馈修正推理偏差,构建起从认知到实践的完整回路。这个方法的优势在于可扩展性强、通用性好、可验证性强、迁移性强,为提升大语言模型的推理能力提供了一个新的思路。我在smolagents上也发现了这些特征。
传统AI训练依赖碎片化的文本数据,而CODEI/O首次将代码视为结构化推理模式的天然载体。其核心原理在于:通过代码输入输出(I/O)预测任务,将程序中的逻辑流(如递归分解、状态转移、分支决策)解耦为自然语言链式推理(CoT)。例如,一个动态规划算法的代码片段,可能隐含"问题分解-状态定义-转移方程构建"的通用推理链条。CODEI/O通过让模型预测输入(如参数组合)或输出(如函数返回值),强制其用自然语言还原代码背后的逻辑步骤,而非直接生成代码语法。

以找零钱问题为例:
defchange_ref(amt, coins):
if amt <= 0: return0
if amt != 0andnot coins: returnfloat("inf")
elif coins[0] > amt: return change_ref(amt, coins[1:])
else:
use_it = 1 + change_ref(amt - coins[0], coins)
lose_it = change_ref(amt, coins[1:])
returnmin(use_it, lose_it)
给定输入amt=25, coins=[1,4,7],模型需要通过分析可能的硬币组合,推理出最少需要4个硬币。反之,给定输出"4个硬币",模型需要反向推理出可能的输入组合,如amt=13, coins=[1,2,5]。这种双向预测任务迫使模型掌握通用的推理模式。
在传统的算法实现中,代码往往被简单视为实现功能的工具。而CODEI/O的革新之处在于,它看到了代码中蕴含的推理模式。以找零钱问题为例,通过smolagents框架的实现,我们可以清晰地看到这种推理模式的三个关键特征:
1.推理过程的去语法化表达
2.双向推理能力的体现
3.推理过程的完全透明化
smolagents框架在实现这些特征时展现出了独特的创新。它通过巧妙的设计实现了验证闭环,使预测结果能够通过代码执行立即验证,错误预测能够及时发现和纠正,形成了预测、验证、优化的完整循环。更重要的是,它建立了一个反馈机制,将执行结果直接反馈给模型,支持模型的自我修正和优化,从而不断增强推理能力。

在技术实现层面,smolagents框架的创新主要体现在两个方面:
1.统一的推理框架设计
2.智能代理的抽象设计
这种设计在找零钱问题中展现出显著的效果。我们看到,框架成功地将动态规划的递推关系转化为清晰的推理链,支持复杂问题的分解和重组,展示了代码与推理的深度融合。同时,通过推理过程的完全可视化和决策依据的透明展示,大大提升了系统的可解释性,为理解和优化问题解决过程提供了有力支持。
与传统代码训练相比,CODEI/O有三大革新:
实验数据显示,经过CODEI/O训练的模型在GSM8K数学推理任务中准确率提升9.2%,在逻辑谜题(ZebraLogic)中提升17.8%,证明其推理能力的泛化性。
面向Agent工程师,CODEI/O的落地需关注以下技术要点:
defstrict_check_size(obj):
# 使用pympler检查对象大小
if asizeof.asizeof(obj) >= 1024:
returnFalse
# 递归检查复合类型
ifisinstance(obj, dict):
iflen(obj) >= 20: returnFalse
for k, v in obj.items():
ifnot strict_check_size(k) ornot strict_check_size(v):
returnFalse
# 限制字符串长度
elifisinstance(obj, str):
iflen(obj) >= 100: returnFalse
returnTrue
defproc_main(data, good_cnt, bad_cnt, num_process, num_thread):
# 创建线程池
with ThreadPoolExecutor(max_workers=num_thread) as executor:
futures = []
# 分配任务
for i inrange(process_i, len(data), num_process):
future = executor.submit(process_line, data[i])
futures.append(future)
# 等待完成
for future in concurrent.futures.as_completed(futures):
future.result()
defprocess_line(js):
for i inrange(max_try_one_call):
try:
response = call_api(js)
break
except Exception:
if i < max_try_one_call-1:
time.sleep(5)
return response
某电商定价策略代码的转换示例:
defcalculate_discount(base_price, user_level, inventory):
if user_level == 'VIP': discount = 0.2
elif inventory > 100: discount = 0.15
else: discount = 0.1
return base_price * (1 - discount)
对应训练样本的CoT可能包含:"VIP用户触发20%折扣→库存超100件追加15%→最终价格=原价×(1-折扣)"的决策树推理过程。
在保险理赔、金融风控等领域,业务规则常以代码形式固化。CODEI/O可将这些规则转化为可解释的推理链:
某车险系统实测显示,基于CODEI/O的Agent在规则变更后,测试用例生成效率提升4倍。
传统数值计算模型(如流体力学仿真)存在"黑箱"问题。通过代码逆向推理:
defsimulate_flow(viscosity, pressure):
# 复杂偏微分方程求解
return velocity_field
模型可输出:"高粘度导致层流→压力梯度与速度呈非线性关系→输出流场分布"的物理推理过程,帮助工程师理解计算逻辑。
某API测试平台集成CODEI/O后,单元测试覆盖率从78%提升至93%。
CODEI/O++的核心创新在于引入执行反馈驱动的迭代优化:
以最短子数组问题为例:
实验表明,多轮修订使CRUXEval基准准确率再提升6.4%,且错误样本的保留增强了模型抗干扰能力。
CODEI/O与当前热门的推理时扩展技术(如DeepSeek R1)存在天然互补性:
在数学证明题中,这种组合使步骤完整性提升40%,同时保持逻辑连贯性。
针对中小企业的落地需求,可实施:
CODEI/O不仅是一种训练方法,更是重新定义AI推理能力的技术框架。它将代码的执行逻辑转化为人类可理解的推理模式,在保持程序严谨性的同时,解锁了跨领域的泛化能力。
1.数据获取成本低
2.推理过程可验证
3.迁移能力强
4.可持续改进
1.数据质量依赖
2.计算资源要求
3.泛化性待验证
对于Agent工程师而言,掌握CODEI/O意味着获得一把打开复杂系统逻辑黑箱的钥匙——无论是优化现有产品的决策模块,还是构建新一代自主推理Agent,这都将是不可或缺的核心竞争力。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
