# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
该篇文章为:100% HWC(Human-Written Content)100% 人类创作内容。
(没有任何人工智能生成的内容)
自从开始了 Easier Life 这个项目后,我每天都有很多新奇的想法。
说好每两周要做一个产品,没想到第二个就“失败”了。
但我非常喜欢这次“失败”。
这个项目叫做“废话检测器”(Word Salad Detector),来源于年前不断参加的各种论坛、峰会。
在听大部分“专家”分享的时候,我往往只有一个感叹:
他们的废话真TM多呀!!!
所以就开始设想一个有趣的场景,如果在未来,每一次的论坛、每一次嘉宾、专家、学者的发言,都有一个像实时弹幕一样的机器/系统,在其每次发言之后都可以给发言者打一个分:
TA 的废话指数是 XXX!TA 的废话实在是太多啦!
这就好像:
我们的生活中充满着各式各样的“废话”。
(英文用了 Word Salad,比如 Kamala Harris 的每一次发言 )
所以,我就想做一款“废话检测器”。
我的第一个想法其实是 Chrome Extension (谷歌浏览器插件)。
设想的场景大概就是,我打开任何一个网页,或者选择任何一段文字,在这个插件上点一下,它就可以给我判定选中内容的“废话程度”。
事实上,我也做出来了:(调用了 Gemini 的 API)
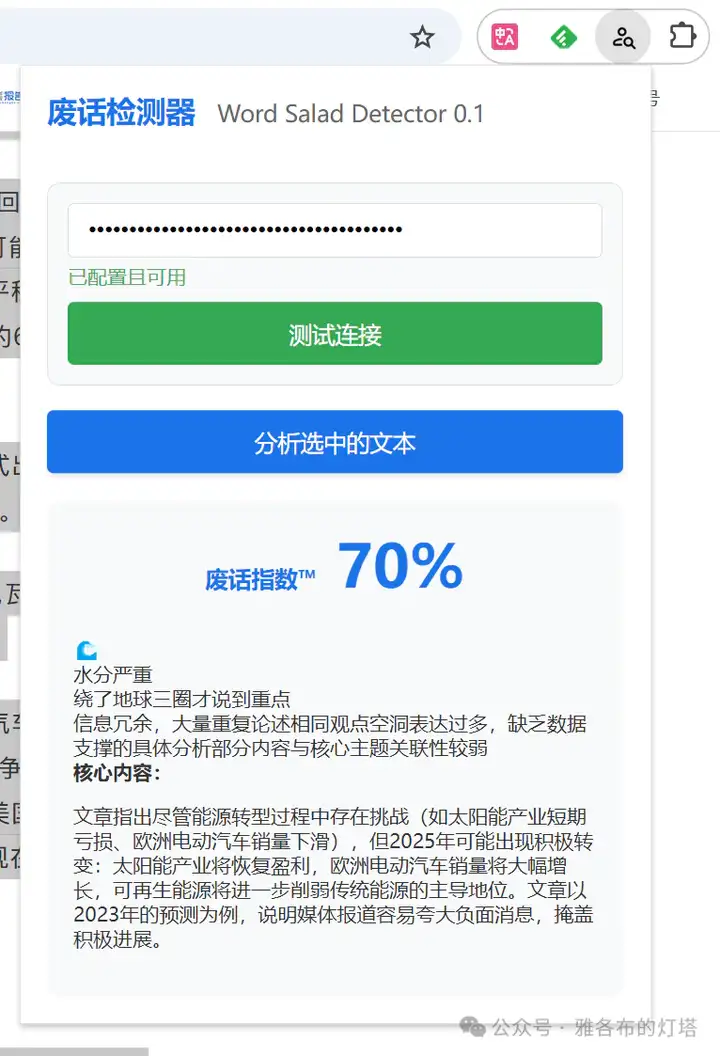
然后问题就来了。
似乎我在这时才意识到,在 Prompt 里写上“检测这段话的废话指数”这个指令,本身是多么虚无缥缈。
再仔细一想,我们人脑是如何判断一段话有没有“废话”的呢?
在这个时候,我就搁置了这个 Extension 的开发。
转而尝试去撰写一个 prompt ,或者说,是一个“废话推理”的模型。
(此处手动感谢并致敬 thinking claude 给我带来的启发)
在一顿操作猛如虎(分别和 deepseek、gpt、claude 对话学习并综合他们的想法)后,我首先总结了一些(看起来挺专业的)判断废话的理论基础:

其次,延展出了判断废话的 6 大维度:

是不是看起来还挺有道理的?
我信心满满,将其写成 markdown,然后上传 github,成为了我人生的第一个 github 项目。(骄傲)
(完整 protocol/prompt 可在 github 页面下载并尝试:https://github.com/jacobtantyx/word_salad_detector)
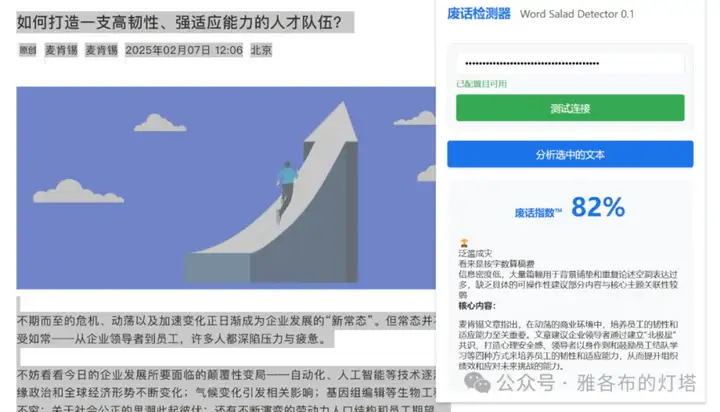
然后,满心期待地,开始了我的测试。

是不是感觉还行?

但在测试了好几轮之后,我意识到一个问题。
一篇在我看来几乎没有废话的专业文档,和一篇在我看来废话连篇的领导发言,在这个 protocol 下的分数并没有差别很大,往往只是 12/100 (极少废话)与 22(很少废话)的差别。
我就此,开启了漫长的调试过程。
但最终不是分数特别集中,就是分数和人脑预期不准确。
这不禁让我思考,在 AI 可以做这么多事情的今天,它真的可以有效地判断废话程度吗?
以及,有没有可能,这个议题,恰恰也在触及自然语言处理领域最本质的挑战之一:
如何量化语言的实质价值?
这就代表着,这个问题的复杂性远超表面。
这就比如,一个朋友为了安慰我,说了将近1个小时的长故事,但可能他就只有一个观点。这并不代表这一个小时的长故事就是废话。
以及,同一文本在不同语境中的废话判定也有可能不同,因为受众专业知识水平与废话感知大概率是负相关的。
当然,更别说,在大部分情况下,发言者权威光环效应使废话容忍度提升好几倍。 (比如有的专家似乎没说什么,但因为TA是某某某,大家就会觉得TA讲得好有道理呀)
那么,“废话”或许不是一个纯语言或纯信息层面的问题,而是带有“主观期待”与“语用功能”的评价色彩。许多领导讲话之所以被认为“废话很多”,是因为听众期待他们“给出关键解答”,却发现他们反复在打官腔、说场面话或空洞口号。
这种“期待落差”是废话感产生的关键。
所以,在额外尝试了将近 4 小时后。
我毅然停止了“废话检测器”这个想法,接受了我的“失败”。
我原本对“废话检测器”的期望,正是对“空洞发言/长段套话”深恶痛绝的一种表达。
但或许这个项目的终极价值不在于构建完美的废话检测器(尽管我认为各大论坛真的很需要它),而在于它像苏格拉底式的“牛虻”,不断刺痛我们的神经:
1. 当AI开始评判人类语言的价值,是否在重构知识权力体系?
2. 在算法定义的“效率”面前,语言的诗意与留白是否面临生存危机?
3. 我们是否正在用机器逻辑解构人类话语的复杂生态系统?
本文来自微信公众号:雅各布的灯塔,作者:雅各布的灯塔




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
