# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
在近期的一次演讲中,他将自己的观点总结成了「四个放弃」:放弃生成式模型、放弃概率模型、放弃对比方法、放弃强化学习。他给出的研究方向建议则是联合嵌入架构、基于能量的模型、正则化方法与模型预测式控制。他还表示:「如果你感兴趣的是人类水平的 AI,那就不要研究 LLM。」

总之,他认为有望实现 AGI 或「人类水平的人工智能」的方向是世界模型(World Model),其领导的团队也一直在推进这方面的研究工作,比如基于 DINO 的世界模型(DINO-WM)以及一项在世界模型中导航的研究。
近日,Yann LeCun 团队又发布了一项新研究。他们发现,只需在自然视频上进行自监督预训练,对物理规则的直觉理解就会涌现出来。似乎就像驴一样,通过观察世界,就能直觉地找到最轻松省力的负重登山方法。
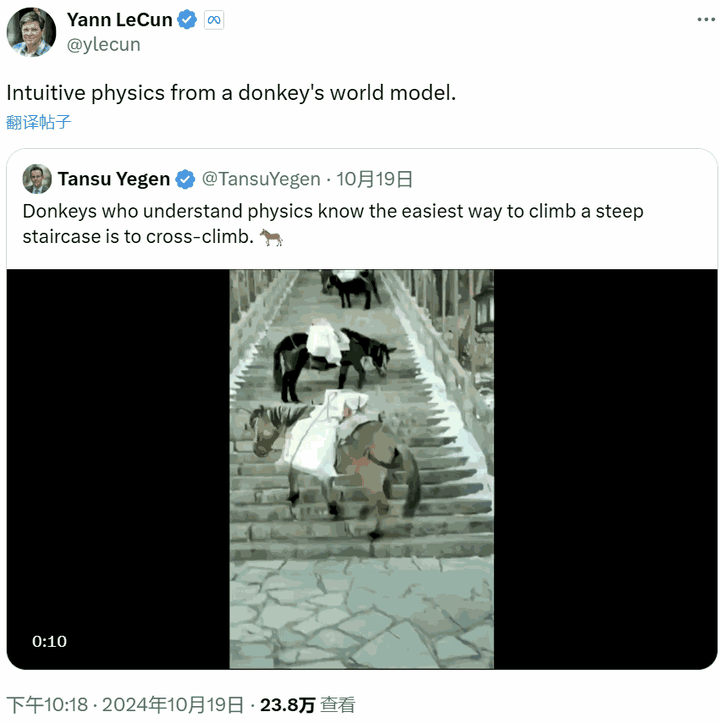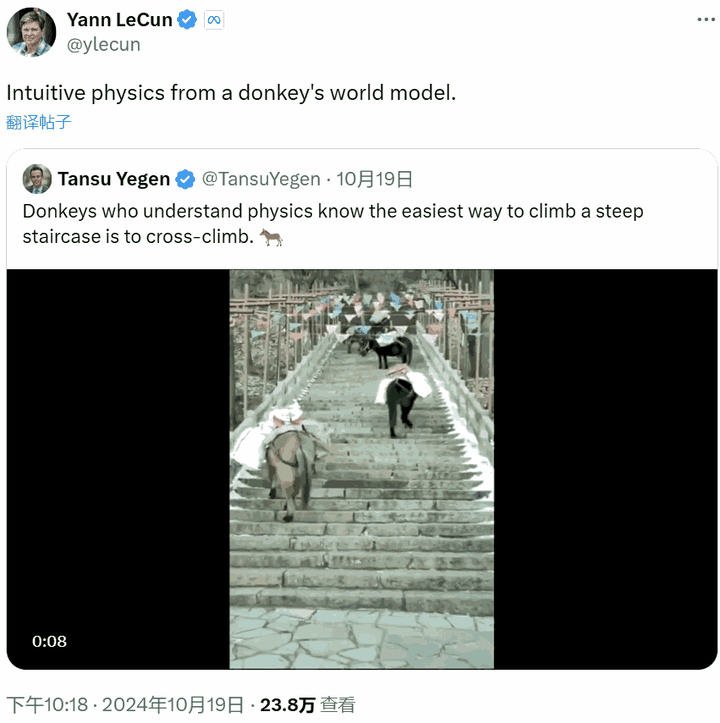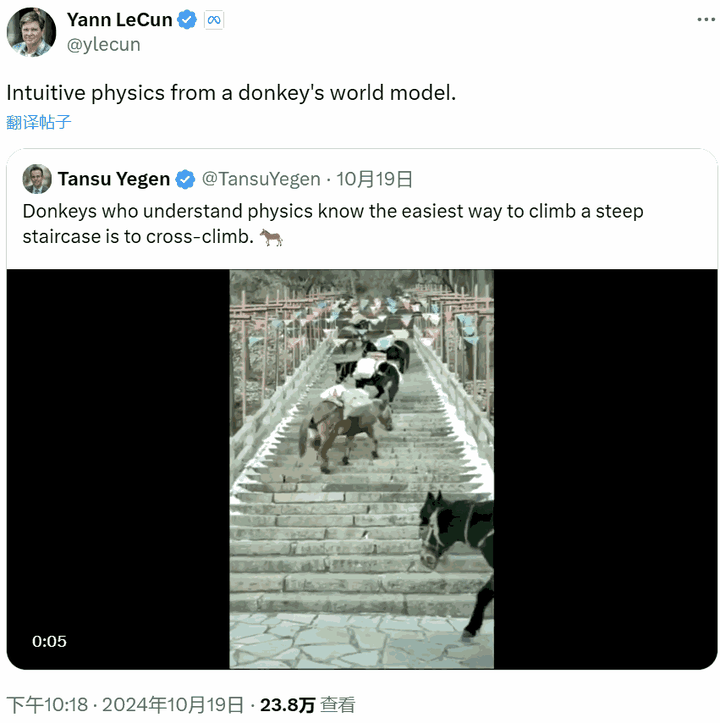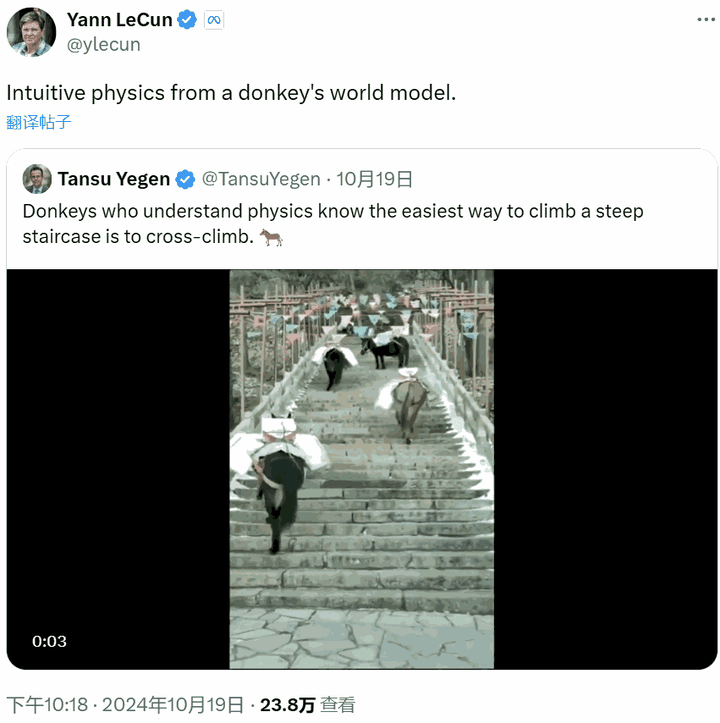


要理解这篇论文,我们首先需要明确一下什么才算是「直觉物理理解」。这篇论文写到,对物理规则的直觉理解是人类认知的基础:我们会预期事物的行为方式是可预测的,比如不会凭空出现或消失、穿透障碍物或突然改变颜色或形状。
这种对物理世界的基本认知不仅在人类婴儿中有所记录, 在灵长类动物、海洋哺乳动物、鸦科鸟类和雏鸡中也有所发现。这被视为核心知识(或核心系统)假说的证据,根据该假说:人类拥有一套与生俱来或早期进化发展的古老计算系统,专门用于表示和推理世界的基本属性:物体、空间、数字、几何、agent 等。
在追求构建具有高级人类智能水平的机器的过程中,尽管 AI 系统在语言、编程或数学等高级认知任务上经常超越人类表现,但在常识性物理理解方面却显得力不从心,这体现了莫拉维克悖论,即对生物有机体来说微不足道的任务对人工系统来说可能异常困难,反之亦然。
旨在改善物理直觉理解的 AI 模型的先前研究可以分为两类:结构化模型和基于像素的生成模型。
在新论文中,LeCun 等人探索了第三类模型 —— 联合嵌入预测架构(JEPA),它在这两种对立观点之间找到了中间立场,整合了两者的特征。
与结构化模型一样,JEPA 认为对未来世界状态的预测应该在模型的学习抽象、内部表示中进行,而不是在低级的、基于像素的预测或生成方面进行。然而,与结构化模型不同,JEPA 让算法自行学习其表示,而不是手工编码。这种在表示空间中进行预测的机制与认知神经科学的预测编码假说相一致。
新论文研究了该架构的视频版本,即 V-JEPA,它通过在表示空间中重建视频的被掩蔽部分来学习表示视频帧。
该研究依赖于预期违反(violation-of-expectation)框架来探测物理直觉理解,而无需任何特定任务的训练或适应。通过提示模型想象视频的未来(表示)并将其预测与实际观察到的视频的未来进行比较,可以获得一个定量的意外度量(measure of surprise),该度量可用于检测违反直观物理概念的情况。
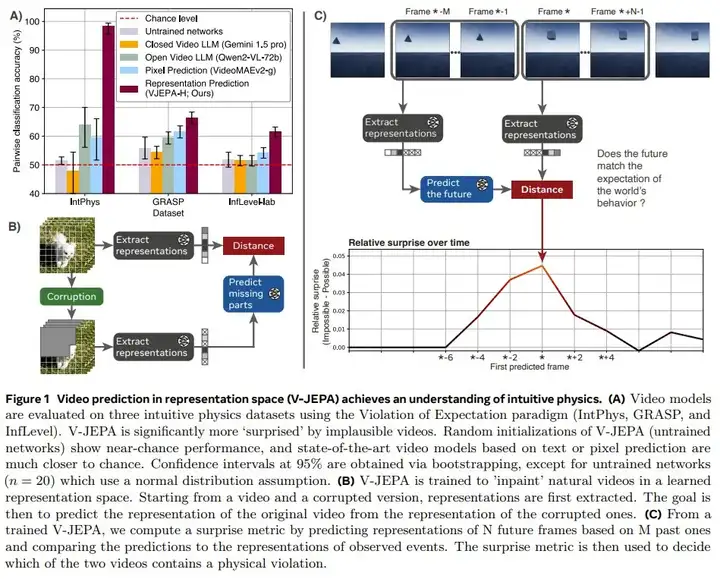
研究发现 V-JEPA 能够准确且一致地区分遵循物理定律的视频和违反物理定律的视频。
具体来说,当被要求对视频对的物理合理性进行分类时(其中一个视频是合理的,另一个不是),在自然视频上训练的 V-JEPA 模型在 IntPhys 基准测试上达到了 98% 的零样本准确率,在 InfLevel 基准测试上达到了 62% 的零样本准确率。令人惊讶的是,研究发现多模态大语言模型和在像素空间中进行预测的可比较视频预测方法都是随机执行的。
为了更好地理解哪些设计选择导致了 V-JEPA 中物理直觉理解的涌现,LeCun 等人消融了训练数据、预训练预测目标(从什么预测什么)和模型大小的影响。虽然观察到改变这些组件中的每一个都会影响性能,但所有 V-JEPA 模型都达到了显著高于随机水平的性能,包括一个小型的 1.15 亿参数模型,或者仅在一周独特视频上训练的模型,这表明在学习表示空间中进行视频预测是获得物理直觉理解的一个稳健目标。
测量直觉物理理解中的预期违反
预期违反范式源自发展心理学。研究对象(通常是婴儿)会看到两个相似的视觉场景,其中一个包含物理上不可能的情况。然后,研究者通过各种生理指标(如相对注视时间)获取对每个场景的「感到意外」反应,用以确定研究对象是否感受到了概念违反。
这一范式已经扩展到评估 AI 系统的物理理解能力。类似于婴儿实验,向模型展示成对的场景,除了违反特定直觉物理概念的某个方面或事件外,两个场景的所有方面(物体属性、物体数量、遮挡物等)都保持相同。例如,一个球可能会滚到遮挡物后面,但在配对的视频中再也不会出现,从而测试物体持久性的概念。模型对不可能场景表现出更高的意外反应,反映了其对被违反概念的正确理解。
用于直觉物理理解的视频预测
V-JEPA 架构的主要开发目的是提高模型直接从输入适应高层级下游任务的能力,如活动识别和动作分类,而无需硬编码一系列中间表示,如物体轮廓或姿态估计。
在这项研究中,研究团队测试了一个假设:该架构之所以在高层级任务上取得成功,是因为它学习到了一种隐式捕捉世界中物体结构和动态的表示,而无需直接表示它们。
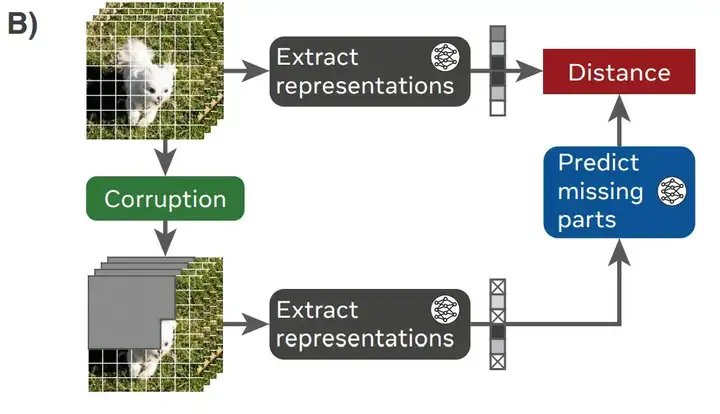
如图 1.B 所示,V-JEPA 由一个编码器(神经网络)和一个预测器(也是神经网络)构成。编码器从视频中提取表示,预测器预测视频中人为掩蔽部分的表示,如随机掩蔽的时空块、随机像素或未来帧。编码器和预测器的联合训练使编码器能够学习抽象表示,这些表示编码可预测的信息并丢弃低层级(通常语义性较低)特征。
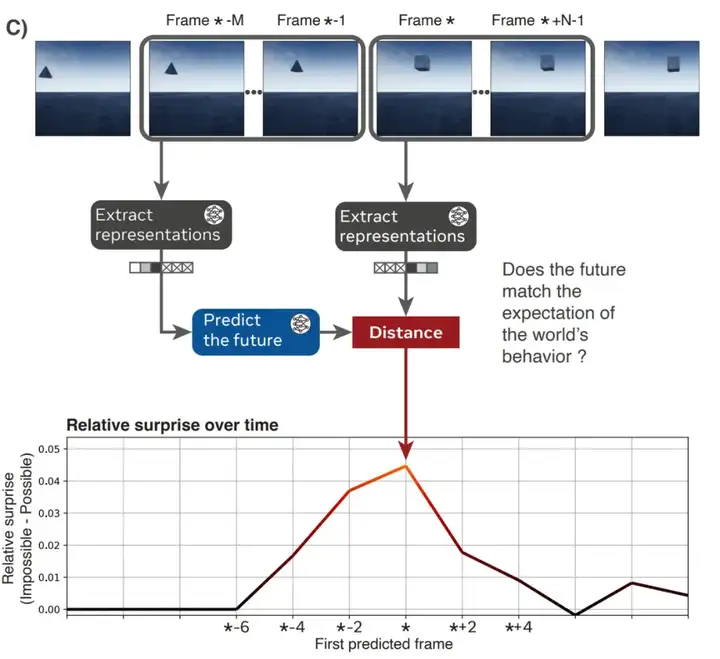
在自监督训练之后,可以使用编码器和预测器网络来探测模型对世界的理解,而无需任何额外的适应。具体来说,在遍历视频流时,模型对观察到的像素进行编码,随后预测视频后续帧的表示,如图 1.C 所示。通过记录每个时间步的预测误差(预测的视频表示与实际编码的视频表示之间的距离),可以获得模型在整个视频中意外程度的时间对齐定量度量。通过改变模型可以用来预测未来的过去视频帧数(上下文),可以控制记忆因素;通过改变视频的帧率,可以控制动作的精细程度。
研究团队在三个数据集上评估了直觉物理理解能力:IntPhys 的开发集、GRASP 和 InfLevel-lab。这些数据集的组合使研究团队能够探测各类方法对物体持久性、连续性、形状和颜色恒常性、重力、支撑、固体性、惯性和碰撞的理解。
研究团队将 V-JEPA 与其他视频模型进行了比较,以研究视频预测目标以及执行预测的表征空间对直觉物理理解的重要性。研究团队考虑了两类其他模型:直接在像素空间进行预测的视频预测模型和多模态大语言模型(MLLM)。
对于考虑的每种方法,研究团队评估了原始工作中提出的旗舰模型。研究团队进一步将所有模型与未训练的神经网络进行比较,测试直觉物理理解的可学习性。
图 1.A 总结了各方法在成对分类(即在一对视频中检测不可能的视频)中跨数据集的性能。
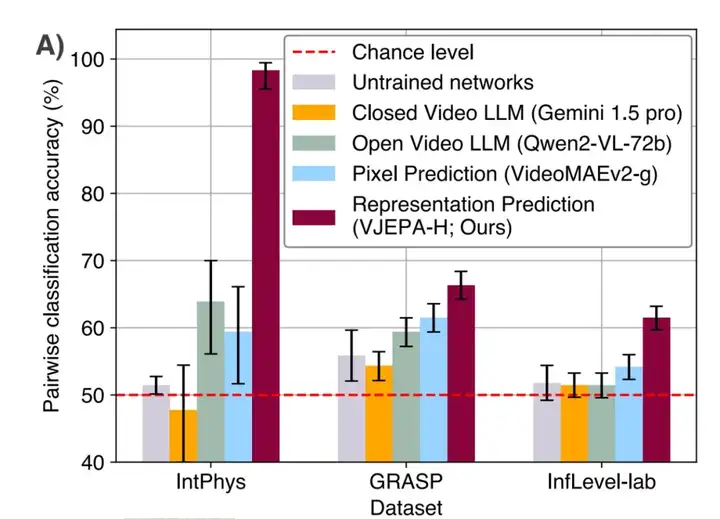
研究团队发现,V-JEPA 是唯一一个在所有数据集上都显著优于未训练网络的方法,在 IntPhys、GRASP 和 InfLevel-lab 上分别达到了 98%(95% CI [95%,99%])、66%(95% CI [64%,68%])、62%(95% CI [60%,63%])的平均准确率。这些结果表明,在学习到的表征空间中进行预测足以发展出对直觉物理的理解。这是在没有任何预定义抽象,且在预训练或方法开发过程中不知道基准的情况下实现的。
通过比较,该团队发现,VideoMAEv2、Qwen2-VL-7B 和 Gemini 1.5 pro 的性能仅略高于随机初始化模型。像素预测和多模态 LLM 的低性能证实了先前的一些发现。
该团队表示:「这些比较进一步凸显了 V-JEPA 相对于现有 VideoMAEv2、Gemini 1.5 pro 和 Qwen2-VL-72B 模型的优势。然而,这些结果并不意味着 LLM 或像素预测模型无法实现直观的物理理解,而只是意味着即使对于前沿模型来说,这个看似简单的任务仍然很困难。」
接下来,为了更准确地理解 V-JEPA 的直观物理理解,该团队仔细研究了其在先前使用的数据集上的各属性性能。在这里,V-JEPA 编码器和预测器基于 Vision Transformer-Large 架构,并在 HowTo100M 数据集上进行了训练。结果见下图 2。
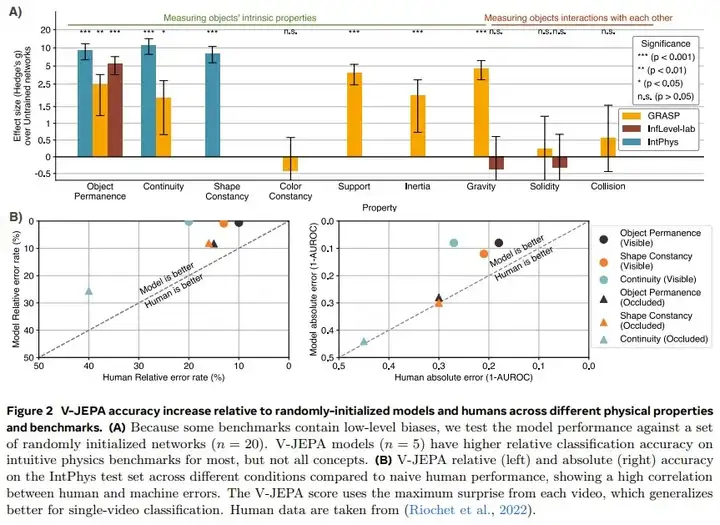
可以看到,在 IntPhys 上,V-JEPA 在多个直观物理属性上的表现都明显优于未经训练的网络,其中包括物体持久性、连续性、形状恒常性。
在 GRASP 上,V-JEPA 也在物体持久性、连续性、支撑结构、重力、惯性方面有显著更高的准确度。不过 V-JEPA 在流体和碰撞等方面优势不显著。
总结起来,V-JEPA 在与场景内容相关的属性方面表现出色,但在需要了解情境事件或精确物体交互的类别方面却颇为困难。该团队猜想,这些限制主要来自模型的帧速率限制。尽管如此,V-JEPA 展现出了直觉物理理解能力,同时可从原始感知信号中学习所需的抽象,而无需依赖于强大的先验信息。不同于之前的研究,这表明,要让深度学习系统理解直觉物理概念,核心知识并不是必需的。
更进一步,该团队使用来自 IntPhys 的私有测试集将 V-JEPA 与人类表现进行了比较。这次实验使用了旗舰 V-JEPA 架构,即使用 ViT-Huge 并在 VideoMix2M 上进行预训练。结果发现 V-JEPA 在所有直观物理属性上都实现了相同或更高的性能,如图 2.B 所示。
该团队发现,如果在视频中使用最大意外值而不是平均意外值,可以在单个视频上获得更好的性能。
一般来说,当打破物理直觉的事件发生在遮挡物后面时,V-JEPA 和人类的性能都较低。此外,在遮挡设置下,人类和 V-JEPA 之间的性能具有很好的相关性。
最后,该团队也研究了掩码类型、训练数据的类型和数量、模型大小对 V-JEPA IntPhys 分数的影响,结果如下。
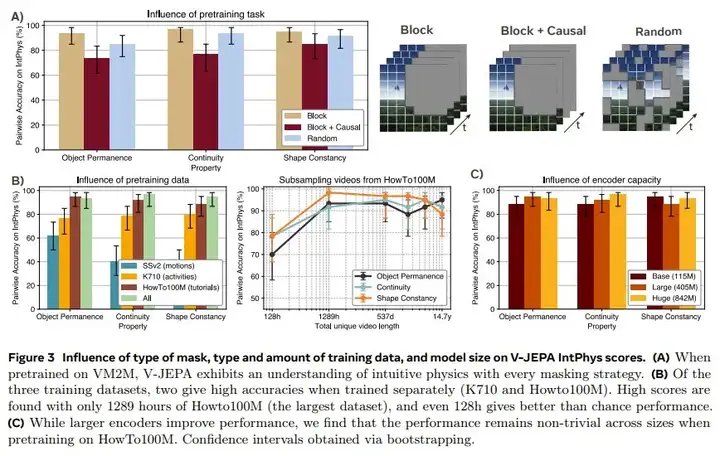
详细的具体分析和讨论请阅读原论文。
文章来自于“机器之心”,作者“Panda、张倩”。




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
