# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
查询扩展 (Query Expansion) ,这股风潮又刮回来了!作为曾经搜索的标配,后来一度沉寂,在今天推理式搜索 (Agentic Search) 的浪潮下,查询扩展又重新回到了聚光灯下。
做过 Agentic Search (比如 DeepSearch/DeepResearch) 的朋友肯定深有体会,用户直接输入的查询词,要么太笼统,不够聚焦;要不就太细碎,不够全面。这让那些依赖关键词匹配或者结构化数据的 Agentic 工具很难精准处理。
因此,我们需要对用户查询进行扩展或重写,让它们更符合搜索语境,更具发散性,既能覆盖足够多的信息,又能深入挖掘潜在关联。
00:33

最初,查询扩展是为那些靠关键词匹配来判断相关性的搜索系统设计的,比如 tf-idf 或其他稀疏向量方案。
这类方法有些天然的缺陷:词语稍微变个形式,像 "ran" 和 "running",或者 "optimise" 和 "optimize",都会影响匹配结果。虽然可以用语言预处理来解决一部分问题,但远远不够。技术术语、同义词和相关词就更难处理了。举个例子,如果搜索 "coronavirus" 相关的医学研究,系统很可能找不到包含 "COVID" 或 "SARS-CoV-2" 的文档,但它们明明也高度相关。
查询扩展就是为了解决这些问题而生的。
它的思路其实很简单:往原始查询里加一些相关的词,提高找到优质结果的概率。比如,搜索 "coronavirus",可以自动加上 "COVID" 和 "SARS-CoV-2" 这些词,这样搜出来的结果质量就能大大提高。
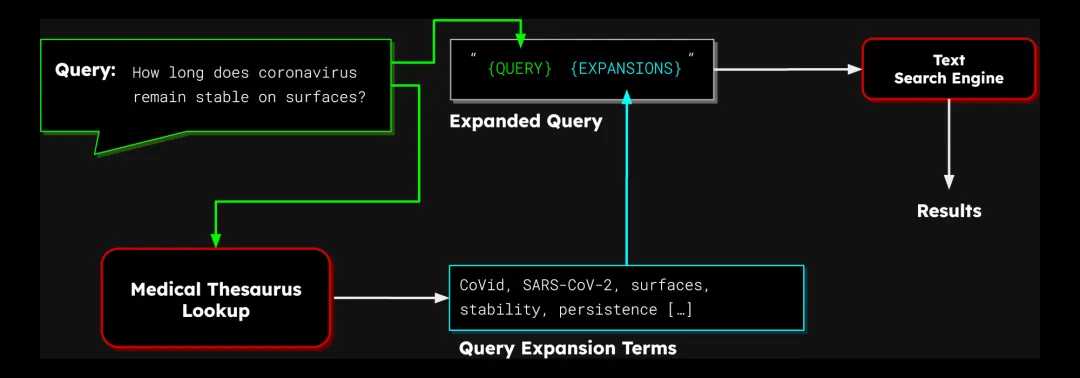
图 1:使用同义词典的查询扩展流程图
不过,到底该往查询里加哪些词,可不是一件容易的事儿。之前有不少研究,专门教你识别好的词,以及如何给 tf-idf 风格的检索赋予权重。常用的方法包括:
理论上讲,有了语义向量模型,应该就不需要查询扩展了。"coronavirus"、"COVID" 和 "SARS-CoV-2" 这些词的向量应该非常接近,可以自然匹配,不需要额外做任何增强。
但现实情况是,向量模型往往达不到理想效果,向量里的词可能含义模糊不清。因此,在查询中加入一些合适的词,反而能帮助模型更精准地找到目标答案。
举个例子,如果你搜索 "skin rash" (皮疹),系统可能会搜出来 "behaving rashly" (轻率行事) 和 "skin creme" (润肤霜) 这种不太相关的结果,但却漏掉了讨论 "dermatitis" (皮炎) 的医学期刊文章。如果加上 "dermatitis" 这个词,就能让向量远离那些不相关的结果,找到更靠谱的答案。
除了传统的同义词词典和词法挖掘,我们还探索了使用 LLM(大型语言模型)来进行查询扩展。LLM 有几个显著优势:
1. 词汇量巨大:毕竟 LLM 是在海量数据上训练出来的,不用担心找不到合适的同义词,或者没数据可用。
2. 具备一定的判断力:不是所有扩展词都适合所有查询。虽然 LLM 不可能完美判断主题相关性,但它至少能做一些初步的筛选,而传统方法根本没这个能力。
3. 灵活,可定制:你可以根据具体的搜索任务,调整给 LLM 的提示词。相比之下,传统方法就比较死板了,想适配新的领域或者数据源,往往得费老大劲。
当 LLM 生成一个扩展词列表后,接下来的流程就和传统的查询扩展差不多了:把这些词加到原始查询文本里,然后用向量模型生成查询向量。
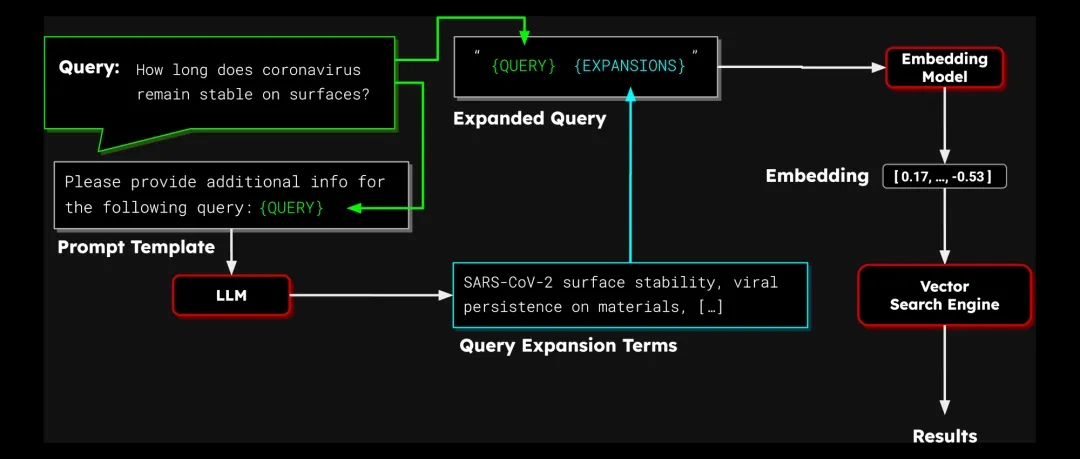
图 2:使用 LLM 的向量查询扩展
要实现基于 LLM 的查询扩展,你需要一个可用的 LLM 服务,一套提示词模板,用来引导 LLM 生成扩展词,以及一个文本向量模型。
为了测试 LLM 辅助查询扩展到底有没有用,我们进行了一系列实验。测试环境如下:
实验中,我们采用了两种提示词策略,一种是通用的提示词模板,另一种是针对特定任务设计的提示词模板。
另外,我们还测试了不同数量的扩展词:分别是 100 个、 150 个和 250 个。
所有代码和实验结果都开源了,欢迎大家围观和复现
:
🔗 llm-query-expansion: https://github.com/jina-ai/llm-query-expansion/
经过反复试验,我们发现以下提示词在 Gemini 2.0 Flash 上效果不错:
Please provide additional search keywords and phrases for
each of the key aspects of the following queries that make
it easier to find the relevant documents (about {size} words
per query):
{query}
Please respond in the following JSON schema:
Expansion = {"qid": str, "additional\_info": str}
Return: list \[Expansion\]
这个提示词模板支持批量处理查询,每批 20-50 个,并为每个查询分配一个 ID。它返回一个 JSON 字符串,将每个查询与其对应的扩展词列表关联起来。但如果你使用不同的 LLM,可能需要调整提示词以达到最佳效果。
我们首先使用 jina-embeddings-v3 及其非对称检索适配器进行了测试。这种方法对查询和文档采用不同的方式编码(实际上是用同一个模型,但是用了不同的 LoRA 适配器),从而优化信息检索的向量效果。
下表展示了在不同 BEIR 基准测试上的结果(评分指标为 nDCG@10,即前 10 个检索项的归一化折扣累积增益):
测试集无扩展词100 个拓展词150 个拓展词250 个拓展词SciFact (事实核查任务)72.7473.3974.1674.33TRECCOVID (医疗检索任务)77.5576.7477.1279.28FiQA (金融期权检索)47.3447.7646.0347.34NFCorpus (医疗信息检索)36.4640.6239.6339.20Touche2020 (论点检索任务)26.2426.9127.1527.54
从结果可以看出,在大多数情况下,查询扩展都能提升检索效果。
为了验证该方法的稳健性,我们使用 all-MiniLM-L6-v2(一个能生成更小的向量向量的小型模型)重复了相同的测试。
all-MiniLM-L6-v2: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
结果如下表所示:
测试集无扩展词100 个拓展词150 个拓展词250 个拓展词SciFact (事实核查任务)64.5168.7266.2768.50TRECCOVID (医疗检索任务)47.2567.9070.1869.60FiQA (金融期权检索)36.8733.9632.6031.84NFCorpus (医疗信息检索)31.5933.7633.7633.35Touche2020 (论点检索任务)16.9025.3123.5223.23
从结果可以看出,查询扩展对检索分数有显著提升,尤其对于较小的模型,效果更为明显。下表总结了各模型在所有任务上的平均提升幅度:
模型100 拓展词150 拓展词250 拓展词jina-embeddings-v3+1.02+0.75+1.48all-MiniLM-L6-v2+6.51+5.84+5.88
all-MiniLM-L6-v2 的提升幅度远大于 jina-embeddings-v3,这可能是因为前者初始性能较低。jina-embeddings-v3 在非对称检索模式下能更好地捕捉查询中的语义关系,因此查询扩展所能提供的额外信息空间相对较小。但这个结果也表明,查询扩展能显著提升紧凑型模型的性能,使其在某些场景下更具竞争力。
虽然查询扩展对 jina-embeddings-v3 这样的高性能模型也有一定改进,但并非在所有任务和条件下都有效。
对于 jina-embeddings-v3,在 FiQA 和 NFCorpus 基准测试中,添加超过 100 个词反而会降低性能,说明并非词越多越好。 其他基准测试的结果则表明,在某些情况下,更多词项能够带来更好的效果。
对于 all-MiniLM-L6-v2,添加超过 150 个词项也总是会降低性能,在三个测试中,添加超过 100 个词项也没有提高分数。在 FiQA 测试中,即使只添加 100 个词项,结果也明显下降。我们认为这是因为 jina-embeddings-v3 在处理较长的查询文本时,能更好地捕捉其中的语义信息。
但两个模型在 FiQA 和 NFCorpus 基准测试中对查询扩展的响应都不太积极。
前面的实验结果显示,尽管查询扩展总体上有所帮助,但直接使用 LLM 可能会引入一些噪声词汇,反而拉低了检索效果。这很可能因为我们之前使用的通用提示词不够精准。
因此,我们决定聚焦 SciFact 和 FiQA 这两个数据集,并分别设计了更具领域针对性的提示词:
Please provide additional search keywords and phrases for
each of the key aspects of the following queries that make
it easier to find the relevant documents scientific document
that supports or rejects the scientific fact in the query
field (about {size} words per query):
{query}
Please respond in the following JSON schema:
Expansion = {"qid": str, "additional\_info": str}
Return: list \[Expansion\]
实验结果表明,这种定制化的提示策略几乎全面提升了检索性能:
测试集模型无拓展词100 拓展词150 拓展词250 拓展词SciFactjina-embeddings-v372.7475.85 (+2.46)75.07 (+0.91)75.13 (+0.80)SciFactall-MiniLM-L6-v264.5169.12 (+0.40)68.10 (+1.83)67.83 (-0.67)FiQAjina-embeddings-v347.3447.77 (+0.01)48.20 (+1.99)47.75 (+0.41)FiQAall-MiniLM-L6-v236.8734.71 (+0.75)34.68 (+2.08)34.50 (+2.66)
从上表可以看出,除了在 SciFact 上使用 all-MiniLM-L6-v2 并添加 250 个扩展词的情况外,所有设置下的分数都有所提高。然而,即便如此,这种改进仍然不足以让 all-MiniLM-L6-v2 在 FiQA 数据集上超越其原始性能。
对于 jina-embeddings-v3 我们发现添加 100 或 150 个扩展词的效果最佳;添加 250 个扩展词反而会带来负面影响。这进一步验证了我们之前的推测:一味地向查询中添加过多词汇可能适得其反,尤其当这些词汇偏离了核心语义时。
毋庸置疑的是,查询扩展能够提升基于向量的搜索效果。但与此同时,我们也需要正视以下几个关键问题:
1. 成本考量
与 LLM 交互会增加信息检索的延迟和计算开销。如果使用商业 LLM 服务,还会产生额外的费用。因此,我们需要仔细权衡,看这些性能提升是否能够抵消由此带来的成本增长。
2. 提示词工程
设计优秀的提示词模板并非易事,需要大量的实践和实验。我们也不认为本次实验中使用的提示词是最佳方案,更无法保证它们能够直接迁移到其他 LLM 上。我们在特定任务提示方面的实验已经表明,提示词的细微改变都可能对结果质量产生显著影响,并且不同领域之间的效果差异也很大。
这些不确定性无疑会增加开发成本,并降低系统的可维护性。一旦系统中的任何环节发生变化,比如更换 LLM、向量模型或信息领域,我们就需要对整个流程进行重新评估,甚至可能需要彻底重构。
3. 其他优化路径
本次实验结果表明,查询扩展对初始性能较差的向量模型带来了更显著的提升。但需要指出的是,即便使用了查询扩展,all-MiniLM-L6-v2 仍然无法追赶上 jina-embeddings-v3 的性能水平,而 jina-embeddings-v3 通过查询扩展获得的提升也相对有限。
在这种情况下,对于 all-MiniLM-L6-v2 的用户来说,直接升级到 jina-embeddings-v3能以更低的成本获得更好的搜索效果,而不是投入精力去做查询扩展。
文本的实验初步验证了,查询扩展确实能够优化向量搜索,以及 LLM 能够以一种简单而灵活的方式生成高质量的查询扩展词。但当前的效果提升还不够显著,还有不少工作要做。我们正在探索以下几个未来的研究方向:
虽然这是一项初步的研究,但我们对这项技术能在 Jina AI Search Foundation 里做进一步应用充满期待。
文章来自微信公众号 “ Jina AI “,作者 Jina AI



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
