# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
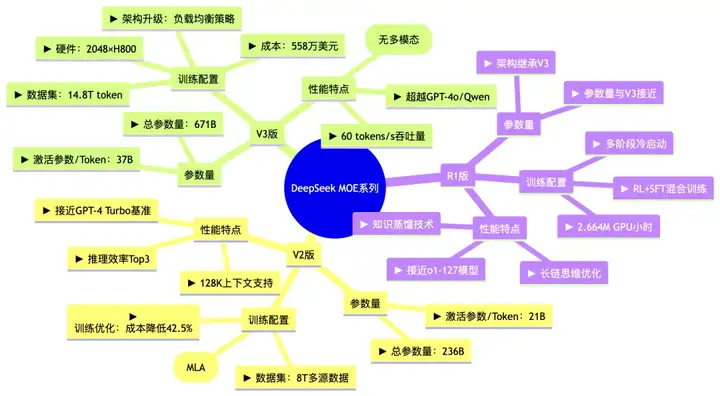
DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。
DeepSeek不同模型版本和显存占用情况
在部署之前,首先要根据自己设备的显存大小选择合适的DeepSeek模型版本。模型的参数规模、量化技术直接影响模型部署的显存要求,以下表格列举了DeepSeek-R1及其蒸馏模型的显存需求,以及推荐的GPU:
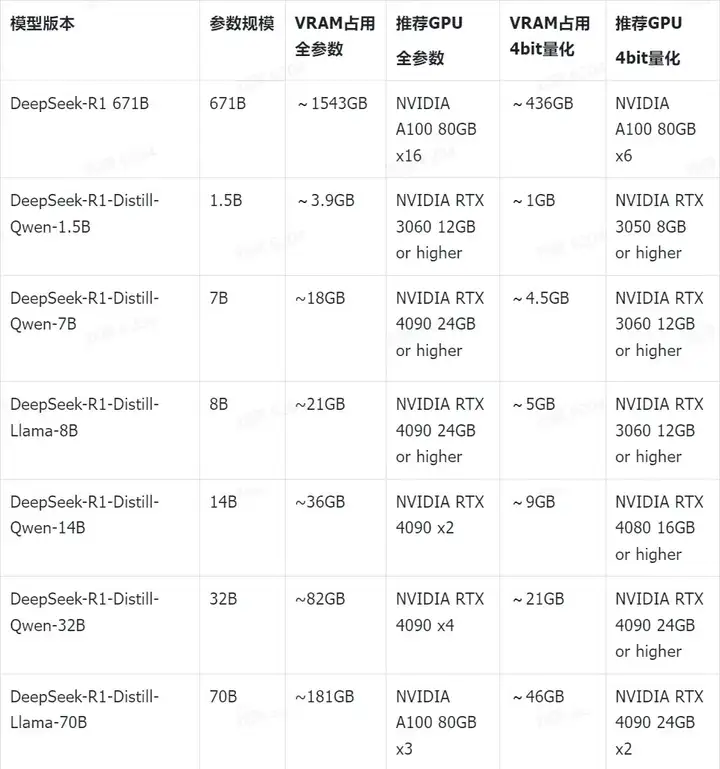
得益于量化技术(GPTQ、AWQ)、推理框架优化(vLLM、TensorRT),DeepSeek的显存需求相比其他大模型可降低约30~70%。因此相比Qwen和Llama等开源模型,DeepSeek对本地部署是更加友好的。
除了671B是基础大模型外,其余的1.5B、7B、8B、14B、32B、70B均是蒸馏后的小模型,根据资源的开销和性能的表现,也具有不同的使用场景。
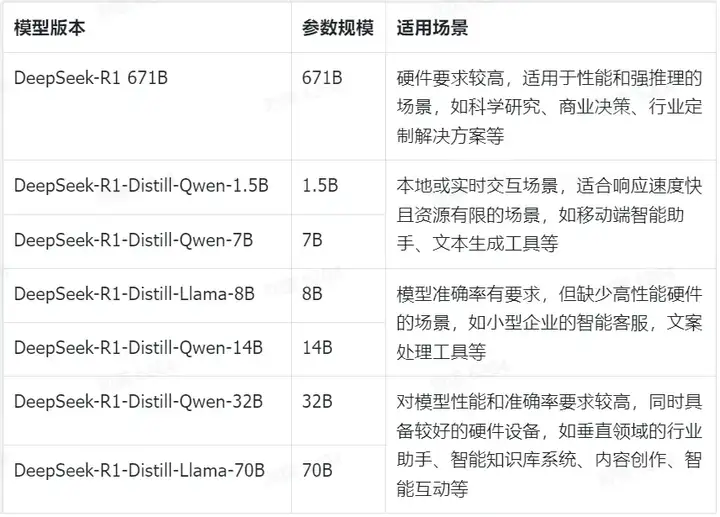
模型参数量越多,能存储和表示的知识内容越丰富,也会具有更强的逻辑推理能力和语义理解能力。
DeepSeek客观指标评估
DeepSeek R1与V3 是基于混合专家(MoE)架构的大型语言模型,拥有6710亿参数,但每次推理仅激活370亿参数。在数学、代码和自然语言推理任务中,R1的表现已与闭源模型OpenAI o1相当,部分基准已经超越OpenAI-o1-mini模型。
DeepSeek-R1模型评估
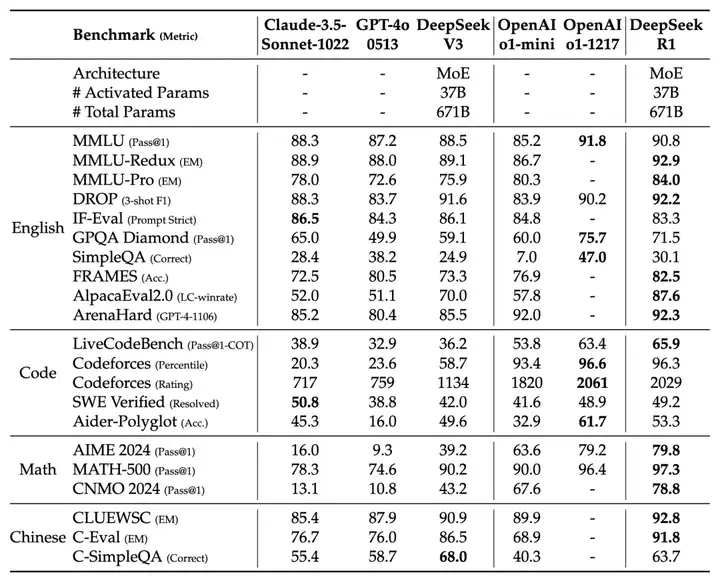
量化版本模型评估
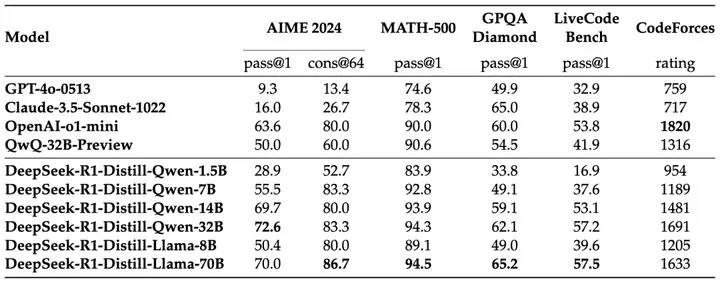
DeepSeek-R1是一个开源模型,和OpenAI o1一样具备反思推理,模型整体结构是以Transformer为主的MOE架构。R1模型并不是从头开始训练,而是以DeepSeek-V3作为基础模型,该模型使用14.8万亿高质量token训练,提供了非常强大的基础模型能力。R1的主要训练过程如下:
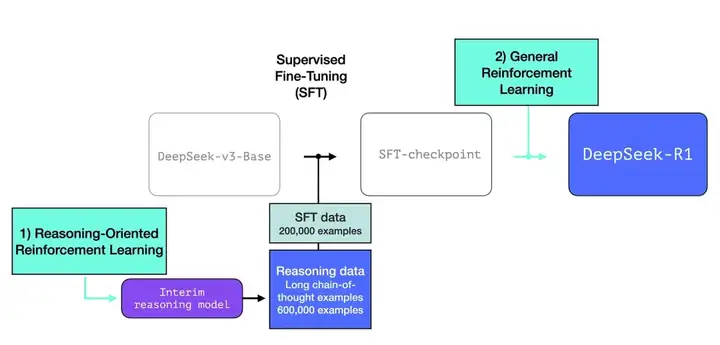
DeepSeek-R1的训练起点是Deepseek-v3-Base模型,作为基础模型训练,为后续的推理优化奠定基础。其核心组件和流程如下:
1、DeepSeek-R1-Zero(中间推理模型):无需SFT(Supervised Fine-Tuning,有监督微调),仅通过强化学习(Reinforcement Learning, RL)得到DeepSeek-R1-Zero,验证了仅需强化学习就能让模型具备自我验证、反思和生成长思维链(CoT)等推理行为。用于生成高质量数据,包括大量长链式思维(Chain-of-Thought, CoT)示例,为R1冷启动(cold start)提供数据源。
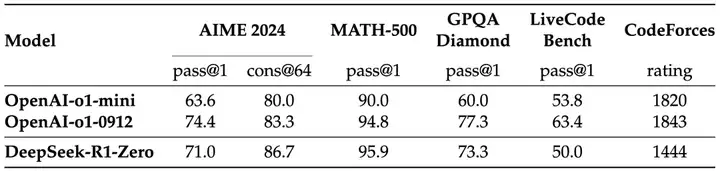

R1-Zero模型通过以规则驱动的(rule-based)大规模强化学习,通过准确率奖励和格式奖励的训练范式,得到一个纯粹通过强化学习来增强的强推理模型,论证了无需数据标注和监督微调阶段,也能提升模型的反思推理能力,且部分能力达到OpenAI-o1水平,但面临着诸如可读性差和语言混杂等挑战。比如模型生成出的格式不是完整的Markdown格式,或者会生成中英文混杂的思考。
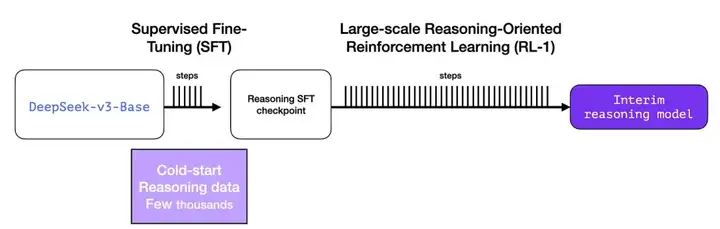
1)冷启动训练:以DeepSeek-v3-Base 为起点,使用少量高质量的CoT数据微调(数千个样本,其中一些是从R1-Zero中生成并过滤),用来防止训练的早期不稳定问题,让模型通过示例学习并开始模仿这种分步推理风格。通过冷启动SFT,得到中间态的推理模型,为后续的SFT提供数据
2)面向推理的强化学习RL-1:在冷启动模型基础上进行RL训练,重点提升模型在推理任务上的性能。借助R1-Zero 有时会对语言感到困惑的经验,引入语言一致性奖励:根据思维链中目标语言单词的比例计算,减少推理中语言混合的问题;最终将推理任务的准确性和语言一致性奖励相加,形成综合的奖励函数,对微调后的模型进行强化训练,增强模型能生成反思和验证步骤的详细答案。
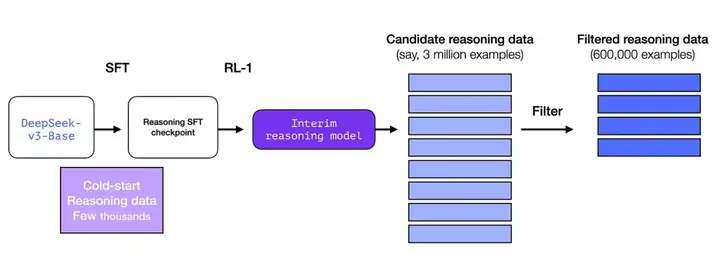
1)拒绝采样与监督微调:利用上一阶段 RL 1模型:(当RL训练接近收敛,使用中间的checkpoint来采样监督微调数据)进行拒绝采样,生成高质量的推理和非推理数据,并用这些数据对模型进行两轮微调。
•一轮为推理数据(约60w精炼数据):从上阶段RL模型进行拒绝采样,生成推理轨迹;增加其他数据来丰富数据集,其中部分数据采用生成奖励模型,评估生成的正确性和推理的可读性。同时,为提升数据质量,过滤混合语言、长段落和代码块的思维链,对于每个提示,采样多个响应,保留正确响应。
•另一轮为非推理数据(约20w训练样本):使用DeepSeek-V3 SFT数据集的一部分。对于简单的query,如“你好”,不使用思维链作为回答。经过筛选和整理,最终收集了大约20万个与推理无关的训练样本,用于一般技能,如写作、问答、翻译等。
在经过SFT的两阶段训练后,模型在推理准确率、可读性上得到提升,但为确保模型在全场景使用,还需进一步保证输出内容的有用性和无害性,对齐人类的偏好行为,因此还需强化学习来进一步确保R1的安全。
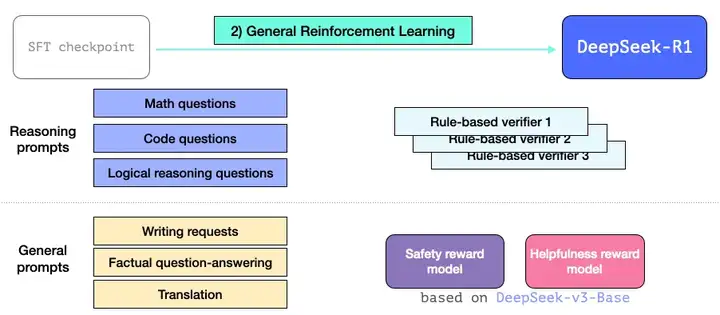
•训练:对于推理任务,采用基于规则的奖励来进行指导,进一步提升模型的思维能力;对于通用场景,采用有用和安全性奖励模型来对齐人类偏好;数据主要由通用QA提示、多样化的推理问题组成。
利用上述的SFT DeepSeek-R1的80万数据,对Qwen和Llama等开源模型进行了微调(只做了SFT,不包含RL)发现:
1)大模型在RL阶段会出现很多高阶推理模式,而小模型因为容量和表示能力有限,很难在无监督或纯RL情境下学到类似水平;
2)蒸馏能将大模型的推理轨迹,即思考方式转移到小模型,只需进行模仿也能远胜于自身独立强化学习的效果。
02 使用Ollama进行DeepSeek的本地部署
最近DeekSeek官方的服务器不是很稳定,总是出现“服务器繁忙,无法响应”的情况。但由于DeekSeek-R1是开源模型,其实我们都可以在本地部署该模型,从而可以不受限制地使用该模型。以下是使用Ollama + ChatBox进行本地部署的流程:
1、首先下载指定操作系统的Ollama安装包,并进行安装,然后根据当前电脑的运行显存或内存,选择合适的Ollama版本,复制Ollama的运行命令。(https://ollama.com/download)
2、Ollama运行(运行指定版本模型,会自动下载)
Plain Text# 运行指令ollama run deepseek-r1:7b
3、终端查看Ollama版本
Plain Text# ollama版本查看ollama -v# ollama当前模型列表ollama list# 模型文件下载并运行ollama run deepseek-r1:7b
4、执行Ollama run指令后,Ollama服务会自动下载模型,请确保网络正常;
正常运行后访问127.0.0.1:11434会出现如下界面。Ollama默认绑定端口为11434
Plain Text# 如何更改ollama的端口和IP地址(Linux),开启服务监听# Linuxexport OLLAMA_HOST=0.0.0.0:11434# Windows1、vim /etc/systemd/system/ollama.service2、增加如下内容[Service]Environment=“OLLAMA_HOST=0.0.0.0:11434”3、重启ollama服务sudo systemctl daemon-reloadsudo systemctl restart ollamasudo systemctl status ollama
5、正常运行后,打开网页如下:
6、命令行终端对话
当输入“你好呀”,并看到上图这样的提示后,证明Ollama服务就成功启动了,我们已经可以在本地使用DeepSeek-R1的7B模型。
03 Dify部署和与Ollama打通
Dify是一款开源的大语言模型应用开发平台。它融合了后端即服务(Backend as Service)和 LLOPs的理念,使开发者可以快速搭建生产级的生成式AI应用,支持自定义工作流服务。即使你是非技术人员,也能参与到AI应用的定义和数据运营过程中。Dify的安装过程如下:
1、Linux下安装Docker
Plain Text
1、卸载旧版本的Docker(如果已安装)
sudo apt-get remove docker docker-engine docker.io containerd runc
2、更新Ubuntu的软件包列表
sudo apt update
3、安装Docker所需的依赖包
sudo apt install apt-transport-https ca-certificates curl software-properties-common -y
4.1、添加Docker的官方GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4.2、添加Docker的APT存储库
echo 'deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable' | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
4.3、或者添加国内源(视情况而定),以腾讯云为例,参考如下
https://cloud.tencent.com/document/product/1207/45596
5、再次更新软件包列表,并安装Docker引擎
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io -y
6、启动Docker服务并设置为开机自启
sudo systemctl start docker
7、验证Docker安装是否成功
docker version
2、Linux下安装docker compose
注意:如安装存在网络问题,可直接github下载对应系统的二进制文件并运行。
Plain Text
1、下载Docker Compose的二进制文件到本地
sudo curl -L 'https://github.com/docker/compose/releases/download/v2.x.x/docker-compose-$(uname -s)-$(uname -m)' -o /usr/local/bin/docker-compose
2、给Docker Compose二进制文件添加执行权限
sudo chmod +x /usr/local/bin/docker-compose
3、验证Docker Compose是否安装成功
docker-compose --version
3、Dify安装与常用命令
Plain Text
1、github地址:https://github.com/langgenius/dify
2、安装命令(如遇到进度条不懂,请检查docker镜像配置是否正确)
cd dify
cd docker
cp .env.example .env
docker compose up -d
3、dify使用教程
https://docs.dify.ai/zh-hans/guides/application-orchestrate/creating-an-application
4、dify的重启运行(确保在docker文件下)
(停止)docker compose down
(运行)docker compose up -d
5、网页IP地址开启
http://IP地址/apps
在安装成功后,我们可以引入已经部署好的Ollama:
1、模型配置界面,引入Ollama地址(IP:11434)
2、编排工作流,选择部署的模型,配置内容后对话
04 Ollama部署ChatBox
Chatbox 是一款开源的跨平台 AI 桌面客户端应用,方便集成多种大语言模型,能帮助用户完成多种功能,例如翻译、办公、编程等,同时支持自定义Prompt、保存用户聊天记录。我们可以使用ChatBox来方便的与本地部署的DeepSeek模型进行对话,具体步骤为:
1、Chatbox下载(https://chatboxai.app/en)
根据操作系统,选择对应的Chatbox进行下载,并安装,安装后界面如下:
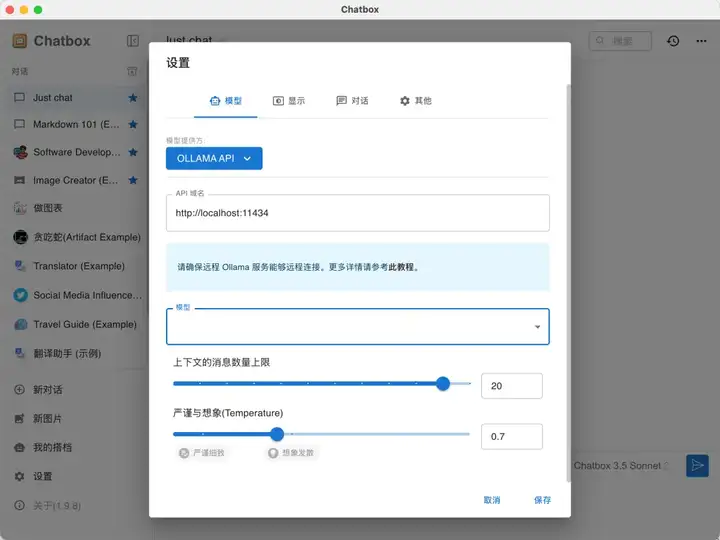
2、集成Ollama服务到Chatbox
3、自定义功能,如翻译、办公、编程,开启你的AI工具之旅
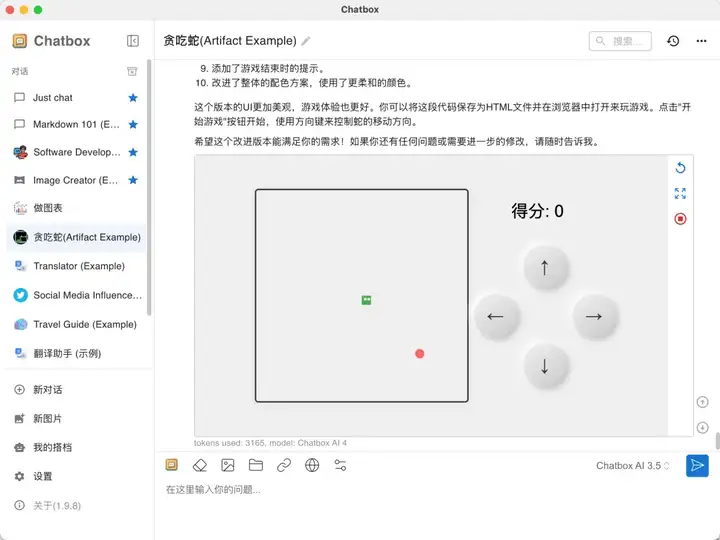
示例1:帮我写一个html的贪吃蛇应用
AI编写完后,即能在线预览,并能进行体验。
示例2:帮我写行业的产品文案
05 关于DeepSeek的感悟
近期,DeepSeek凭借'开源+新训练方法+低成本+高性能'的优势,在多项任务上已经比肩OpenAI-o1,其成本却仅为OpenAI的3%~5%。这家年轻化、扁平化、精简化的企业展现出惊人的效率和迭代速度,据传即使在春节期间也在持续进行模型迭代,摒弃了冗长的管理模式。
从技术发展来看,DeepSeek展现出强大的可持续性。从国内首个开源的DeepSeek MoE,到后续的V2、V3和R1版本,每次迭代都是对原有模型的延展和技术的快速验证。面对有关护城河构建的质疑,梁文锋给出了明确答复:“我们真正的护城河在于团队的成长——积累技术Know-how,培养创新文化。”
在核心竞争力方面,虽然业内传闻DeepSeek和其他国内公司一样使用了部分OpenAI的数据进行模型训练,但DeepSeek独辟蹊径,通过善用强化学习突破了蒸馏范式的限制。这种技术创新不仅提升了核心竞争力,还实现了成本节省和更好的用户体验。
在实际应用方面,DeepSeek始终强调数据的重要性,注重数据的梳理、归档和统一知识库的建设。他们秉持着技术产品应该走向全民化的理念,追求低成本和创新体验。凭借强大的推理能力,DeepSeek在智能办公客服(包括HR助手、财务报销、综合管理、日常文案等)、智能角色交互(社交、游戏等)以及开发编程效能提升等领域都有着广阔的应用前景。
作者:Hang Zhang
个人主页:https://scholar.google.com/citations?user=dISPYjYAAAAJ&hl=enRef.
https://apxml.com/posts/gpu-requirements-deepseek-r1
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://newsletter.languagemodels.co/p/the-illustrated-deepseek-r1
https://chatboxai.app/en
https://ollama.com/download
文章来自微信公众号 “ Z Potentials “



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
