程序员面试背了十年的八股文,被DeepSeek废了
程序员面试背了十年的八股文,被DeepSeek废了过去十几年,程序员面试早就形成了一套成熟的应试套路。背题、刷题、共享面经,一条龙服务,从几块钱的 PDF 到十几万的“包过内推”,每一个价位都有对应的产品。只要你花够时间准备,进大厂的概率不低。
来自主题: AI资讯
8565 点击 2026-07-14 09:30
 搜索
搜索
过去十几年,程序员面试早就形成了一套成熟的应试套路。背题、刷题、共享面经,一条龙服务,从几块钱的 PDF 到十几万的“包过内推”,每一个价位都有对应的产品。只要你花够时间准备,进大厂的概率不低。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
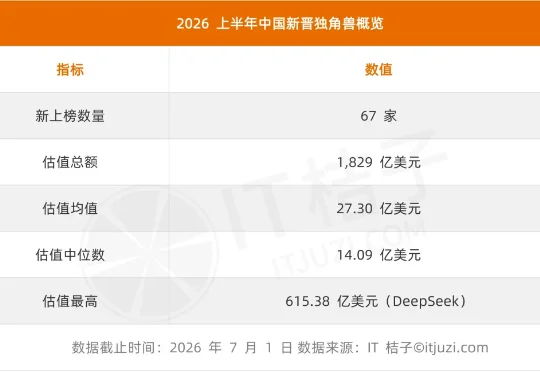
截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家:
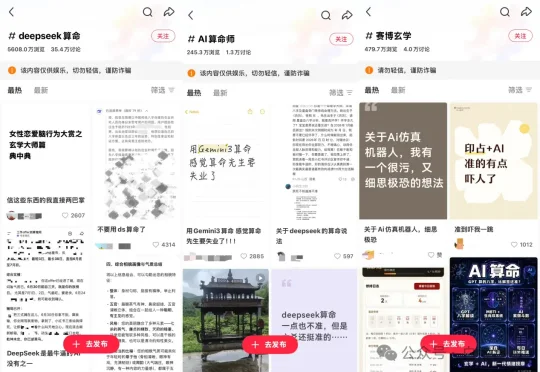
小红书上,#deepseek 算命、#赛博玄学等话题下,大量玄学爱好者聚集,分享不同占卜体系的prompt、交流 AI 算命心得,仅 #deepseek 算命一个话题,浏览量就达到 5608 万、讨论量 35.4 万;与此同时,更深度的 AI 用户开始在 GitHub 上自行开发占卜 Skills,搜索“astrology”“bazi”等关键词,可以看到相关项目最高 Star 数已达 3.9k。
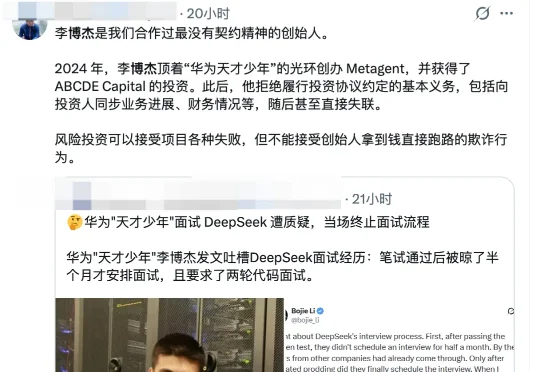
前“华为天才”李博杰的一条吐槽小作文,喜提热搜。相信大家都看了,我就不在这里写了。这个事儿上热搜能理解的,一个是前“华为天才”的标签(虽然也有人说华为天才也不少),一个是当红国产模型炸子鸡deepseek
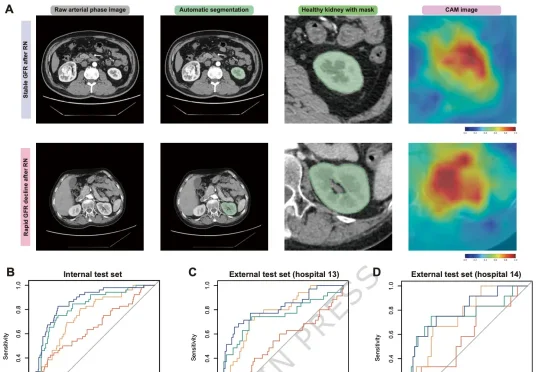
2026年5月28日,Nature通讯发表了题为 《Multimodal deep learning model for AI-based functional prognostic risk stratification in patients undergoing radical nephrectomy》 的论文。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。

今天,据路透社报道,三位知情人士透露,DeepSeek正在自研AI推理芯片,以减少对英伟达以及华为芯片的依赖。知情人士称,DeepSeek自研芯片的工作大约在一年前启动,其研发仍处于早期阶段。目前,DeepSeek正在接触外部合作伙伴,并与芯片设计企业、晶圆代工厂以及存储企业展开讨论。

刚刚,DeepSeek 在官方 API 文档里给出了一个 thinking mode 和 tool call 结合使用的样例。表面上看,这只是一个常规的工具调用演示:用户提出问题,模型判断需要调用工具,工具返回结果后,模型再继续生成答案。

7月6日晚,一则帖子引爆了AI行业。 一个中科大少年班出身、华为第一批天才少年、AI创业公司首席科学家,在DeepSeek的面试现场,被面试官当面说:停止抄袭。 他叫李博杰。