# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调
(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。但使用 LoRA 适配器的微调方法需要明确的意图选择,因此在搭载多个 LoRA 适配器的单
一大语言模型上,自主任务感知和切换方面一直存在挑战。
为此,团队提出了一个可扩展、高效的多任务嵌入架构 MeteoRA。该框架通过全模式混合专家模型(MoE)将多个特定任务的 LoRA 适配器重用到了基础模型上。
该框架还包括了一个新颖的混合专家模型前向加速策略,以改善传统实现的效率瓶颈。配备了 MeteoRA 框架的大语言模型在处理复合问题时取得了卓越的性能,可
以在一次推理中高效地解决十个按次序输入的不同问题,证明了该模型具备适配器及时切换的强化能力。

该工作的创新点主要有以下部分:
约 4 倍的加速。
相关工作
低秩适应 (LoRA):低秩适应 [1] 提供了一种策略来减少下游任务微调所需要的可训练参数规模。对于一个基于 Transformer 的大语言模型,LoRA 会向每一个基本线
性层的权重矩阵注入两个可训练的低秩矩阵,并用两个低秩矩阵的相乘来代表模型在原来权重矩阵上的微调。LoRA 可以用于 Transformer 中自注意力模块和多层感
知机模块的 7 种权重矩阵,有效缩减了微调权重的规模。应用低秩适应技术可以在不改变预训练模型参数的前提下,使用自回归语言模型的优化目标来训练 LoRA 适
配器的参数。
多任务 LoRA 融合:LoRA 适配器通常被微调来完成特定的下游任务。为了增强大语言模型处理多种任务的能力,主流的做法有两种。一种方法是从多种任务中合并
数据集,在此基础上训练单一的 LoRA 适配器,但相关研究已经证明同时学习不同领域的知识很困难。[2] 另一种方法是直接将多种 LoRA 适配器整合到一个模型
中,如 PEFT [3]、S-LoRA [4]。但是流行的框架必须要明确指定注入的 LoRA 适配器,因此模型缺乏自主选择和及时切换 LoRA 的能力。现有的工作如 LoRAHub [5]
可以在不人为指定的情况下完成 LoRA 适配器的选择,但仍旧需要针对每一个下游任务进行少量的学习。
混合专家模型(MoE):混合专家模型是一种通过组合多个模型的预测结果来提高效率和性能的机器学习范式,该范式通过门控网络将输入动态分配给最相关的 “专
家” 来获得预测结果。[6] 该模型利用来自不同专家的特定知识来改善在多样、复杂的问题上的总体表现,已有研究证明 MoE 在大规模神经网络上的有效性 [7]。对于
每个输入,MoE 只会激活一部分专家,从而在不损害模型规模的基础上显著提高计算效率。该方法已被证实在扩展基于 Transformer 的应用架构上十分有效,如
Mixtral [8]。
方法描述
该工作提出了一个可扩展、高效的多任务嵌入架构 MeteoRA,它能够直接使用开源社区中或面向特定下游任务微调好的 LoRA 适配器,并依据输入自主选择、及时
切换合适的 LoRA 适配器。如图 1 所示,MeteoRA 模块可以被集成到注意力模块和多层感知机模块的所有基本线性层中,每一个模块都包括了一系列低秩矩阵。通
过 MoE 前向加速策略,大语言模型能够高效解决广泛的问题。
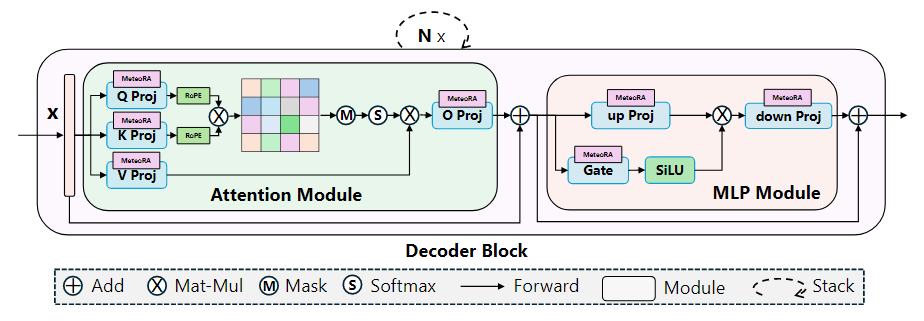
图 1:集成了 MeteoRA 模块实现 MoE 架构的大语言模型框架
图 2 展示了 MeteoRA 模块的内部结构。MeteoRA 模块中嵌入了多个 LoRA 适配器,并通过一个门控网络来实现 MoE 架构。该门控网络会依据输入选择 top-k 个
LoRA 适配器,并将它们组合作为微调权重进行前向传播。通过这种架构,门控网络会执行路由策略,从而根据输入选取合适的 LoRA 适配器。每一个 MeteoRA 模
块都包含一个独立的门控网络,不同门控网络依据它们的输入独立决策,并在全部解码器模块的前向传播过程中动态选取不同 LoRA 适配器。
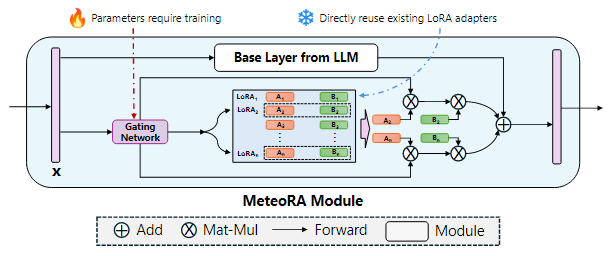
图 2:应用 MoE 模型集成 LoRA 嵌入的 MeteoRA 模块的架构
MeteoRA 模块的训练遵循自回归语言建模任务下的模型微调准则,训练中需要保持基本的大语言模型权重和预训练的 LoRA 适配器参数不变。由于 MeteoRA 模块支
持选择权重最高的若干个 LoRA 适配器,团队引入了一种将自回归语言建模损失和所有门控网络损失组合起来的联合优化方案。该优化函数综合了自回归模型中的预
测损失和 MeteoRA 模块中 LoRA 分类的交叉熵损失,实现门控网络的训练。
MeteoRA 模块的核心组件是整合了多个 LoRA 适配器的 MoE 架构。首先,团队将 LoRA 整合成在 HBM 上连续分配的张量。对于每个批次的输入序列中的每个标
记,由于该模块需要利用门控网络找到 LoRA 适配器的编号索引集合,MeteoRA 模块几乎不可能与单独的 LoRA 模块保持相同的效率。基于原始循环(loop-
original)的简单实现 [8] 采用 for-loop 遍历 LoRA 适配器,在每次遍历中对该适配器的候选集合应用 LoRA 前向传递。该方法简单地将所有批次的所有标记拆成
LoRA 数量个集合,并且使得每个集合按顺序传递。然而,考虑到输入标记相互独立的性质,这种方法无法充分利用并行化 GEMM 算子 [9] 加速,尤其是当某些
LoRA 适配器仅被少数标记选择,或是待推理标记小于 LoRA 数量时,实验中可能花费最多 10 倍的运行时间。
该工作采用了前向传播加速策略 bmm-torch,直接索引全部批次标记的 top-k 适配器,这会利用到两次 bmm 计算。相比于原始的循环方法,bmm-torch 基于
PyTorch 提供的 bmm 操作符 [10] 并行化所有批次标记的 top-k 个适配器,实现了约 4 倍的加速。在实验中该策略仅比它的上限单 LoRA 模块慢 2.5 倍。由于
PyTorch 的索引约束(indexing constraints)[11],bmm-torch 需要分配更大的内存执行批处理,当批次或者输入长度过大时 bmm-torch 的大内存开销可能成为瓶
颈。为此,该工作使用了 Triton [12] 开发了自定义 GPU 内核算子,不仅保持了 bmm-torch 约 80% 的运算效率,而且还保持了原始循环级别的低内存开销。
实验结果
该工作在独立任务和复合任务上,对所提出的架构和设计进行了广泛的实验验证。实验使用了两种知名的大语言模型 LlaMA2-13B 和 LlaMA3-8B,图 3 显示了集成
28 项任务的 MeteoRA 模块与单 LoRA、参考模型 PEFT 在各项独立任务上的预测表现雷达图。评估结果表明,无论使用哪种大语言模型,MeteoRA 模型都具备与
PEFT 相近的性能,而 MeteoRA 不需要显式地激活特定的 LoRA。表 1 展示了所有方法在各项任务上的平均分数。
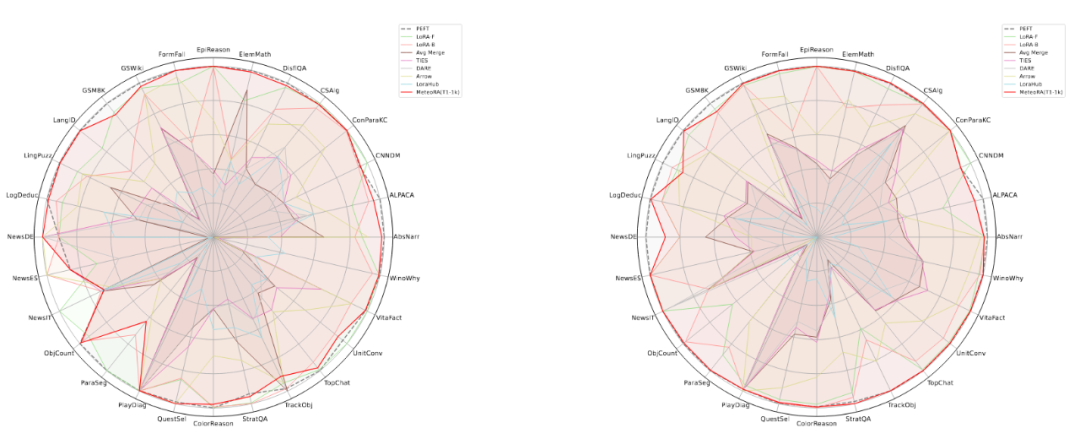
图 3:MeteoRA 模型在 28 项选定任务上的评估表现
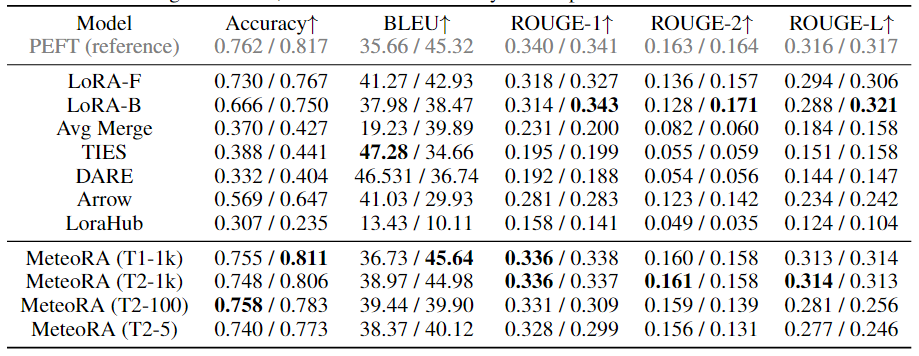
表 1:各模型在 28 项选定任务上的平均表现
为了验证该模型按顺序解决复合问题的能力,该工作通过串行连接独立的任务来构建 3 个数据集,分别整合了 3、5、10 项任务,期望模型能够按次序解决同一序列
中输入的不同类别问题。实验结果如表 2 所示,可见随着复合任务数的提升,MeteoRA 模块几乎全面优于参考 LoRA-B 模型。
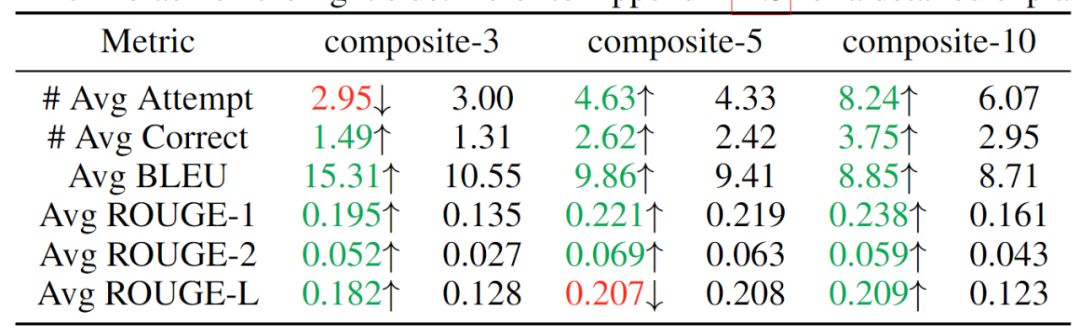
表 2:复合任务的评估结果,左侧为 MeteoRA 模块,右侧为 LoRA-B
为了更进一步验证门控网络在 MeteoRA 模块中的功能,该工作展示了在复合任务推理过程中采用 top-2 策略的 LoRA 选择模式。在两个相邻任务的连接处,门控网
络正确执行了 LoRA 的切换操作。

图 4:在 3 项任务复合中 LoRA 选取情况的例子
为了验证采用自定义 GPU 算子的前向传播设计的运算效率,该工作在 28 项任务上截取了部分样本,将新的前向传播策略与其上限和原始实现对比。评估结果如图
5 所示,展现了新的加速策略卓越的性能。
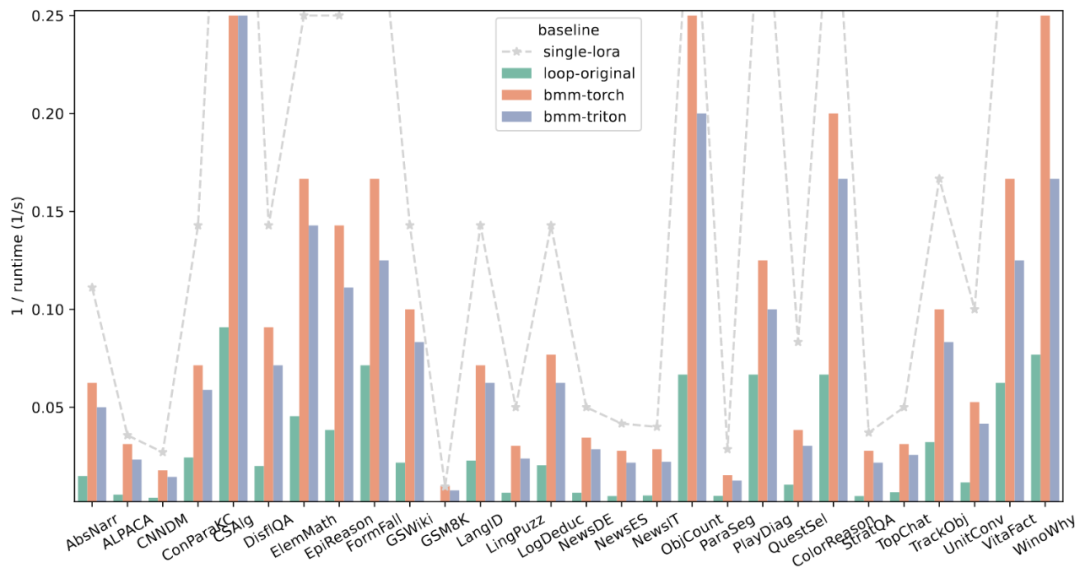
图 5:四种不同的前向传播策略在 28 项任务上的整体运行时间
参考文献:
[1] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large
language models. arXiv preprint arXiv:2106.09685, 2021.
[2] Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, Tianjiao Zhao,
Amit Panalkar, Dhagash Mehta, Stefano Pasquali, Wei Cheng, Haoyu Wang, Yanchi Liu, Zhengzhang Chen, Haifeng Chen, Chris White, Quanquan Gu, Jian Pei,
Carl Yang, and Liang Zhao. Domain specialization as the key to make large language models disruptive: A comprehensive survey, 2024.
[3] Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning
methods. https://github.com/huggingface/peft, 2022.
[4] Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, et al. S-lora:
Serving thousands of concurrent lora adapters. arXiv preprint arXiv:2311.03285, 2023.
[5] Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. Lorahub: Efficient cross-task generalization via dynamic lora composition.
arXiv preprint arXiv:2307.13269, 2023.
[6] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3 (1):79–87, 1991.
[7] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-
gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
[8] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma
Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, MarieAnne Lachaux, Pierre Stock,
Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El
Sayed. Mixtral of experts, 2024.
[9] Shixun Wu, Yujia Zhai, Jinyang Liu, Jiajun Huang, Zizhe Jian, Bryan Wong, and Zizhong Chen. Anatomy of high-performance gemm with online fault tolerance
on gpus. In Proceedings of the 37th International Conference on Supercomputing, pages 360–372, 2023b.
[10] PyTorch. torch.bmm — pytorch 2.3 documentation. https://pytorch.org/docs/stable/generated/torch.bmm.html, 2024a. Accessed: 2024-05-23.
[11] PyTorch. Tensor indexing api — pytorch documentation. https://pytorch.org/cppdocs/notes/tensor_indexing.html, 2024b. Accessed: 2024-05-23.
[12] Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the
3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
文章来自于 微信公众号“机器之心”,作者 :赖俊宇和黄云鹏




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
