# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?
为此,来自港中文MMLab的研究者们提出了MME-CoT。

这是一个全面且专门用于评估LMMs中视觉推理能力的Benchmark,包括了数学、科学、OCR、逻辑、时空和通用场景。
MME-CoT与之前的LMM的Benchmark最大的区别在于,提出了一个严格且多方面的评估框架,细粒度地研究视觉CoT的不同方面,评估其推理的质量、鲁棒性和效率。
各种最新推出的LMM,包括Kimi k1.5, GPT-4o, QVQ等等都在MME-CoT上进行了测试。同时,研究者们还把图片转成caption之后测试了最近爆火的DeepSeek-R1以及o3-mini。
基于实验结果,文章中得到了很有价值的结论:
值得一提的是,DeepSeek-R1的文本推理能力非常出众。仅仅使用图片的caption就可以在precision上超过真实看到图片的GPT-4o。最后的CoT质量也与GPT-4o仅有1.9%之差。
其次,反思能力的引入显著提升了CoT质量,所有具备反思能力的LMM都实现了较高的CoT质量表现。例如QVQ达到了62.0%的F1分数,大幅超过Qwen2-VL-72B 6.8%。而Kimi k1.5更是超越GPT-4o达到最佳质量。
在鲁棒性方面,团队发现大多数早期模型在感知任务中都受到CoT的负面影响,表现出有害的过度思考行为,其中最显著的案例是InternVL2.5-8B,在感知任务中应用CoT后性能下降了6.8%,这严重制约了将CoT推理作为默认操作的可行性。
最后,关于CoT效率,团队观察到输出长CoT的模型普遍存在步骤的相关性不足的问题。模型容易被图像内容分散注意力,过度关注图像而忽视了对题目的解答,尤其是在处理通用场景、时空和OCR任务时。实验结果显示,约30%到40%的反思步骤未能有效协助问题解答,这暴露出当前模型反思能力的重要缺陷。
目前绝大多数的LMM的Benchmark都只评估最终答案的正确性,忽视了LMM整个的CoT的推理过程。为了能全面地了解视觉CoT的各个属性,研究者们提出了三个不同的评估方向,每个方向致力于回答一个关键的问题:
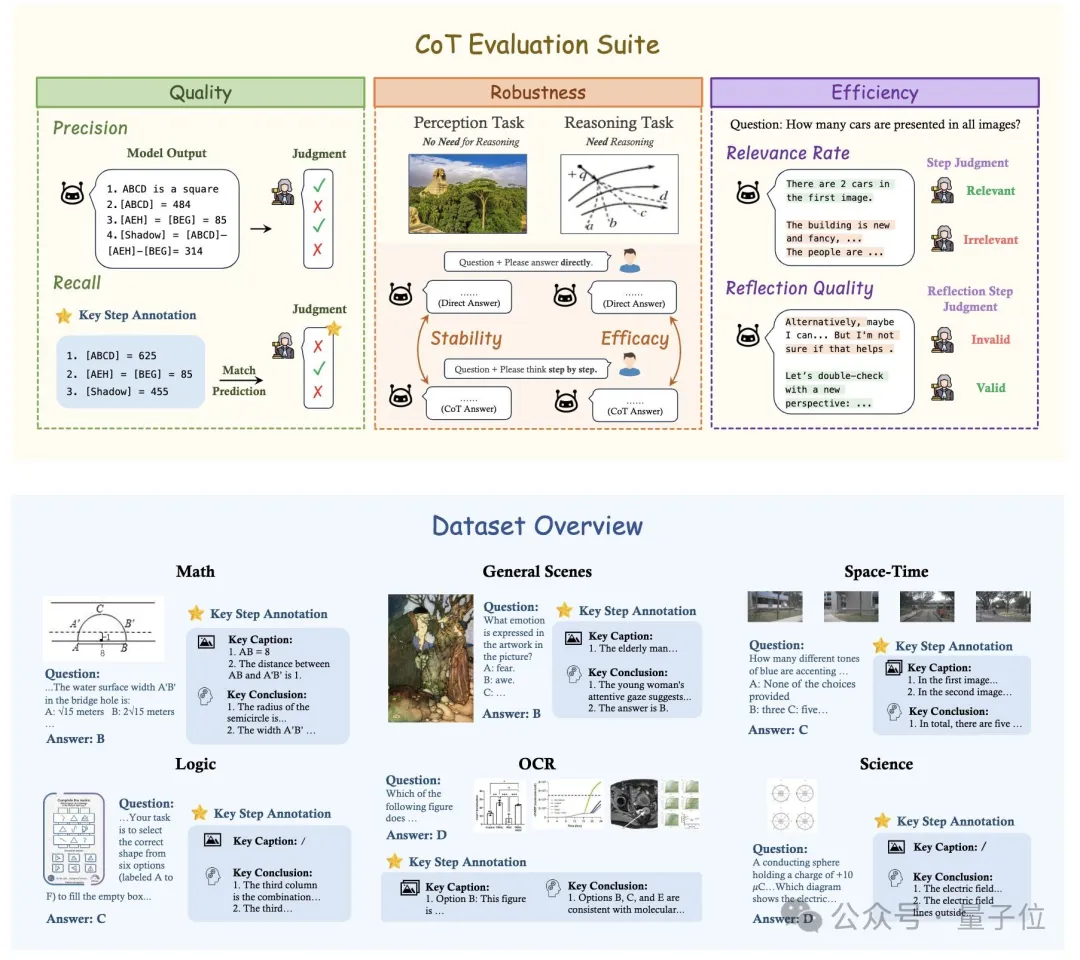
1、CoT的质量:每个CoT步骤是否有用且准确,不存在幻觉?
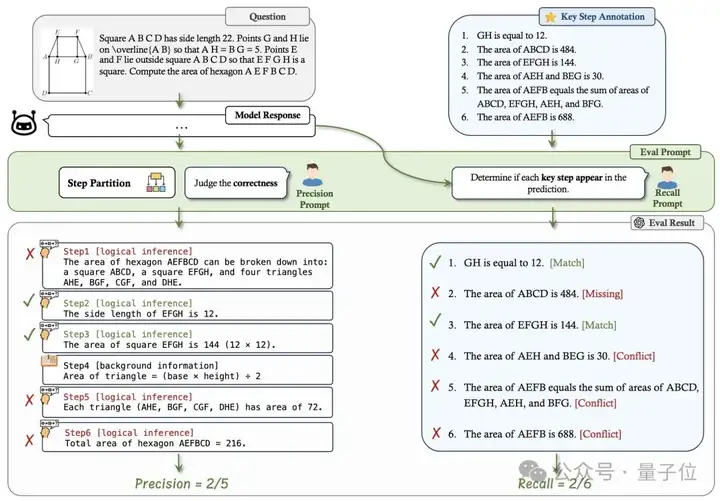
只评估回答的结果忽略了模型通过错误的逻辑或随机猜测得出正确答案的情况。这往往造成了模型推理能力被夸大的假象。为了深入研究推理过程,研究者们引入了两个可解释的指标来评估CoT的质量
:
2、CoT的鲁棒性:CoT是否干扰感知任务,它在多大程度上增强了推理任务?
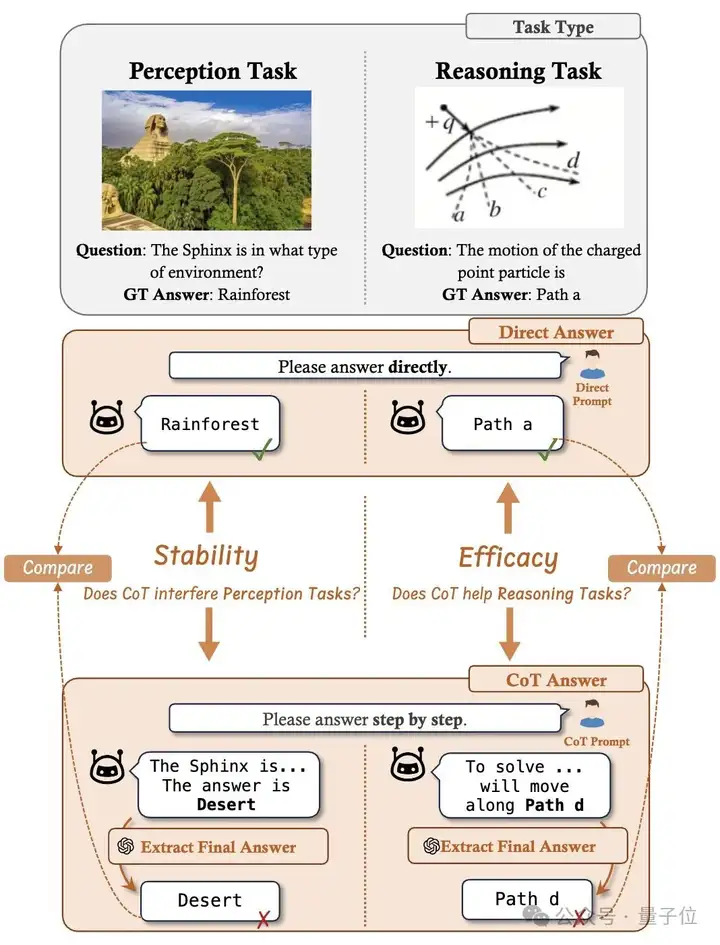
现有研究主要关注CoT对推理任务带来的性能改进,却往往忽视了CoT是否会无意中破坏模型对于仅需要感知的任务的能力。随着o1以及R1的爆火,CoT逐渐已成为模型的默认的推理策略。然而,模型无法提前预知用户提出的问题类型,也不确定使用CoT来回答是否比直接给出答案会有更高的准确率。因此,在目前的时间点上,CoT在不同类型任务下的鲁棒性变得格外重要。为了衡量鲁棒性,MME-CoT包括了两个任务类别:感知任务和推理任务,以及两种不同的Prompt形式:要求模型直接回答(answer directly)以及CoT回答(think step by step)。
3、CoT的效率:使用CoT的推理效率是怎么样的?
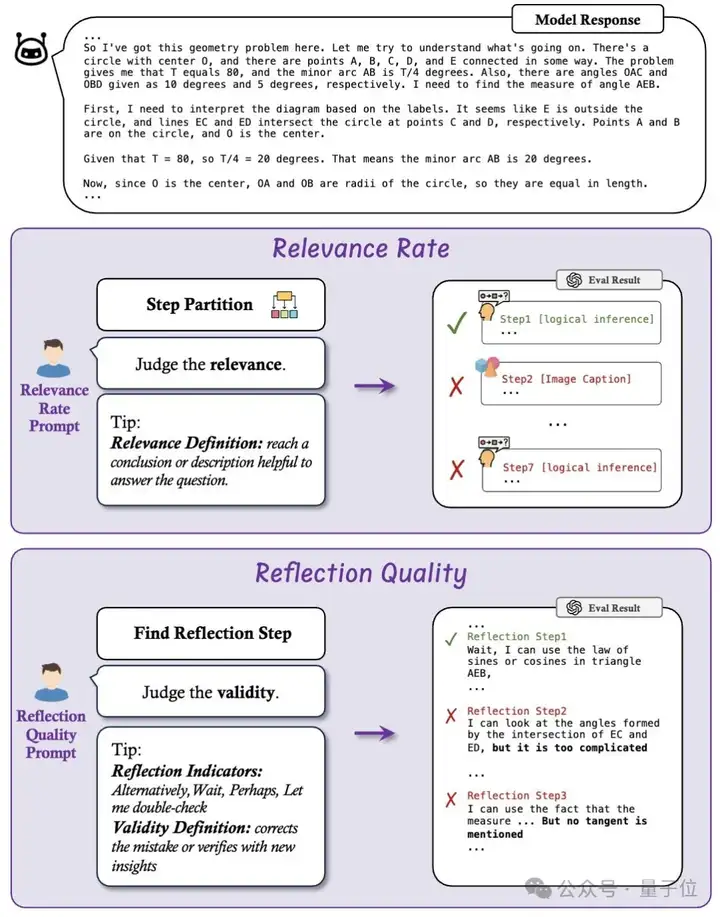
最近的o1类模型通过采用超长的CoT和反思步骤而取得了非常好的效果。这提出了一个关键的权衡问题:这种方法是否在准确性和计算成本之间取得了最佳平衡?为了研究这一点,研究者们首次对LMMs中CoT的效率进行研究,使用了两个关键指标评估效率:
4、MME-CoT测试集
与纯文本推理问题不同,额外的视觉输入显著丰富了视觉推理问题的范围。有了图像输入,模型需要根据当前的推理进度频繁查看图像以获取相关信息。描述感兴趣的图像区域成为了思维链(CoT)过程中的关键部分。因此,除了需要严格逻辑的复杂问题外,通用场景中的许多问题也构成了具有挑战性的推理问题。
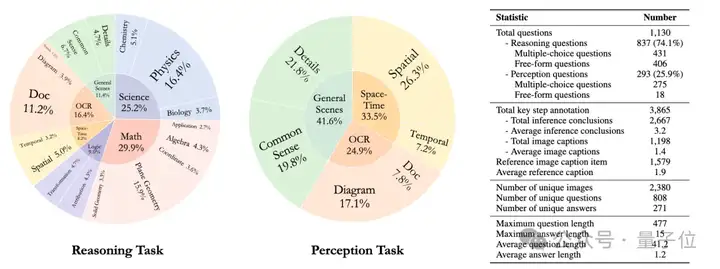
考虑到这一点,MME-CoT测试集构建起了一个覆盖专业领域与常识场景的全景视觉推理评估体系,共包括6大领域以及17个子类。为了保持对推理过程的关注,研究者们排除了需要复杂领域特定定理或专业知识的问题。
MME-CoT中分为感知任务以及推理任务,现有的Benchmark往往混淆这两类任务,使得这两类经常出现在相同类别中。为了解决这个问题,研究者们首先使用GPT-4o以及Qwen2-VL来进行预判,通过对比直接作答与CoT作答的表现差异,初步划分这两种不同类型的任务。接着,专业的标注团队逐题审核,确保分类的准确性。
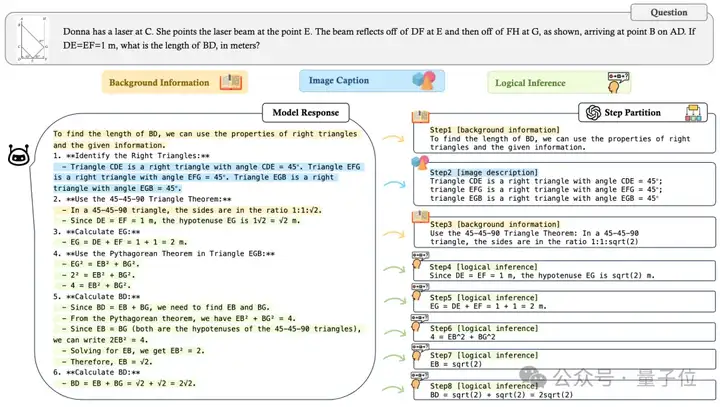
为了便于CoT的评估,标注团队为所有推理问题都给出了必要的推理步骤的Ground Truth标注。对于多解的问题,标注者被要求给出了每种可能的解法。最后,MME-CoT得到了1130道精选的问题以及3865个关键步骤标注。
研究者们在MME-CoT Benchmark上测评了13个现有的LMM以及2个最先进的具有超强推理能力的LLM:DeepSeek-R1以及o3-mini。对于LLM,研究者们将图片转化为详细的caption之后再输入到模型。
实验结果如下:
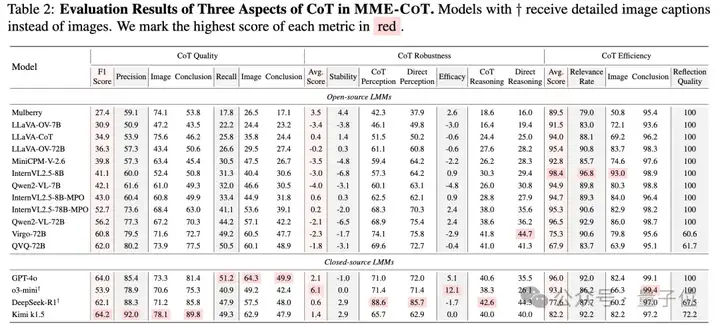
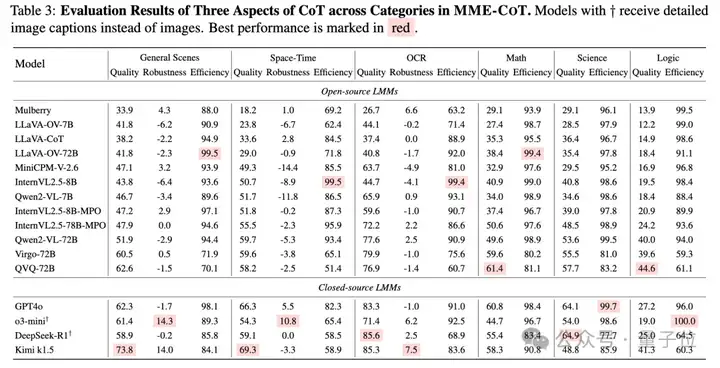
基于测评,还得到了如下的发现与结论:
1. 长CoT不一定涵盖关键步骤
尽管长思维链模型具有更高的精确率,但每个步骤的信息量并不能得到保证。团队观察到GPT-4o、QVQ和Virgo之间的召回率的趋势和它们最终能否正确解答推理任务的表现(即在使用CoT的prompt时,模型在推理任务的最终答案准确率,对应表格中的CoT Reasoning列)不一致。具体来说,虽然Virgo和QVQ在仅评估最终答案的正确性上都优于GPT-4o,但它们在召回率上落后。这表明长CoT模型有时会在跳过中间步骤的情况下得出正确答案,这与CoT本身奉行的Think step by step的原则相矛盾,值得进一步研究。
2. 更多参数使模型更好地掌握推理能力
团队发现参数量更大的模型往往获得更高的有效性(Efficacy)分数。这种模式在LLaVA-OV、InternVL2.5-MPO和Qwen2-VL中都很明显。例如,虽然Qwen2-VL-7B在将CoT应用于推理任务时显示出4.8%的性能下降,但其更大的对应模型Qwen2-VL-72B展示出2.4%的改进。这种差异表明,在相同的训练范式下,具有更多参数的模型能够更好地掌握推理能力。这一发现也某种程度上验证了R1论文中的关键发现:同等训练setting下,更大参数量的模型往往能更好地学习到推理的能力。
3. 模型的反思的错误涵盖多种类型

四种主要错误类型是:
理解和消除反思中的这些错误对于提高LMM的推理效率以及可靠性是至关重要的。
展望未来,MME-CoT不仅为评估LMM的推理能力提供了系统化的基准,更为该领域的研究指明了关键发展方向。通过揭示现有模型在推理质量、鲁棒性和计算效率等方面的不足,这项工作为后续研究奠定了重要基础。这些发现将推动LMM实现更强大以及可靠的视觉推理能力。
论文:https://arxiv.org/pdf/2502.09621
主页:https://mmecot.github.io
代码:https://github.com/CaraJ7/MME-CoT
数据集:https://huggingface.co/datasets/CaraJ/MME-CoT
文章来自微信公众号 “ 量子位 ”,作者 姜东志



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
