AI真能学会心算?隐式思维链首次得到理论证明,Stuart Russell参与
AI真能学会心算?隐式思维链首次得到理论证明,Stuart Russell参与过去一年,AI 推理模型的使用成本让不少开发者叫苦。
来自主题: AI技术研报
7213 点击 2026-06-08 09:49
 搜索
搜索
过去一年,AI 推理模型的使用成本让不少开发者叫苦。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
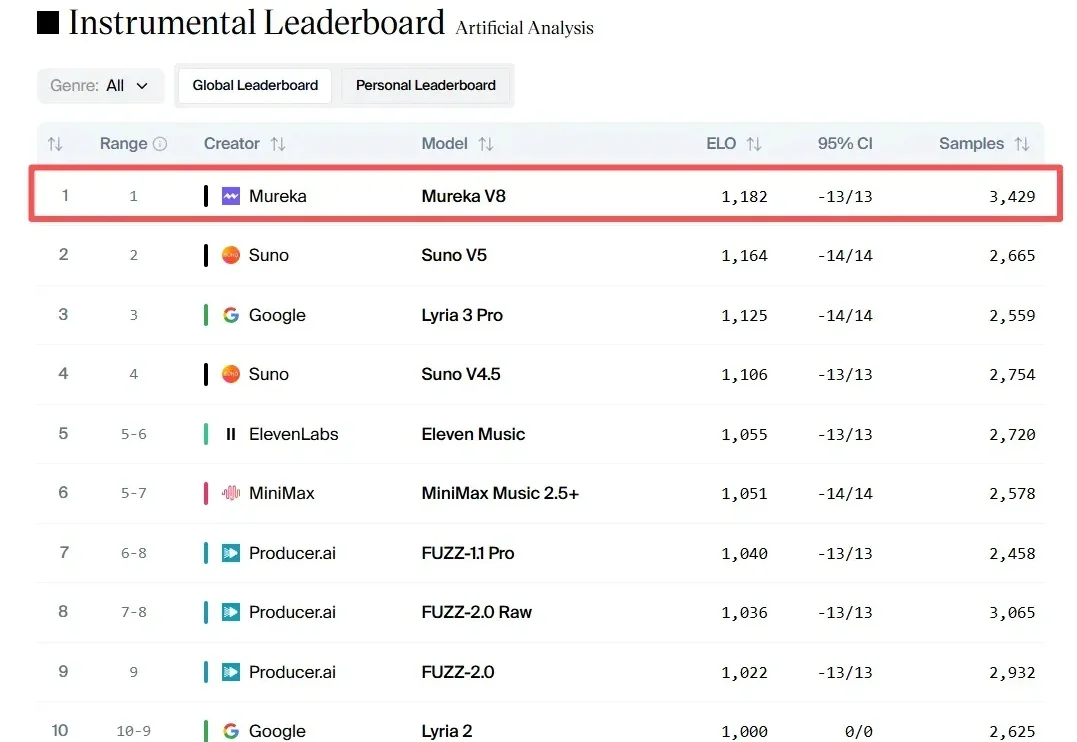
在 AI 音乐行业,有一个正在悄悄发生的迁移。
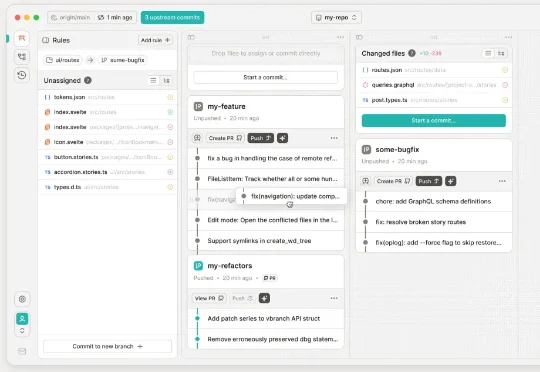
GitButler最近发布的CLI工具引起了我很大的兴趣。这不是一个简单的Git包装器,而是从根本上重新思考了命令行工具应该如何设计。Scott提到了一个有趣的观察:大约80%的开发者仍然使用命令行工具来操作Git,即使有各种GUI工具存在。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。

近日,开源项目 matplotlib 的维护者 Scott Shambaugh 最近披露了一件前所未有的事情——一个 AI 代理向他的开源项目提交了代码改进,被拒绝后,这个代理竟然自主写了一篇文章来攻击他。

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
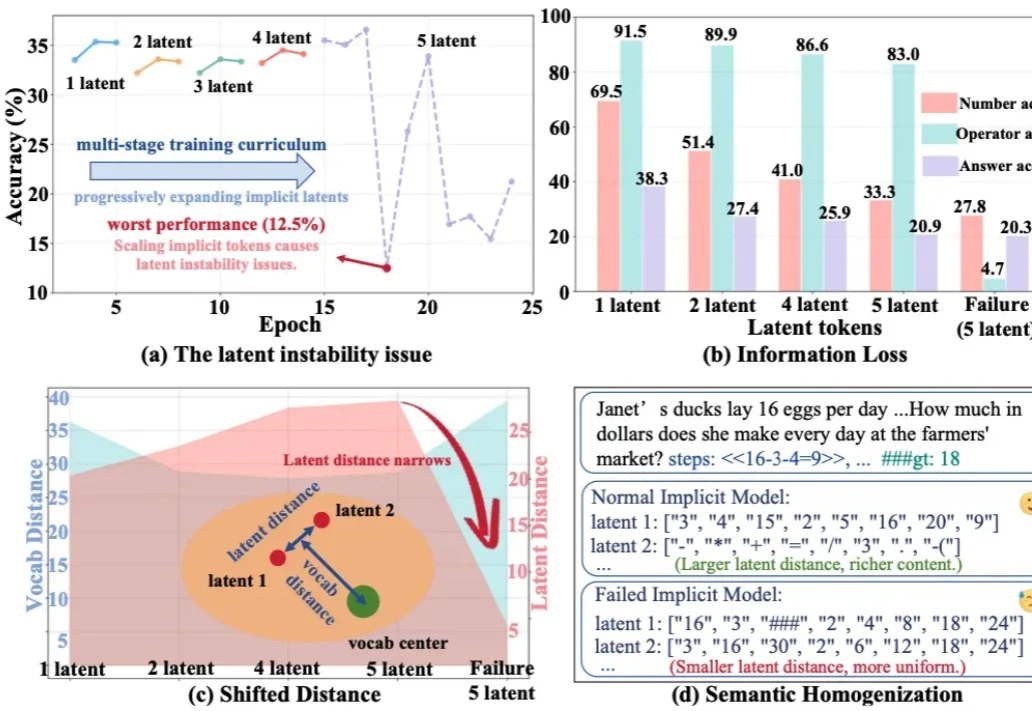
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。
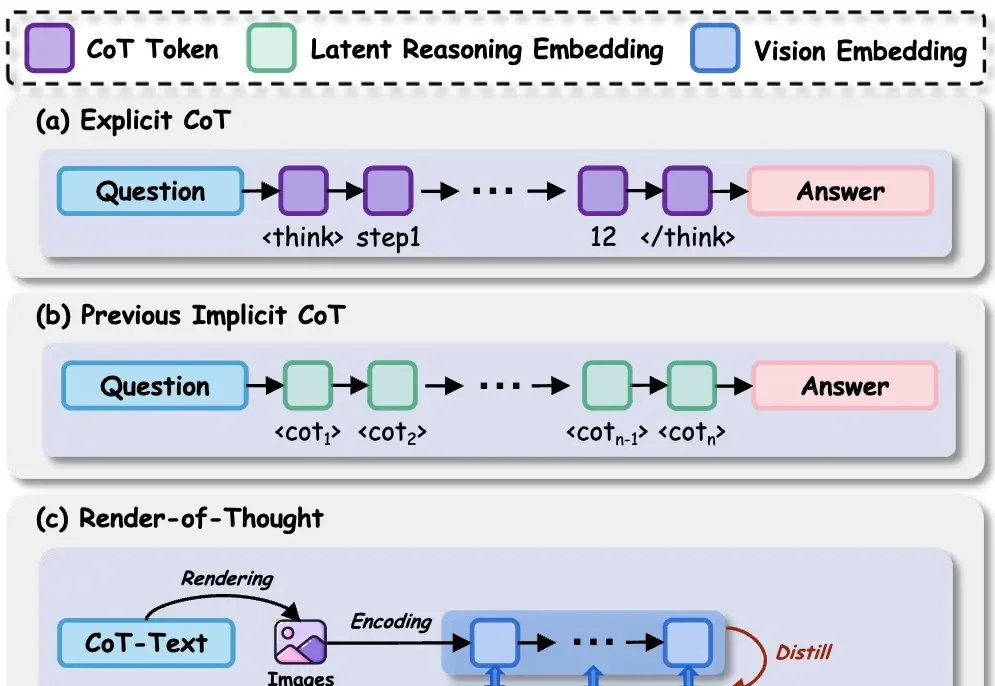
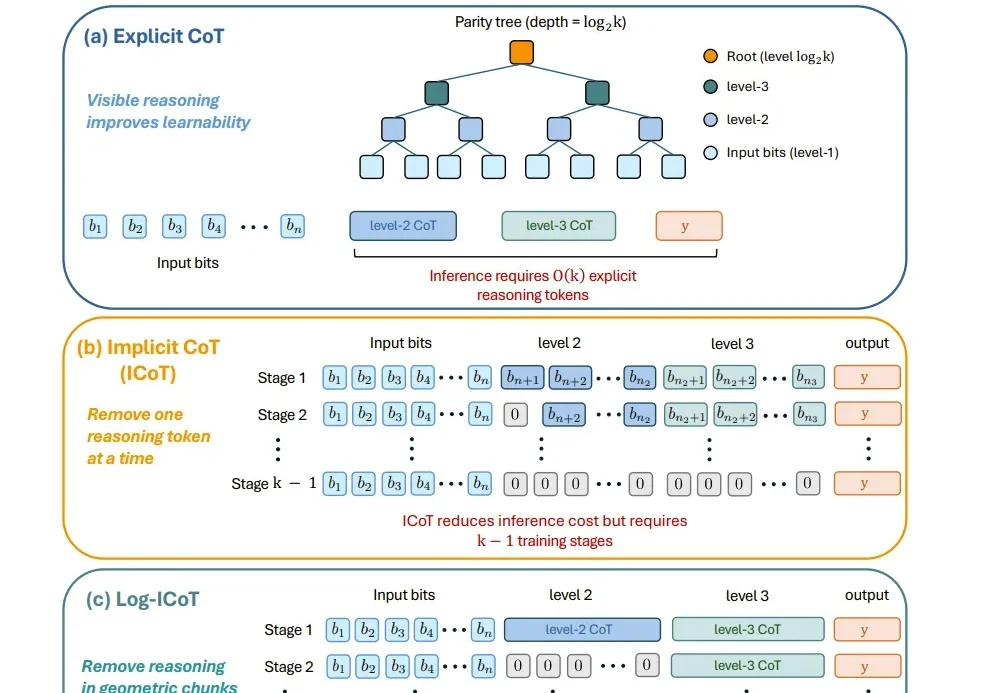
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。