# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
史上首篇潜空间推理综述,对这种新兴的推理范式进行了全面总结。
这篇综述当中,作者分析了循环、递归、连续思维等潜空间推理的形式,并将这些方法总结成了一个框架。
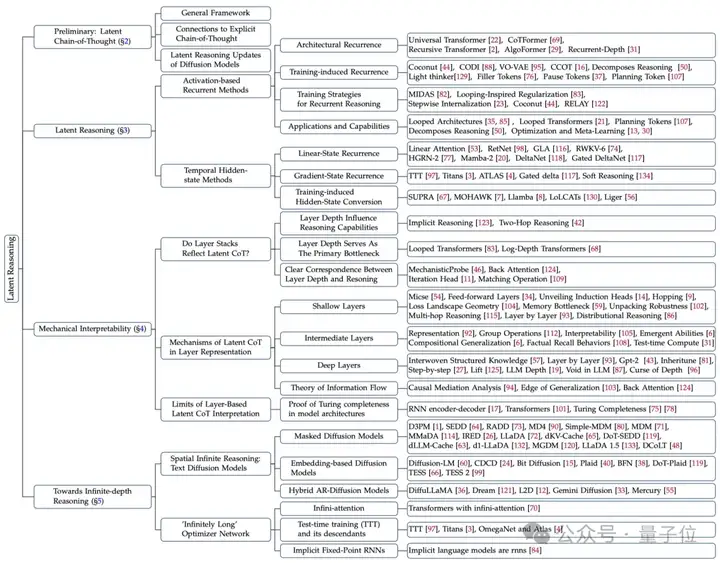
这个统一框架不是强行整合,而是建立在机械可解释性的基础之上,能够与模型的内部运作进行联系。
作者表示,这一框架还将有助于未来的路线探索,例如研究通过扩散模型进行无限深度推理等高级范式。
这篇综述共同一作有四人,其中字节SEED实习生、加州大学圣克鲁兹分校博士生Ruijie Zhu同时是通讯作者。

潜空间推理是一个新兴领域,其思想最早可以追溯到ICLR 2019上阿姆斯特丹大学学者Mostafa Dehghani与谷歌大脑和DeepMind(后两者当时处于独立状态)共同发表的《Universal Transformers》。
这篇文章引入了自适应计算时间(ACT)机制,首次实现了层级间的动态递归,为后续的潜空间推理研究奠定了基础。

此外比较著名的研究还包括Meta的Coconut,入选了今年的顶会COML。

今年年初,在潜空间推理这个方向上也有不少新作发表,表明这极有可能是一个待挖掘的新方向。

那么,潜空间推理到底是个什么概念?
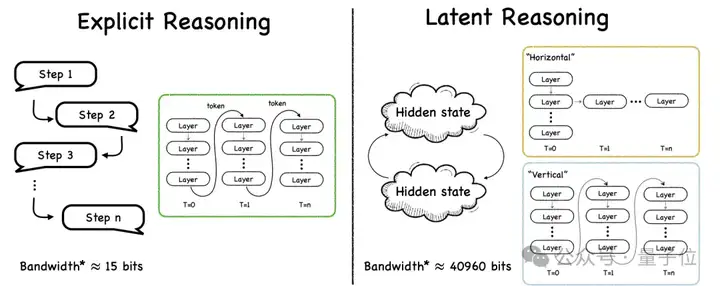
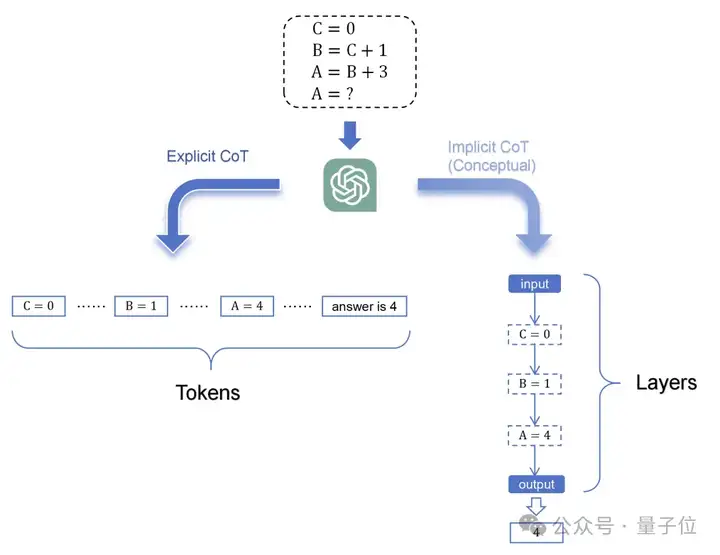
与显式推理相同,潜空间推理也要用到思维链,但不同的是其中的思维链是潜式思维链(Latent Chain-of-Thought)。
这种潜式思维链以内部连续的形式表示推理,构成一个抽象的推理轨迹,而不用离散的自然语言(Token)表示推理过程。
这样一来人类会无法看懂大模型的推理过程,但带来的好处是带宽的巨额提升。
显式CoT当中每个token约为15bits,而潜式CoT操作的高维隐藏状态,例如在2560维FP16当中,每步大约相当于40960bits,带宽比显式CoT提升了2700多倍。
并且由于推理中不使用Token,这种方法中模型不受有限词汇表的限制,可以探索没有直接语言对应物的推理轨迹,带来了更丰富的表达能力。
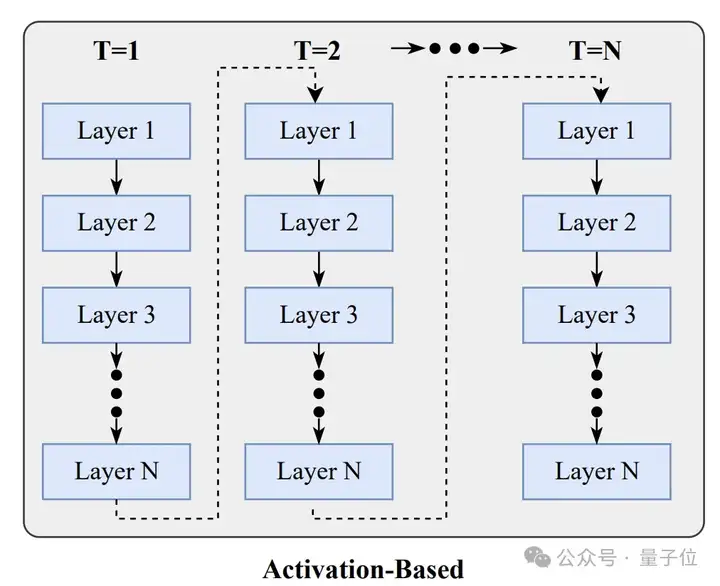
而在具体处理过程上,潜空间推理主要有两种模式——垂直循环和水平循环。
垂直循环是一类基于激活的方法(Activation-based Methods),这类方法通过扩展计算深度来实现推理。
具体来说是在固定的时间步内,通过重复处理同一组层来增加计算深度,说得再通俗一些,就是让模型反复思考同一个问题。
这种方式可以从架构、训练等不同层面实现,因此包含有多种变体。
垂直循环的优势在于能够为复杂问题分配更多计算资源,通过增加迭代次数来处理需要多步推理的任务。
但其局限性在于需要在固定的层数约束下工作,当推理链变得非常长时,可能会遇到梯度消失或爆炸的问题。
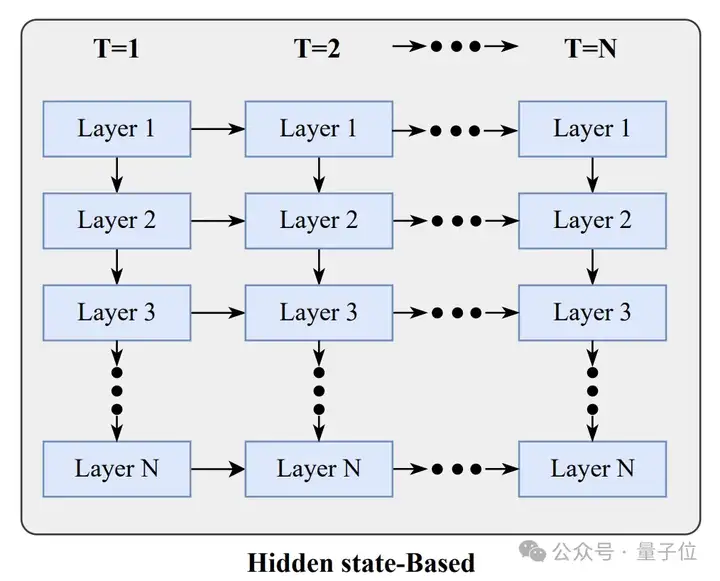
水平循环则基于隐藏状态,专注于沿时间维度扩展模型的记忆和推理能力,基本思路是维护一个压缩的隐藏状态,该状态能够聚合来自多个时间步或空间上下文的信息。
这种方法可以利用历史表示来指导当前的计算,有效创建了一个跨越多层或时间步的记忆库。
其实现方式,主要包括线性状态循环(对隐藏状态应用更新和衰减规则)和梯度状态循环(将隐藏状态视为在线学习参数并进行优化)。
那么,无论垂直还是水平,这样的层堆叠是否真的构成了一种潜在的推理链呢?作者对其机械可解释性进行了分析。
综合多份文献,作者发现层深度与模型推理能力之间存在着紧密的关联关系。
去年,清华大学硕士生俞一炅的一篇题为《Do LLMs Really Think Step-by-step In Implicit Reasoning?》的论文(2411.15862)表明,模型的隐式思维链能力严格受到网络层数的限制。

在一个需要5步推理的任务中,虽然中间结果会在某些层中出现,但由于层数不足,最终的推理结果无法涌现。
这就像建造一座需要10层楼高度的建筑,但只有8层楼的材料,无论如何优化设计,都无法达到预定的高度。
今年,UC伯克利Tianyu Guo等人的发现(2502.13913)进一步支持了这个观点——至少需要2-3层,才能在模型内部形成完整的两步推理链。
如果层数不足或后续层的深度不够,就会阻碍执行多跳推理的能力。
这表明层深度不仅影响推理的复杂程度,更是推理能力实现的基础门槛。

进一步地,谷歌研究院的Nikunj Saunshi等人在今年ICLR上发布的论文中正式建立了一个重要定理(2502.17416):
任何执行m步思维链推理的K层transformer都可以通过m次迭代前向传播被(L+O(1))层transformer模拟。

这个定理从根本上确立了层深度作为潜在推理容量主要瓶颈的地位,其中可实现的思维链步长与层数呈线性关系。
继续进行深入,不同深度的层在推理过程中展现出了明确的功能分化,类似于流水线作业中不同工位的专门化分工。
理解了层的特化分工后,信息如何在这些专门化层之间流动就成为了新的问题。
苏黎世联邦理工学院的Stolfo等人通过量化MLP和注意力模块的间接贡献(2305.15054),阐明了大模型在算术任务中的内部信息流路径。

结果突出了注意力机制在推理过程中层间信息流的关键作用——将计算信息从早期处理层传输到最终token。
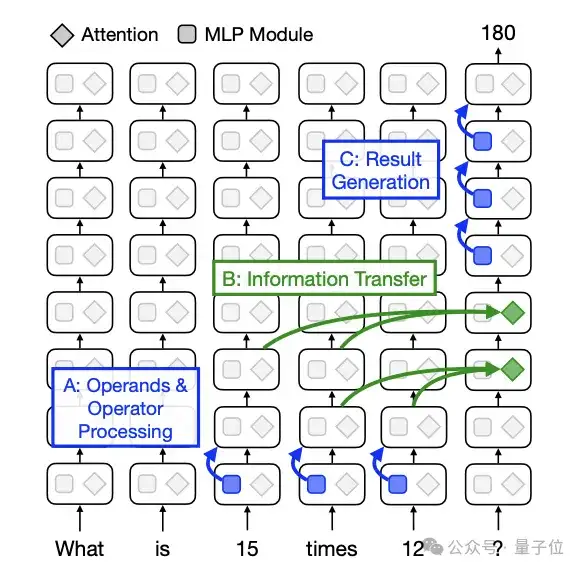
更多研究表明,这种信息流动并非单向的线性传递,还包含跨层信息流,甚至“反向注意力”机制表明,隐藏信息可以有效地从较高层传输到较低层,增强模型的推理能力。
这种双向的信息流动机制确保了推理过程中信息的充分整合和利用。
此外,研究者提出了“无限深度推理”的假想,也就是让AI能够投入无限的“思考时间”来完善解决方案,不受输出长度限制,并能根据问题复杂度动态分配计算资源。
这个概念通过两种主要途径实现——空间无限推理和时间无限推理。
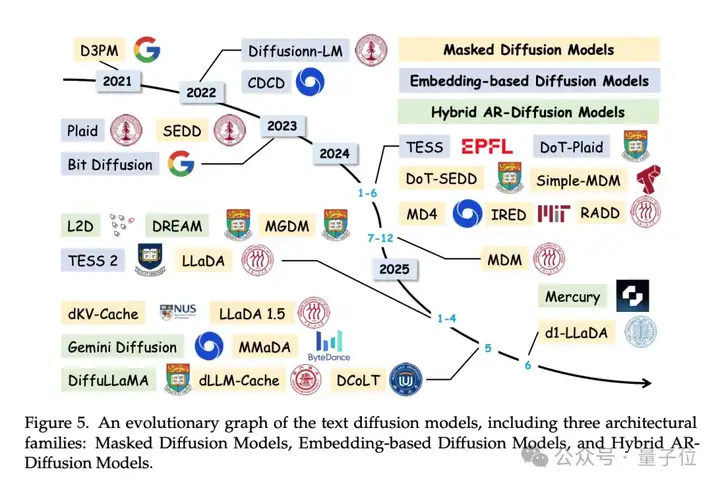
空间无限推理通过文本扩散模型实现,从完全遮蔽或含噪声的整个输出序列开始,通过迭代去噪并行处理所有位置。每次迭代都能访问完整的双向上下文,优化步数可在推理时调整。
作者在综述中具体介绍了三种文本扩散模型。
时间无限推理则是基于一个核心洞察——时间可以交换网络深度。
当隐藏状态通过梯度类规则更新时,每个额外token执行一个优化步骤来优化隐式层。处理更长序列等价于让同一层运行更多优化迭代,在不增加参数情况下产生更大推理深度。
作者同样介绍了三种具体方法:
总之作者认为,这些高级范式,也可以通过与潜空间推理同样的统一视角来理解。
作者希望,这篇综述能够清晰地阐明潜空间推理这一领域,并激发新的、更具整合性的研究方向。
论文地址:
https://arxiv.org/abs/2507.06203
文章来自于“量子位”,作者“克雷西”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
