# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让大模型感知知识图谱知识?
蚂蚁联合实验室:利用多词元并行预测给它“上课”。
大语言模型的飞速发展打破了许多自然语言处理任务间的壁垒。通常情况下,大语言模型以预测下一个词元(Token)为训练目标,这与许多自然语言处理任务十分
契合。
但对于知识图谱而言,实体作为最基本的数据单元,往往需要多个自然语言词元才能准确描述,这导致知识图谱与自然语言之间存在明显的粒度不匹配。
为了解决这一问题,蚂蚁团队提出了一种基于大语言模型的多词元并行预测方法K-ON,其利用多词元并行预测机制能够一次生成对所有实体的评估结果,进而实现
语言模型实体层级的对比学习。

其结果收录于AAAI 2025 Oral。论文一作目前在浙江大学攻读博士。
实验结果表明,本文方法在多个数据集上的知识图谱补全任务中均优于现有方法。
词元是语言模型所能处理的最基本元素,通常需要数个词元组成的文本标签才能准确描述和鉴别知识图谱中的实体。虽然为每个实体创建一个新的词元并在微调过程
中学习这些词元的表示不失为一种替代方案,但这种方式训练调优成本较高,且可能会对大模型的性能产生负面影响,通用性也受到限制。
本文探讨了如何高效利用多个词元描述知识图谱中的实体以解决知识图谱相关问题的方法。首先,直接优化经典的序列预测损失可能会导致大模型缺乏对知识图谱实
体的认识,从而出现生成知识图谱中不存在的实体的问题;且考虑到知识图谱中实体的数量,将所有实体以文本上下文的方式输入给大模型显然也是不现实的。
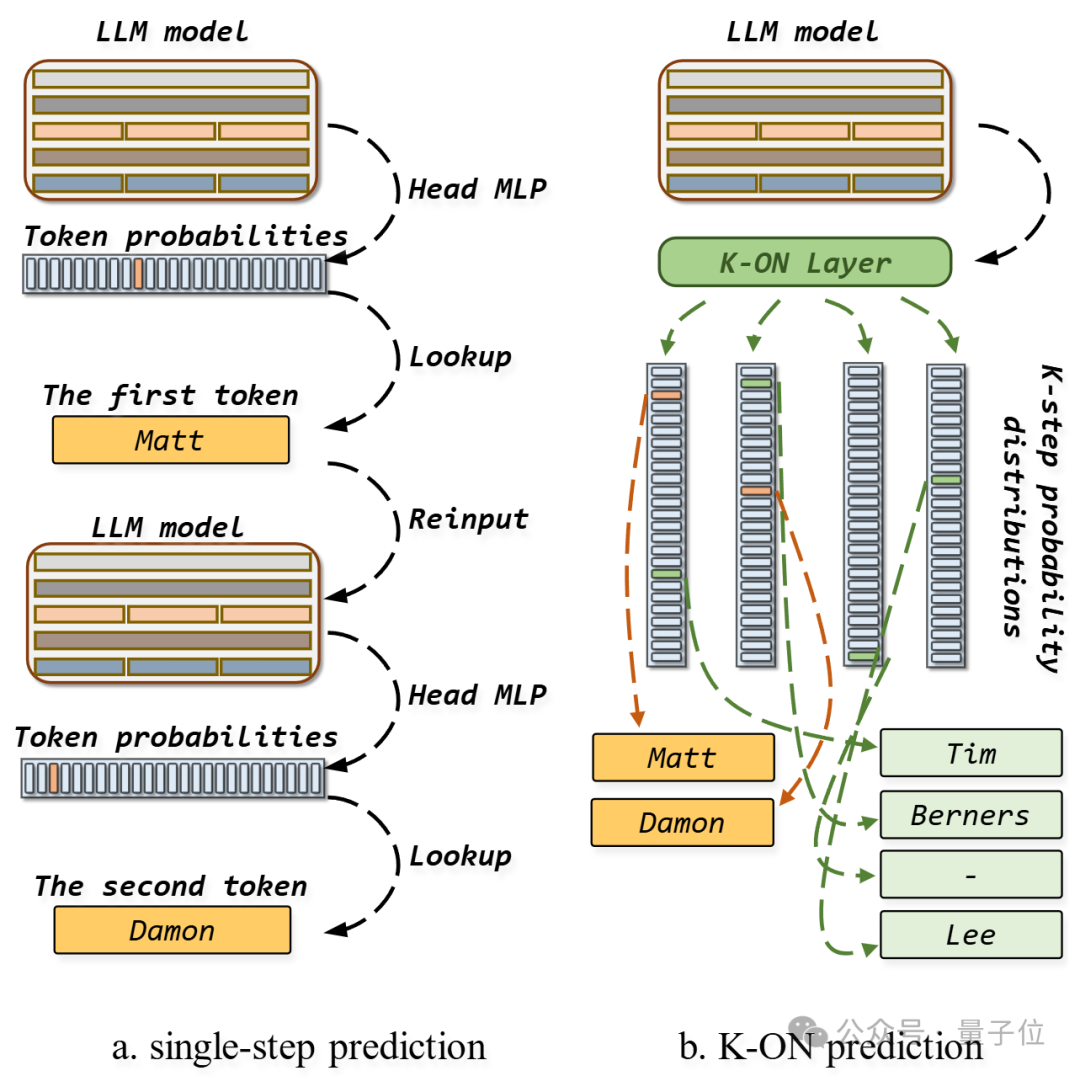
以上图为例,假设任务是给定不完整三元组以预测目标实体Matt Damon。左图中使用常规连续单词元预测方式生成结果需要多个子步骤,且无法直接处理多个实
体。因此,现有大多数知识图谱相关方法仅将大模型应用于简单任务上,如验证三元组的正确性或从有限数量的候选实体中选择正确答案。
相比之下,本文提出的K-ON方法使用K个输出层并行预测多个实体不同位置词元的概率,这与目前DeepSeek等大模型中使用的多词元预测技术有着一定的相似性,
且本文方法进一步借助了实体层级的对比学习在模型输出层上累加知识图谱知识。
如下图所示,K-ON并行评估知识图谱候选实体分数的过程可分为五步:
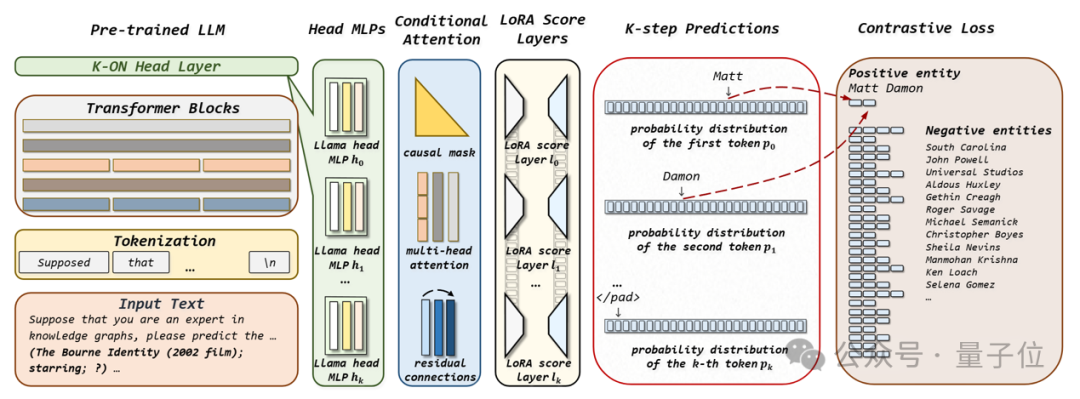
(1)与现有微调大模型的方法相似,K-ON将知识图谱补全问题以文本指令的方式输入大模型;
(2) 经大模型Transformer模块处理后的输出状态被输入至K-ON模块中,该模块由多个原大模型输出层MLP构成,对应为要预测实体的不同位置的词元;
(3) 接着,K-ON使用Conditional Transformer混合不同位置的信息,并考虑到词元前后的顺序依赖性;
(4) 然后,使用低秩适应技术(LoRA)将原大模型评分层构造为K个新的评分层,从而把上一步的输出结果转换为对实体K个连续词元的概率预测分布;
(5) 最后便可以从不同位置的概率预测分布中抽取各实体词元对应的概率值,进而一次评估所有候选实体的分数。
在获取候选实体分数后,便可使用知识图谱表示学习领域中最为常用的对比学习损失使大模型掌握知识图谱中实体的分布:
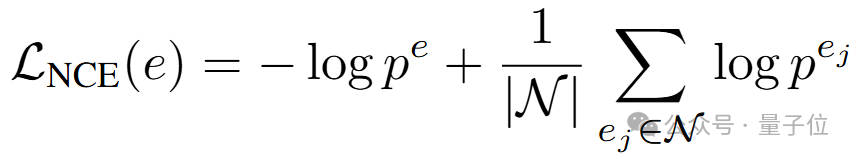
此处 pe、 pej分别代表正样本和负样本的分数,均由K-ON模块并行生成。除了实体层级的对比学习外,本文还进一步考虑使用词元序列对齐使多词元并行预测的结
果与原本大模型单步连续预测的结果相接近。为实现这一目标,本文首先引入常用的单步预测损失以在训练语料上微调原输出层参数:
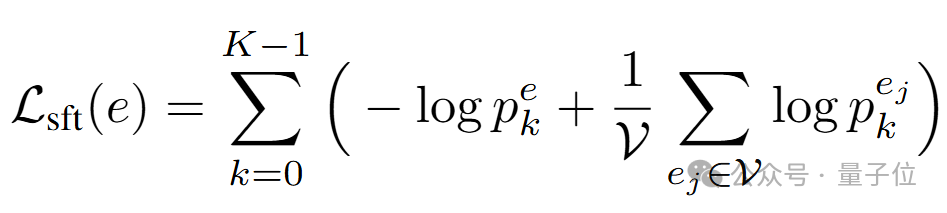
这里的下标k指代组成实体的词元的序号。
接着便可令K-ON模块中一次评估的K个词元的概率分布与常规连续单词元预测得到的K个概率分布对齐:
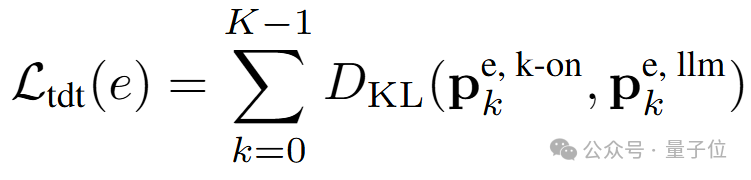
此处上标 k-on、llm 分别指代K-ON和常规连续预测所得到的分数。
最后,训练K-ON完成知识图谱补全任务的基本流程可总结如下:

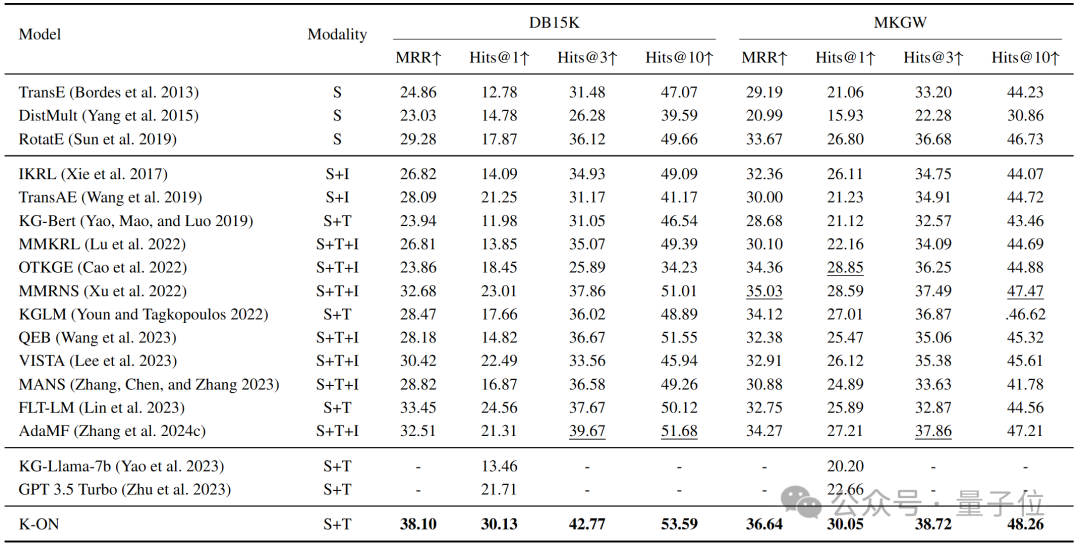
下表展示K-ON在知识图谱补全任务上的实验结果,除传统方法外,本文还与同样基于大模型的方法以及多模态方法进行了比较。不难看出,K-ON在所有数据集及指
标上均取得了优于现有方法的结果,且与一些使用额外图像数据的方法相比,仍具有一定优势。
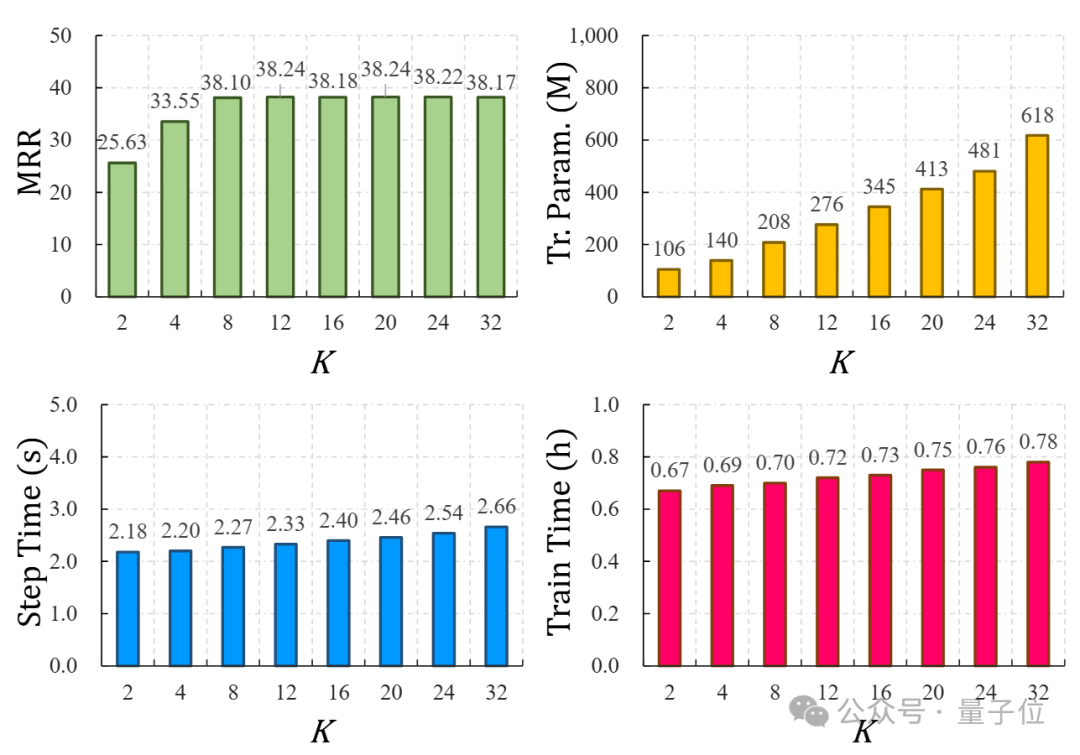
下图中进一步分析了K-ON中随着K值的增加,模型各方面性能的变化,这里K的取值直接决定了单个实体最多可以由多少词元表达。如图所示,当K取值过小时,由
于表达能力不足,K-ON取得的实验结果很差,但增加至8以后带来的性能提升已不明显,而模型可训练参数量却稳步上升。
值得注意的是,推理所用单步时间及总训练时间受K值影响不大,这说明了K-ON多词元并行预测的高效性。
不仅如此,本文还对K-ON所实现的实体层级的对比学习进行了分析,如下图所示。可以看出,在几乎不对训练效率造成影响的前提下,K-ON可轻易实现涉及上千个
负样本实体的对比学习,但负样本数量并不是越多越好,将其设为128个左右便可取得最优结果。

本文提出了一种多词元并行预测方法,通过实体层级的对比学习使大模型能够感知知识图谱知识。充分的实验结果表明,本文方法在知识图谱相关任务上具有显著性
能优势,并且较常规大模型方案具有更高的训练与推理效率。
论文地址:
https://arxiv.org/pdf/2502.06257
当地时间2月25日,AAAI 2025将在美国宾夕法尼亚州费城举办,会议为期11天,于3月4日结束。AAAI 由国际人工智能促进协会主办,为人工智能领域的顶级国际
学术会议之一,每年举办一届。AAAI 2025 共有12957篇有效投稿,录用3032篇,录取率为 23.4%。
蚂蚁有18篇技术Paper收录,其中3篇Oral,15篇Poster,研究领域涉及增强大模型隐私保护、提高推理速度与推理能力、提升大模型训练效率、降低模型幻觉等。
文章来自于微信公众号 “量子位”,作者 :蚂蚁




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
