# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在实际应用中,我们常常需要模型输出具有严格结构的数据,比如生物制药生产记录、金融交易报告或医疗健康档案等。这种结构化输出的需求在生物制造、金融服务、医疗健康等严格监管的领域尤为重要。
随着DeepSeek走入社会各界,AI应用对结构化数据的要求也越来越高,没有结构化数据,构建AI应用是不可想象的。目前很多企业都面临数据清洗的难题。以生物制药行业为例,生产记录通常以多种格式存在:
这些记录需要被转换为标准的数字化格式以满足监管要求和数据分析需求。传统的LLM虽然能够理解这些记录的内容,但在保持输出格式的严格一致性方面往往表现不佳。您也可以看下:
2024 Article
微软和麻省理工权威发布:Prompt格式显著影响LLM性能,JSON比Markdown准确性高42%
重磅惊雷,用结构化RAG约束JSON响应格式化,复合AI系统输出成功率高达82.55%
本文将详细介绍一种新的解决方案——ThinkJSON,这是一种基于强化学习和监督微调的创新方法,能够显著提高LLM结构化输出的准确性和可靠性。

ThinkJSON的核心理念是将结构化输出视为一个推理过程,而不是简单的文本生成任务。这种方法首先通过合成数据构建训练集,然后利用迭代式LLM推理来确保模式符合性。整个系统的流水线如图1所示:
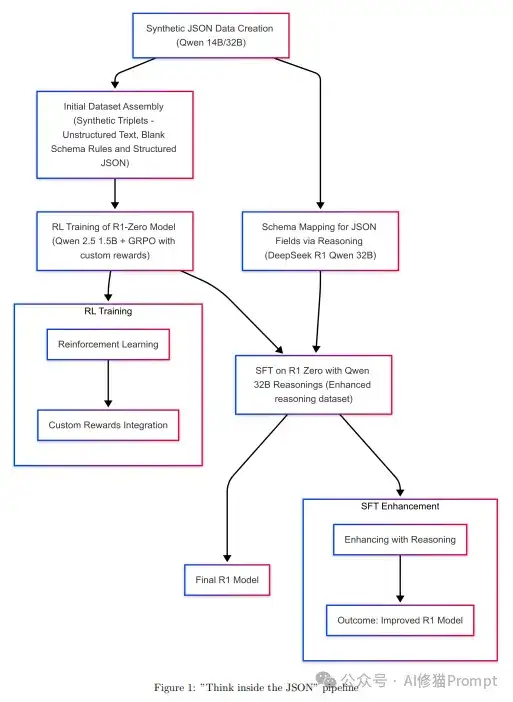
该流水线包含以下关键步骤:
1. 数据准备阶段:
- 使用Qwen 14B/32B模型生成合成的JSON训练数据
- 构建初始数据集,包含非结构化文本、模式规则和结构化JSON的三元组
2. 模型训练阶段:
- 对R1-Zero模型进行强化学习训练,使用Qwen 2.5 + GRPO方法
- 实现自定义奖励机制,优化模型输出质量
3. 模式映射阶段:
- 使用DeepSeek R1 Qwen 32B进行JSON字段映射
- 加入推理能力,提高字段匹配准确性
4. 监督微调阶段:
- 在R1 Zero基础上使用Qwen进行SFT
- 使用增强的推理数据集提升模型性能
5. 最终优化:
- 通过推理增强进一步改进模型
- 生成最终的结构化输出模型
这种端到端的流水线设计确保了模型能够:
- 理解不同格式的输入数据
- 进行准确的字段映射和提取
- 生成符合预定义模式的JSON输出
- 通过持续优化提高处理质量
根据以上方法,我写了一个多Agent协同架构,用于该架构包含以下关键组件:

图片由修猫创作
1.多Agent协同架构:
2.多维度奖励机制:
3.格式自适应处理:

在生成训练数据时,研究者采用了精心设计的prompt模板。以下是关键的prompt设计:
1. 结构化数据生成prompt:
You are an expert in building a hierarchical JSON schema andobjectfor the domain {DOMAIN}.
Your task is to create:
1. A multi-level JSON Schema describing:
- ROOT (level 0),
- SECTION (level 1),
- SUBSECTION (level 2),
- $DETAIL_{N}$ (level 3+).
Each level may contain tables and checkbox elements,
with nested components reflecting complex structures.
2. A JSON Object that strictly matches this schema.
Formatting Requirements:
- Escape all quotes (\"), replace newlines with \\n
- No trailing commas, single quotes, or extra data
2. 非结构化文本生成prompt:
You are an expert in generating hierarchical text documents from JSON Object data points.
Task: Convert the JSON Object into an unstructured, paragraph-based document.
Layout References:
- Layout options for components/levels
- Table styles
- Checkbox styles: [ ], YES, NO, N/A, etc.
RULES:
1. Map every JSON level, component, and attribute to the correct layout/style.
2. Surround JSON data points with additional words/sentences.
3. Include all data (title, variables, metadata, content).
4. Add filler paragraphs for context.
这些prompt设计确保了生成数据的质量和多样性,为模型训练提供了坚实的基础。
ThinkJSON的实现过程分为两个主要阶段:
使用DeepSeek R1作为基础模型,通过群组相对策略优化(GRPO)进行训练。这个阶段的关键特点包括:
训练配置示例:
training_config = {
'base_model': 'deepseek-r1',
'batch_size': 32,
'learning_rate': 2e-5,
'warmup_steps': 100,
'max_steps': 10000,
'gradient_accumulation_steps': 4,
'max_grad_norm': 1.0,
'group_size': 8
}
reward_weights = {
'json_completeness': 0.3,
'field_existence': 0.2,
'type_correctness': 0.2,
'format_difficulty': 0.3
}
训练循环的核心逻辑:
deftrain_step(batch, model, optimizer):
# 生成多个候选输出
outputs = []
for _ inrange(training_config['group_size']):
output = model.generate(batch['input'])
outputs.append(output)
# 计算奖励
rewards = []
for output in outputs:
json_reward = compute_json_reward(output, batch['target'])
format_reward = compute_format_reward(output)
combined_reward = (reward_weights['json_reward'] * json_reward +
reward_weights['format_reward'] * format_reward)
rewards.append(combined_reward)
# 计算相对优势
advantages = compute_relative_advantages(rewards)
# 更新模型
loss = compute_grpo_loss(outputs, advantages)
loss.backward()
optimizer.step()
return loss.item()
在强化学习建立基础能力后,通过监督微调(SFT)进行最终的任务特定优化:
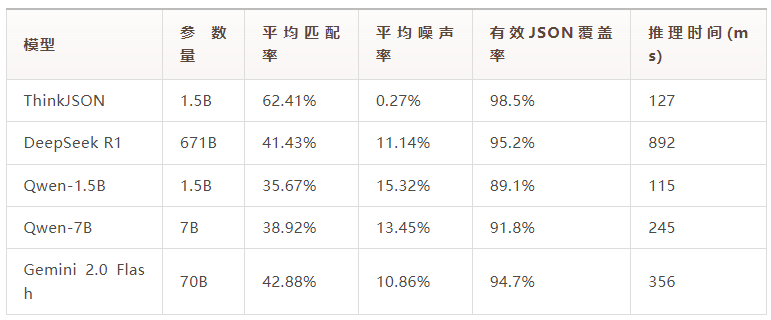
ThinkJSON在结构化数据提取基准测试中展现出优异性能:
这些结果证明了ThinkJSON在保持输出质量的同时,能够有效确保结构化格式的准确性。
在6.5K条测试数据上的详细评估结果:
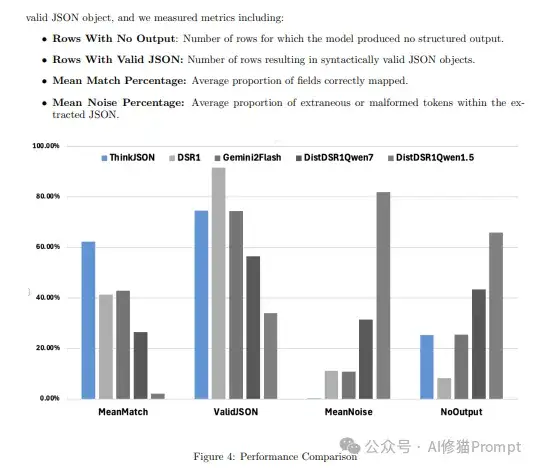
ThinkJSON的应用场景广泛,特别适合以下领域:
在生物制造领域,需要将大量遗留生产记录转换为结构化的数字格式以满足合规要求。ThinkJSON能够:
在金融服务领域,大量的文档需要进行结构化处理:
医疗记录的数字化转换需要严格的格式控制:
某生物制药公司使用ThinkJSON处理历史生产记录。系统采用Agent架构,包含以下组件:
系统支持处理四种不同格式的生产记录:
系统使用多维度的奖励计算机制评估处理质量:
不同格式的处理难度系数:
实施效果:
系统的主要优势:
对于想要实施ThinkJSON的工程师,以下是一些关键建议:
1.数据预处理:
defpreprocess_data(raw_text):
# 清理文本
cleaned_text = remove_special_chars(raw_text)
# 标准化格式
normalized_text = normalize_format(cleaned_text)
# 分段处理
sections = split_into_sections(normalized_text)
return sections
defvalidate_json_schema(json_obj, schema):
try:
jsonschema.validate(json_obj, schema)
returnTrue
except jsonschema.exceptions.ValidationError as e:
logger.error(f"Schema validation failed: {e}")
returnFalse
2. 性能优化:
# 缓存策略
from functools import lru_cache
@lru_cache(maxsize=1000)
defprocess_document(doc_id):
# 处理文档并返回结构化数据
pass
# 批处理优化
defbatch_process(documents, batch_size=32):
results = []
for i inrange(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
batch_results = process_batch(batch)
results.extend(batch_results)
return results
3. 错误处理:
classStructuredOutputError(Exception):
pass
defsafe_process(text):
try:
# 首次尝试处理
result = model.process(text)
ifnot validate_output(result):
# 失败后的重试策略
result = fallback_process(text)
return result
except Exception as e:
logger.error(f"Processing failed: {e}")
raise StructuredOutputError(f"Failed to process text: {str(e)}")
ThinkJSON通过创新的思维驱动方法,成功解决了LLM结构化输出的关键挑战。它不仅展现了优异的性能,还提供了一个可扩展的框架,能够适应不同领域的需求。对于正在开发AI产品的工程师来说,这种方法提供了一个既实用又高效的解决方案,值得在实际项目中尝试和应用。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
