# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,当大家以为开源周已经结束的时候,真「Open AI」DeepSeek带来了压轴大戏——DeepSeek-V3/R1推理系统,全面揭秘!
吞吐量和延迟优化:
在线服务性能数据:
DeepSeek表示,希望本周分享的技术见解能为开源社区带来价值,共同推进通用人工智能的发展目标。
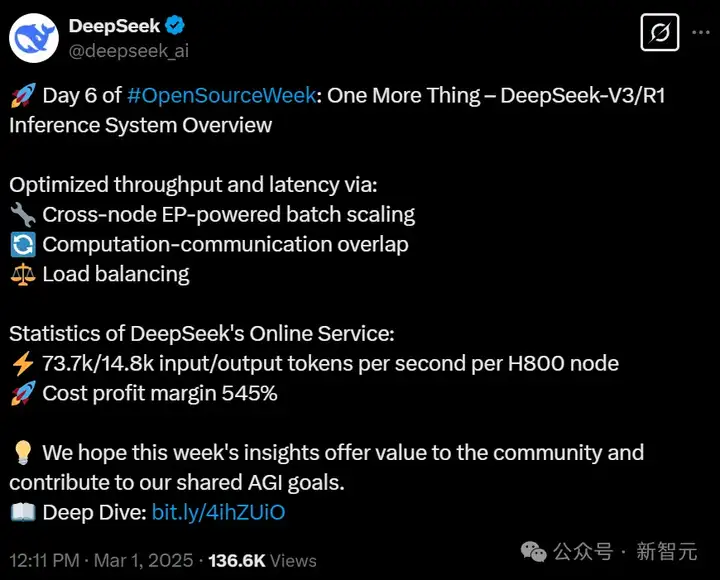
看到这里,网友都惊了!
所以,基本免费的DeepSeek成本利润率高达545%,而堪称世界最贵的OpenAI却在亏损?
系统设计原则
简单来说,DeepSeek-V3/R1推理服务的优化目标是:提高吞吐量和降低延迟。
为了实现这两个目标,团队采用了跨节点专家并行(Expert Parallelism,EP)技术。
首先,EP显著扩大了批处理规模,提高了GPU矩阵计算效率,从而提升吞吐量。
其次,EP将专家模块分布在不同GPU上,每个GPU仅处理少量专家模块(减少内存访问需求),从而降低延迟。
然而,EP也增加了系统复杂度,主要体现在两个方面:
2.EP涉及多个节点,因此必然需要数据并行(Data Parallelism,DP),并要求在不同DP实例之间进行负载均衡。
为此,DeepSeek通过以下方式应对这些挑战:
DeepSeek-V3/R1中包含大量专家模块:每层256个专家中仅激活8个,所以模型的高稀疏性特点要求采用极大的整体批处理规模。
这样才能确保每个专家模块获得足够的批处理量,从而实现更高的吞吐量和更低的延迟。因此,大规模跨节点EP技术成为必不可少的选择。
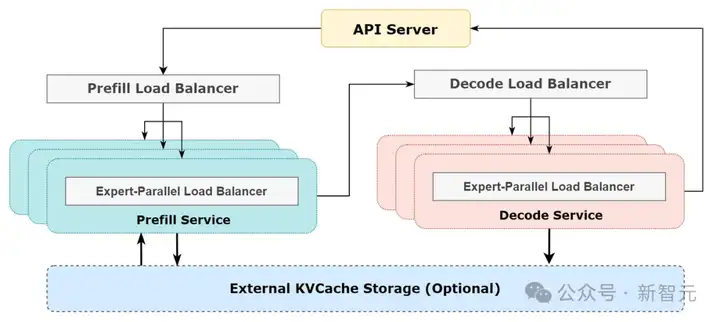
DeepSeek采用了预填充-解码解耦架构(prefill-decode disaggregation architecture),在预填充和解码阶段分别采用不同程度的并行策略:
2.解码阶段「路由专家EP144,MLA/共享专家DP144」:每个部署单元跨越18个节点,配置32个冗余路由专家,每个GPU管理2个路由专家和1个共享专家。
大规模跨节点EP技术引入了显著的通信开销。
为了缓解这一问题,采用dual-batch重叠策略,将同一批请求分割为两个microbatch,以隐藏通信成本并提高整体吞吐量。
在预填充阶段,两个microbatch交替执行,一个microbatch的通信开销被另一个microbatch的计算过程所掩盖。
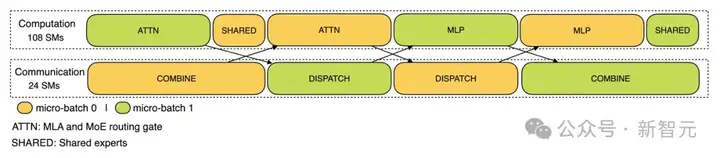
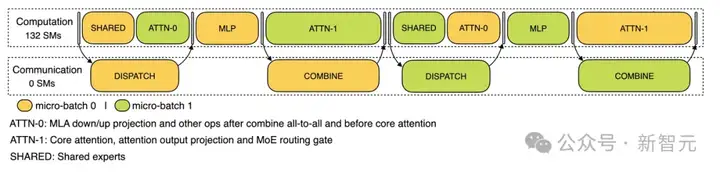
在解码阶段,各执行阶段的时长存在不平衡现象。
为此,需要将注意力层细分为两个步骤,并采用五阶段流水线(5-stage pipeline)技术,实现计算与通信的无缝重叠。
大规模并行(包括数据并行DP和专家并行EP)带来了一个关键挑战:如果单个GPU在计算或通信方面过载,它将成为整个系统的性能瓶颈,导致系统速度下降,同时造成其他GPU资源闲置。
为了最大限度地提高资源利用率,DeepSeek的目标是在所有GPU上实现计算和通信负载的平衡。
1. 预填充阶段负载平衡器
2. 解码阶段负载平衡器
3. 专家并行负载平衡器
DeepSeek在线服务统计数据
所有DeepSeek-V3/R1推理服务均在H800 GPU上运行,精度与训练保持一致。
具体而言,矩阵乘法和分发传输采用与训练一致的FP8格式,而核心MLA计算和组合传输使用BF16格式,确保最佳的服务性能。
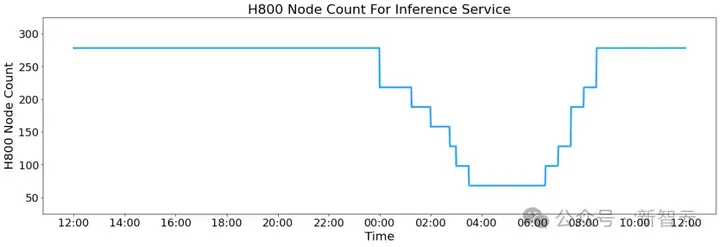
此外,由于白天服务负载高而夜间负载低,团队采取了一种创新的机制:
在白天高峰时段,所有节点都部署推理服务;
在夜间低负载时段,减少推理节点并将资源分配给研究和训练。
在过去24小时内(02月27日中午12:00至02月28日中午12:00),V3和R1推理服务的合计峰值节点占用达到278个,平均占用226.75个节点(每个节点包含8个H800 GPU)。
假设租赁一个H800 GPU的成本为每小时2美元,每日总成本为87,072美元。
在24小时统计期内,V3和R1:
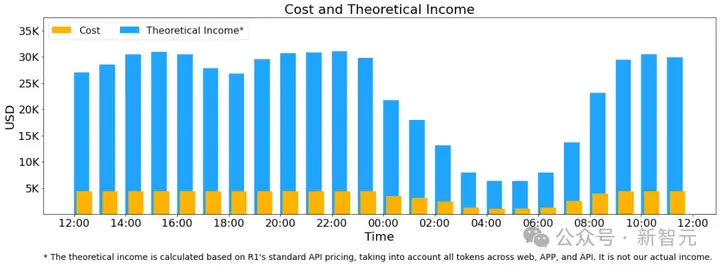
上述统计数据包括来自网页、APP和API的所有用户请求。
如果所有token都按照下列DeepSeek-R1的定价计费,每日总收入将达到562,027美元,利润率为545%。
R1定价:输入token(缓存命中)每百万0.14美元,输入token(缓存未命中)每百万0.55美元,输出token每百万2.19美元。
然而,实际收入大幅低于此数字,原因如下:
参考资料:
https://x.com/deepseek_ai/status/1895688300574462431
文章来自于微信公众号“新智元”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
