# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
农历新年刚过,DeepSeek卷王依旧,这次一下子进行了接连六天的开源Week。
它这次是开源针对Infra层,告诉所有人为何自己的模型能够把效率卷到极致。 EPIC进行了详尽整理,欢迎和我们一起学习DeepSeek的Infra“黑科技”。
FlashMLA是一款新一代高效MLA(Multi-HeadLatency-Aware)解码内核,专为HopperGPU进行优化。它支持BF16&FP16数据格式,采用PagedKVCache(块大小64)和智能Tile计算调度,在H800SXM5GPU上实现580TFLOPS计算性能&3000GB/s内存带宽。此外,FlashMLA适配国产AI硬件生态,成功解决了变长序列推理的计算效率问题,显著提升LLM生成任务的推理性能。这项技术未来有望成为大模型推理优化的关键组件,助力AI计算进入更高效、更智能的新阶段。
FlashMLA就像高速公路的智能潮汐车道系统。早晚高峰时,无论短途通勤车(短序列)还是长途货车(长序列),都能根据实时流量自动调整车道宽度(动态显存分配)。传统系统让所有车辆挤在固定车道,而它能将不同车型拆解成模块,像乐高积木一样重组到不同车道(并行解码),让特斯拉和比亚迪(不同厂商GPU)的车辆都能用同套系统,提速3倍,高峰期通行效率提升却不用扩建路基(硬件成本不变)。
核心创新:
FlashMLA专为变长序列推理任务进行优化,通过智能Tile计算调度和PagedKVCache机制,使不同长度的序列都能高效计算,减少填充(padding)带来的计算浪费。这一优化对于实时推理和大模型生成任务(如LLM)至关重要,能够显著降低延迟,提高吞吐量。此外,在H800SXM5GPU上,FlashMLA在计算受限场景下可达580TFLOPS,在内存受限场景下可达3000GB/s带宽,充分发挥Hopper架构的计算和带宽潜力。同时,FlashMLA还适配MetaX、MooreThreads、HygonDCU、Intellifusion和IluvatarCorex等国产AI硬件生态,推动国产AI硬件的推理能力提升。
技术要点:
FlashMLA采用BF16和FP16数据格式,在提升计算吞吐量的同时,保证计算稳定性。相比FP16,BF16拥有更宽的指数范围,更适合深度学习推理场景中的大数值计算。此外,FlashMLA采用PagedKVCache(分页Key-Value缓存),块大小64,优化跨序列key-value存储和读取,减少缓存开销,降低KV读取的带宽消耗,是其在H800GPU上实现3000GB/s超高带宽的关键技术。同时,智能Tile计算调度使得FlashMLA能够动态拆分计算任务,根据查询张量的维度自动调整计算负载,让GPU计算单元始终保持高效负载均衡。FlashMLA依赖CUDA12.3及以上版本(推荐12.8以获得最佳性能),并兼容PyTorch2.0及以上,方便与主流深度学习框架集成,提升开发和部署效率。
深度解读:为什么FlashMLA重要?
在变长序列推理任务中,传统Transformer处理方式需要对不同长度的输入序列进行填充(padding),导致大量计算资源浪费。FlashMLA通过动态Tile计算调度和PagedKVCache机制,使不同长度的输入都能高效计算,提高GPU资源利用率。此外,长序列推理的关键问题之一是KV缓存的存储和读取,FlashMLA通过分页KV机制,减少存储带宽瓶颈,优化GPU计算负载均衡,提升推理吞吐量。
概览:
DeepEP是首个开源的专家并行(EP)通信库,专门用于MoE(Mixture-of-Experts)模型的训练和推理优化。它提供高吞吐的all-to-all通信内核,能够在NVLink和RDMA之间高效传输数据,提升专家分发(dispatch)和合并(combine)过程的计算效率。DeepEP还支持FP8低精度计算,并采用计算-通信重叠机制,减少GPU资源浪费,提升大规模MoE训练和推理的吞吐量。
DeepEP像跨国物流公司的智能中转仓。当上海仓要同时发往纽约1000箱货(训练数据)和伦敦的加急包裹(推理请求)时,传统物流要等整船装满才发车(延迟高)。而它用双层分拣:大宗货物走海运集装箱(NVLink高吞吐),紧急件走空运专线(RDMA低延迟),还能在装车时同步打印面单(通信计算重叠),既不让货机等装货,也不让轮船空舱位。
核心创新:
DeepEP优化了GPU间的专家通信,减少了MoE训练中的通信瓶颈,特别是在多节点环境下的all-to-all数据交换。它采用NVLink(高带宽)+RDMA(远程通信)结合的方式,确保在节点内(intranode)和节点间(internode)都能高效传输数据。此外,DeepEP还针对DeepSeek-V3提出的group-limitedgating算法进行了优化,使数据流动更均衡,训练更稳定。
技术要点:
DeepEP提供高吞吐通信内核,在H800SXM5+CX7InfiniBand400Gb/sRDMA的测试环境下,单节点NVLink带宽达158GB/s,跨节点RDMA带宽达46GB/s。此外,DeepEP具备低延迟RDMA内核,适用于MoE推理解码,可将专家分发(dispatch)延迟降低至163微秒,专家合并(combine)延迟降低至318微秒。同时,DeepEP支持FP8低精度计算,并结合BF16专家合并,进一步提升计算吞吐量。
图1:DeepEP 计算-通信重叠优化机制
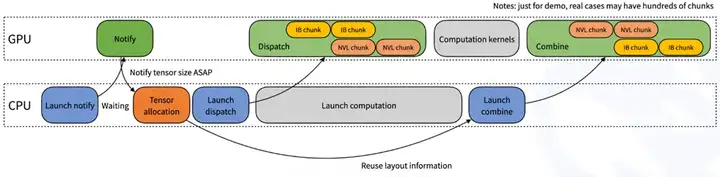
图1展示了DeepEP在ExpertParallelism(专家并行)计算中的计算-通信重叠策略。整个流程由CPU负责任务调度(通知GPU、分配张量、启动计算与合并),GPU负责执行计算任务(数据分发、计算、结果合并)。通过InfiniBand(IB)和NVLink(NVL)分块传输,系统实现了计算与通信的高效并行,最大化GPU资源利用率,并减少跨节点通信延迟,从而提升MoE(Mixture-of-Experts)推理和训练性能。
图2:DeepEP 低开销通信重叠优化:释放更多计算资源
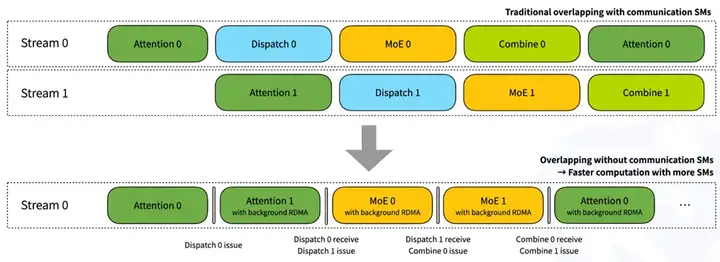
图2对比了传统计算-通信重叠方式(上半部分)与DeepEP的优化策略(下半部分)。传统方法采用多个Stream进行计算-通信重叠,但会占用通信SM资源,导致GPU计算资源浪费。而DeepEP优化后,通过RDMA后台传输(backgroundRDMA),通信过程不会占用SM,计算任务可以充分利用所有SM资源,提高计算效率,最终实现更快的推理速度和更高的GPU利用率。
深度解读:为什么DeepEP重要?
MoE训练的核心挑战在于专家之间的高效通信。传统方法使用NVLink或PCIe进行数据交换,容易受限于带宽瓶颈或计算资源占用。DeepEP通过NVLink↔RDMA非对称域优化,让数据在高带宽NVLink和远程RDMA之间流动更高效,避免资源浪费。在推理过程中,DeepEP采用纯RDMA低延迟通信,让MoE推理更加实时高效,适用于大规模生成式AI任务。此外,DeepEP还引入计算-通信重叠机制,使通信在GPU计算的后台进行,不占用流处理单元(SM),大幅提升GPU资源利用率。
概览:
DeepGEMM是一款专为FP8矩阵乘法(GEMM)设计的高效计算库,支持密集(Dense)和MoE(Mixture-of-Experts)GEMM,为DeepSeek-V3/R1训练和推理提供底层优化。DeepGEMM采用轻量级即时编译(Just-In-Time,JIT)机制,无需安装时编译,直接在运行时编译所有核心计算核,使其更加灵活。该库能够在HopperGPU上实现1350+FP8TFLOPS,并在大多数矩阵规模上超越专家调优的计算内核,同时支持两种MoE计算布局,为大规模AI训练和推理提供高效计算支持。
DeepGEMM更像是全自动混凝土搅拌站。不论盖茅草屋(小矩阵)还是造摩天楼(大矩阵),都能根据工程图纸(JIT编译)实时生成定制搅拌方案。传统搅拌机只能按固定比例混合,而它用智能传感器(FP8精度)动态调节砂石配比,既保证承重墙(关键计算)用高标号混凝土,又给装饰层(次要计算)用低成本材料,让整个工地效率提升2倍却不增设备。
核心创新:
DeepGEMM通过高效FP8矩阵计算,在HopperGPU上大幅提升深度学习推理和训练的计算效率。它采用CUDA核心双级累积(CUDA-coretwo-levelaccumulation)机制,弥补FP8精度累积的误差,并支持HopperTensorCores,从而在FP8精度下仍能保持高计算稳定性。此外,DeepGEMM通过轻量级JIT编译,避免了对CUTLASS和CuTe复杂模板的依赖,使其更易理解和使用,仅用约300行核心代码即实现高性能FP8矩阵计算。
技术要点:
DeepGEMM在H800SXM5GPU+NVCC12.8测试环境下,能够在多种矩阵规模下超越专家调优的计算内核,计算性能达到1350+FP8TFLOPS。此外,DeepGEMM无重依赖,安装时无需编译,所有计算核均通过轻量级JIT运行时编译,使其具备极高的灵活性。该库同时支持密集GEMM计算布局和两种MoE计算布局(连续布局和掩码布局),适用于大规模MoE训练与推理。
图3:DeepGEMM 的 TMA-WGMMA 并行计算优化
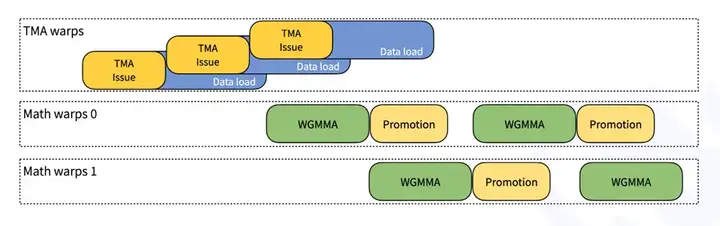
图3展示了DeepGEMM在HopperGPU上如何高效利用TensorMemoryAccelerator(TMA)和Warp-GroupedMatrixMultiply-Accumulate(WGMMA)指令以实现数据加载(DataLoad)与计算(WGMMA、Promotion)的并行优化。
1)TMA Warps负责数据加载,通过流水线方式交错执行TMA Issue和Data Load,确保计算单元始终有数据可用。
2)Math Warps(数学计算线程组)执行WGMMA计算,同时插入Promotion操作,用于处理FP8数据到BF16/FP32的累加转换,优化计算精度。
3)数据加载(TMA)和计算(WGMMA)完全并行,避免计算等待数据,从而提高矩阵乘法(GEMM)计算的吞吐量。
这一优化策略最大化了Tensor Core计算能力,提升DeepGEMM在FP8精度下的计算效率,适用于高性能深度学习推理和训练任务。
深度解读:为什么DeepGEMM重要?
在大模型训练中,FP8精度能够大幅减少存储和计算带宽开销,但同时也带来了精度损失和累积误差。DeepGEMM通过CUDA核心双级累积,有效降低FP8计算误差,并在大多数矩阵规模下超越CUTLASS,提供更优性能。此外,DeepGEMM采用即时编译(JIT)机制,无需安装时编译,使其更易集成、更易扩展,适用于深度学习推理、预填充(prefilling)以及MoE计算。它不仅优化了普通GEMM计算,也对MoE专家计算布局进行了优化,确保多专家模型(MoE)在推理和训练阶段均能高效执行。
概览:
DualPipe和EPLB(ExpertParallelLoadBalancer)是DeepSeek-V3/R1训练框架中的两项关键优化技术,分别用于管道并行(PipelineParallelism)和专家并行(ExpertParallelism)负载均衡。DualPipe采用双向管道并行(BidirectionalPipelineParallelism),使前向和反向计算阶段完全重叠,减少计算-通信等待(PipelineBubbles),从而提升训练吞吐量。EPLB则通过专家负载均衡(ExpertLoadBalancing),优化MoE(Mixture-of-Experts)训练过程中的计算分配,确保不同GPU之间的计算负载更加均衡。这两项技术共同优化计算与通信的交互模式,有效提升大规模模型的训练效率。
DualPipe就像一条双向运转的智能工厂流水线。传统流水线只能单向传递零件——比如前半段组装车身(前向计算),后半段喷漆质检(反向传播),中间总有传送带空转的等待时间(气泡)。而这条产线让每个工位都变成双面工作站:当A工位正在给第10辆车的发动机接线(前向),同时能接收第5辆车反馈的电路检修数据(反向),就像电工左右手同时操作不同工具。更巧妙的是,传送带设计成环形轨道,让组装好的车身向前流动时,质检报告逆向同步传回,整个车间像同时进行20辆车的装配和返修,将传统流水线60%的空转时间压缩到15%,代价只是每个工位多配一套工具柜(双倍参数内存)——用少许空间成本换来三倍产能提升。
EPLB就像大型超市的灵活收银台管理系统。当周末客流高峰时,生鲜区(高负载专家)的收银台排起长队,而日用品区却空闲,系统会立即做两件事:弹性增开通道:在生鲜区快速启用备用收银台(冗余专家),把新顾客分流到新增窗口,避免单一通道堵塞;关联商品集中结算:将相邻的蔬果和肉类称重台(同组专家)合并到同一收银区,顾客不用跨区排队(减少跨节点流量)。平时,超市按部门(分层策略)平衡各区域收银员,确保粮油区和零食区负载均衡;但遇到促销活动时,启动全场调度(全局策略),让服装区的空闲收银员随时支援生鲜区,就像给每个收银台装上智能眼,实时调整人力,让所有顾客的等待时间几乎相同。
核心创新:
DualPipe通过双向管道并行算法,使前向计算和反向计算同步进行,相比传统1F1B和ZB1P方式,它显著减少了管道等待时间(PipelineBubbles),并在不增加显存占用的前提下提升计算利用率。另一方面,EPLB通过专家复制(RedundantExperts)策略,将高负载的专家复制并均匀分配到不同GPU,确保不同节点的计算和通信负载均衡,同时结合DeepSeek-V3的Group-LimitedExpertRouting,减少跨节点通信,提升整体计算效率。
技术要点:
DualPipe采用双向流水线调度策略,在多个Pipeline并行等级下优化计算与通信的重叠度,减少训练中的等待时间,同时保证显存使用效率。相比传统方法,它减少了50%以上的流水线空泡,适用于超大规模Transformer训练。EPLB则提供两种负载均衡策略:层级负载均衡(HierarchicalLoadBalancing)适用于专家组数能被服务器节点整除的情况,而全局负载均衡(GlobalLoadBalancing)适用于更大规模的专家并行场景,确保不同GPU的计算资源被高效利用。
图4:DualPipe 双向流水并行:前向-反向计算重叠优化

图4展示了DualPipe的流水并行调度策略,通过前向计算(Forward,橙色)与反向计算(Backward,绿色)的高度重叠,减少流水线等待时间,提高GPU计算效率。每个设备(Device0-7)按照流水顺序执行不同的计算任务,包括前向传播、反向传播(对输入和权重的梯度计算),并通过交错调度使得前向和反向计算在时间轴上尽可能重叠,从而提升整体吞吐量。相比传统1F1B(1Forward1Backward)调度,DualPipe减少了流水线空隙,提升了计算资源利用率,适用于大规模深度学习模型的高效训练。
图5:EPLB: 专家并行负载均衡(Expert Parallel Load Balancer)

图5展示了EPLB(专家并行负载均衡)在跨节点GPU集群中如何分配专家(Experts),以实现均衡计算负载。每个Node(计算节点)内部包含多个GPU,每个GPU被分配一定数量的专家实例,以减少计算热点并优化通信效率。EPLB采用冗余专家(RedundantExperts)策略,通过复制高负载专家并智能分配到不同GPU,确保计算均衡,同时尽可能将同一组专家放置在同一节点,减少跨节点通信开销。这一机制极大提升了DeepSeek-V3MoE模型在大规模分布式环境下的推理和训练效率。
深度解读:为什么DualPipe和EPLB重要?
在大规模Transformer训练过程中,计算和通信的同步是影响训练吞吐量的关键问题。传统流水线并行方式存在计算与通信无法完全重叠的问题,导致GPU资源利用率下降。DualPipe通过双向计算调度,使前向和反向计算完全同步,减少计算空白时间,从而提升训练效率。另一方面,在MoE训练过程中,专家的计算负载通常不均衡,导致部分GPU计算过载,而部分GPU资源浪费。EPLB通过智能专家复制和负载均衡算法,确保每个GPU计算任务的均衡性,同时减少跨节点通信,最终提升MoE训练的整体性能。
概览:
Fire-Flyer文件系统(3FS)是一款专为AI训练与推理场景设计的高性能分布式文件系统。3FS充分利用现代SSD和RDMA网络的高带宽,构建了一层统一的存储层,简化了大规模分布式应用的数据管理。在180节点集群的测试环境中,3FS总读取吞吐量可达6.6TiB/s,并在GraySort测试中实现3.66TiB/min的吞吐量,展现出超高的数据存取能力。此外,3FS还具备高效的KVCache机制,可在推理任务中提供40+GiB/s的缓存查询吞吐量,为大规模V3/R1训练与推理提供核心数据支持。
3FS就像一家覆盖全国的快递中转网络。当双十一亿万订单涌来时,传统仓库只能让所有包裹挤在几个分拣中心(存储瓶颈),而它把货物分散到各县城的智能仓库(分布式节点)。每个县城仓库配备自动分拣机(SSD高速读写)和专用货运通道(RDMA网络),北京客户下单的货物可能从天津仓直发,广州的订单由深圳仓秒出。所有仓库的库存信息像直播弹幕一样实时同步(强一致性),确保不会出现“上海已售罄,杭州却显示有货”的混乱。更厉害的是,这套系统既能处理日均百万件的平稳物流(训练数据),也能应对瞬间爆发的秒杀订单(推理请求),让全国快递效率提升十倍,却不用新建仓库
核心创新:
3FS采用解耦式存储架构(DisaggregatedArchitecture),将数千块SSD的存储吞吐量和数百个存储节点的网络带宽进行融合,使应用可以无感知地访问分布式存储资源。此外,3FS采用强一致性(StrongConsistency)策略,结合CRAQ(ChainReplicationwithApportionedQueries)机制,确保存储操作的一致性,从而简化AI训练与推理的存储管理。在元数据管理上,3FS通过事务性Key-Value存储(如FoundationDB)提供无状态元数据服务,使文件系统能够兼容标准文件接口,无需额外学习新的API,即可无缝集成到现有AI计算框架中。
技术要点:
3FS适用于多种AI训练与推理场景,包括数据预处理、数据加载、模型检查点(Checkpointing)、推理缓存(KVCache)等。它具备高吞吐、高并发的数据访问能力,能够消除数据加载和预取的瓶颈,允许计算节点直接随机访问训练样本。此外,3FS提供高并发的KVCache机制,避免了冗余计算,并在推理任务中提供40+GiB/s的查询吞吐量,极大提升了大模型推理的响应速度。
图6:3FS 读吞吐性能测试:大规模集群压力测试结果
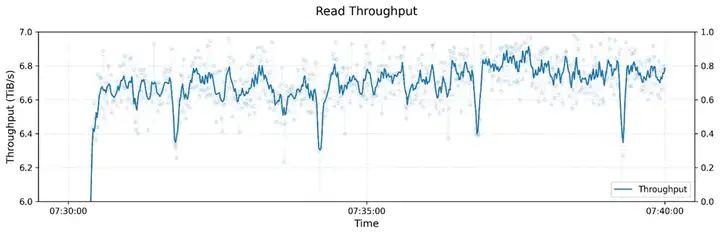
图6展示了3FS(Fire-FlyerFileSystem)在大规模集群下的读吞吐量测试,测试集群包含180个存储节点,每个节点配备16块NVMeSSD和2×200GbpsInfiniBand网卡,由500+客户端节点发起高并发读请求。结果表明,3FS在训练任务的后台流量干扰下,仍能稳定维持6.6TiB/s的总读吞吐量,证明了其在高并发AI训练和推理任务中的卓越性能。
图7,8:3FS 在 GraySort 基准测试中的读写吞吐表现
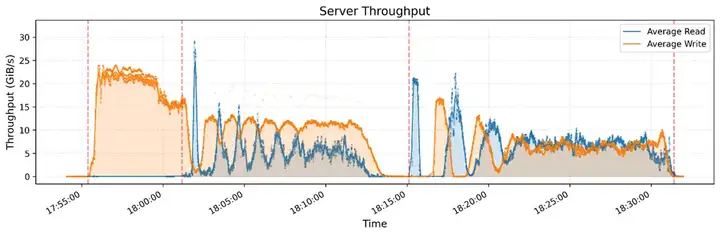
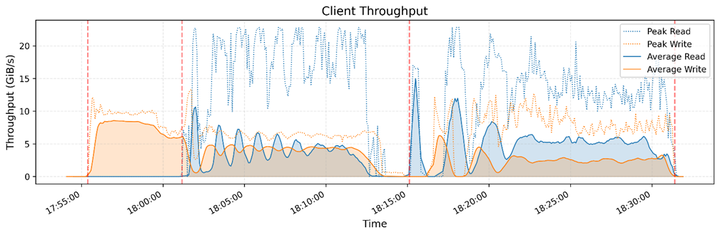
图7,8展示了3FS文件系统在GraySort基准测试过程中的服务器端和客户端的读写吞吐量表现。测试使用25台存储节点和50台计算节点,在30分钟14秒内完成了110.5TiB数据的排序,达到了3.66TiB/min的平均吞吐量。测试采用两阶段排序流程,包括数据分区(shuffle)和分区内排序,并利用3FS进行高效数据读写。
服务器端吞吐分析:
图7反映了3FS服务器端的读写吞吐量随时间的变化。其中,橙色曲线代表写入吞吐量,蓝色曲线代表读取吞吐量。在排序任务开始后,写入吞吐量迅速提升,并在20-25GiB/s范围内稳定,随后逐渐下降,呈现周期性波动。这种变化主要与数据分区和写入模式相关,排序任务在不同阶段的I/O需求不同,导致写入吞吐量出现明显变化。读取吞吐量整体较低,说明在大多数阶段,写入操作占据主要I/O资源。
客户端吞吐分析:
图8展示了客户端的读写吞吐情况,包括平均读写吞吐量(实线)和峰值吞吐量(虚线)。可以看到,读写吞吐量呈现明显的周期性变化,说明计算节点与存储节点之间的数据交互是动态调整的。写入吞吐量在任务初期较高,随后进入稳定阶段,而读取吞吐量则随着不同计算阶段的需求有所波动。从峰值吞吐来看,读写速率可以达到20+GiB/s甚至更高,展现出3FS在高并发I/O任务中的高效数据吞吐能力。
深度解读:为什么3FS重要?
在大规模AI训练和推理场景下,传统存储系统往往面临存储带宽瓶颈、数据一致性问题以及计算节点数据访问效率低下的挑战。3FS通过解耦式架构和RDMA高速网络,打破了存储性能的限制,使AI计算任务可以高效访问分布式存储资源。此外,在推理任务中,KVCache机制能够高效缓存推理过程中的Key-Value数据,避免重复计算,提高推理效率。与传统DRAM缓存相比,3FS提供更大容量和更高吞吐量的存储方案,从而降低大模型推理的存储成本,提升V3/R1训练与推理的整体性能。
概览:
DeepSeek-V3/R1推理系统通过跨节点专家并行(EP)和计算-通信重叠优化,显著提升推理吞吐量和计算效率,每个H800GPU节点每秒可处理73.7k输入token和14.8k输出token。此外,系统采用负载均衡与动态资源调度策略,确保在推理高峰期最大化计算资源利用率,并在低负载时优化成本。在过去24小时内,该推理系统的理论收益达$562,027,成本利润率高达545%,展现了卓越的计算效能与商业价值。
图9: DeepSeek-V3/R1 推理系统架构概览
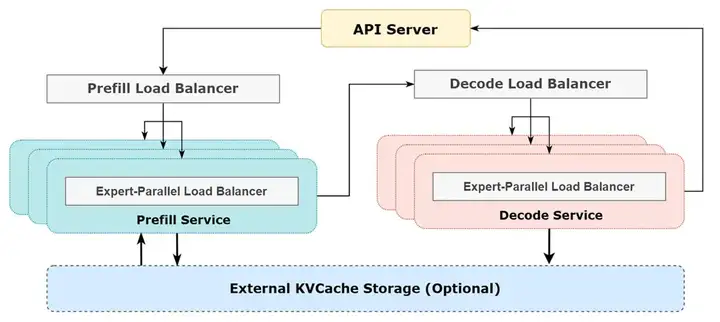
图9展示了DeepSeek-V3/R1推理系统的架构设计,采用预填充(Prefill)和解码(Decode)分离的计算模式,并结合专家并行(ExpertParallelism,EP)和负载均衡(LoadBalancing)来优化推理性能。整个系统由API服务器负责请求管理,分别将推理任务分配给预填充负载均衡器(PrefillLoadBalancer)和解码负载均衡器(DecodeLoadBalancer)。在具体计算过程中,每个阶段的任务会进一步被专家并行负载均衡器(Expert-ParallelLoadBalancer)分配到多个GPU设备,以提升计算效率并减少计算瓶颈。此外,推理过程中还可以选择使用外部KVCache存储,进一步提升缓存命中率和推理吞吐量。这一架构充分利用了分布式计算和负载均衡机制,确保DeepSeek-V3/R1在大规模推理任务中的高效性、低延迟和高吞吐能力。
跨节点专家并行(EP)与计算-通信优化:
DeepSeek-V3/R1采用大规模跨节点专家并行(EP),将不同专家分布在不同GPU之间,优化计算效率并降低内存访问开销。为了隐藏通信开销,系统使用双批次(Dual-Batch)重叠策略,在计算一个微批次的同时执行另一个微批次的通信,实现计算-通信同步执行,从而提高整体吞吐量。此外,系统针对Prefill和Decode两个推理阶段采用不同级别的专家并行和数据并行,进一步优化推理性能。
成本优化与商业收益:
为了降低推理成本,DeepSeek-V3/R1采用动态GPU资源调度策略:在白天高峰期,推理任务占满所有计算节点,而在夜间低负载时,部分节点被重新分配给研究与训练任务。过去24小时(UTC+802/27/202512:00PM-02/28/202512:00PM),DeepSeek推理系统总输入token达6080亿,其中3420亿token(56.3%)命中KVCache,总输出token为1680亿。H800GPU平均吞吐量达73.7ktokens/s(输入)和14.8ktokens/s(输出),保证了极高的推理速度。
图10: DeepSeek-V3/R1 推理服务的 H800 计算节点动态调度
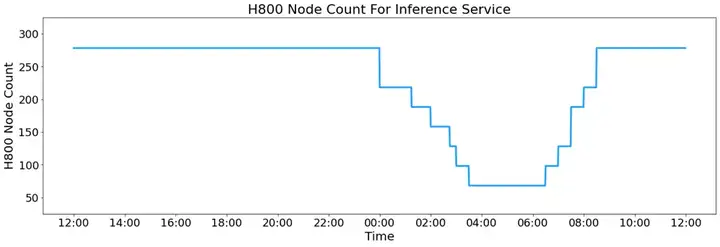
图10展示了DeepSeek-V3/R1推理服务的H800GPU计算节点数量随时间的变化趋势,反映了系统在不同时间段的资源分配策略。白天(12:00-00:00),推理服务维持高计算节点占用,接近300台H800节点,以支持高峰时段的大量用户请求。然而,从午夜开始(00:00之后),系统逐步减少计算资源分配,在凌晨04:00时降至最低,仅保留少量节点用于推理任务,以优化资源利用率和降低计算成本。随后,随着早晨的到来(06:00-12:00),推理节点数量逐步恢复至日间水平,以应对新一轮的计算需求。这种动态扩缩容策略使得DeepSeek能够在保持推理性能的同时优化GPU资源的使用,降低运营成本。
在成本方面,该系统在统计时段内峰值占用278个H800GPU节点(共2224张GPU),平均占用226.75个节点,按每张H800GPU计算成本$2/小时,总日成本约为$87,072。按照DeepSeek-R1计费标准(输入token$0.14/M,缓存未命中$0.55/M,输出token$2.19/M),理论上日收入可达$562,027,成本利润率高达545%。尽管实际收入受DeepSeek-V3价格更低、部分服务免费、夜间折扣等因素影响,但仍展现出强大的商业可行性和盈利潜力。
图11:DeepSeek-V3/R1 推理服务的成本与理论收益分析
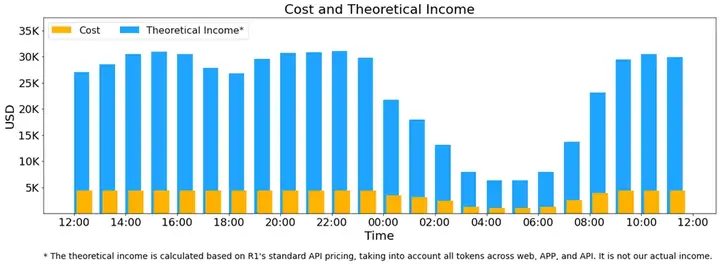
图11展示了DeepSeek-V3/R1推理服务在24小时周期内的运行成本与理论收益,并通过成本优化策略体现了计算资源的动态管理。从图中可以看出,日间(12:00-00:00)推理服务的理论收益(蓝色柱状)维持在较高水平,峰值超过30K美元,而计算成本(黄色柱状)维持在相对稳定的低水平,表明该时段的推理服务具有高利润率。然而,午夜至凌晨(00:00-06:00),随着推理请求减少,收益逐步下降,并在凌晨04:00降至最低,与此同时,计算成本也同步降低,以减少GPU资源的浪费。早晨(06:00-12:00),随着用户活跃度回升,推理服务收益重新上升,并在10:00之后恢复到日间水平。总体来看,该策略通过动态调整GPU资源,在流量高峰期确保计算能力,同时在低谷时减少成本投入,以提高整体运营效率。值得注意的是,该图所示的理论收益是基于R1API价格计算的理论值,并不代表实际收入。
文章来自于“EPIC Connector”,作者“EPIC Connector”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
