# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型刷榜 MMLU、屠榜 GPQA 的玩法一夜变天???
要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。
不过别慌,大模型通用知识推理评测“强化版”来了,堪称大模型评测里的“黄冈密卷”!

近日,字节跳动豆包大模型团队联合 M-A-P 开源社区,推出了全新评测基准 SuperGPQA。
我们翻看论文,细品一番,足足 256 页。据了解,该评测搭建工作耗时半年,近百位学界学者及名校硕博、业界工程师参与标注。

研究团队构建了迄今为止最全面,覆盖 285 个研究生级学科、包含 26529 道专业题目的评估体系。
实验证明,即便最强的 DeepSeek-R1 在 SuperGPQA 上准确率也才 61.82%,在及格线上挣扎,显著低于其在传统评估指标上的表现。
SuperGPQA 精准直击大模型评测的三大痛点:
除此之外,SuperGPQA 也公开了严格的数据构建过程。整个体系依靠大规模人机协作系统,结合专家标注、众包注释和大模型协同验证三重流程,确保入选题目具有足够高的质量和区分度。
目前, SuperGPQA 已在 HuggingFace 和 GitHub 开源,直接冲上了 Trending 榜单。

研究人员透露,现在大语言模型评估体系主要有两大“困境”:学科覆盖严重失衡、评测基准挑战性失效。
以 MMLU 和 GPQA 为代表的传统基准,尽管在数学、物理等主流学科中建立了标准化测试框架,但其覆盖的学科数量通常不足 50 个,无法涵盖人类积累的多样化和长尾知识。
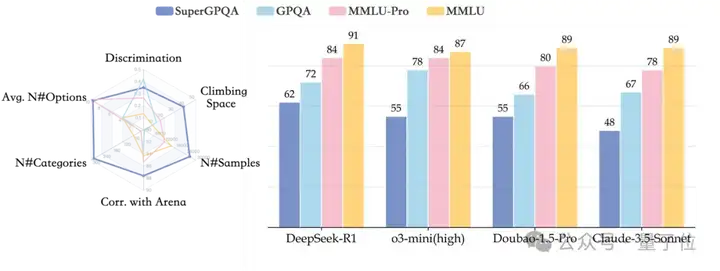
而且,GPT-4o 和 DeepSeek-R1 在传统基准上准确率都破 90% 了,导致评测体系失去区分度,无法有效衡量模型在真实复杂场景中的推理上限。
根源就在于传统基准构建范式太单一,数据来源、质量筛选都相对粗糙。传统基准仅依赖教科书例题或在线题库,例如 GPQA 中 42% 的问题来自维基百科,导致题目缺乏专业深度,且易被模型通过记忆机制“破解”。
数据显示,GPT-4o 对在线练习网站答案的重复率高达 67.3%,暗示其性能提升可能源于题目数据泄露而非真实推理能力。
此外,众包标注的专业水平参差和主观性问题难度评估进一步加剧了基准的不可靠性——早期尝试中,仅 37% 的众包标注问题通过专家审核,导致超过 60% 的标注资源浪费。

为解决上述困境,豆包大模型团队联合 M-A-P 开源社区推出 SuperGPQA,旨在深度挖掘 LLMs 潜力,其特点如下:
作为基准测试,SuperGPQA 非常全面,覆盖 13 个门类、72 个一级学科和 285 个二级学科,共 26,529 个问题,把现有 GPQA(448 题)和 MMLU-Pro(12,032 题)远远甩在身后。同时,每题平均 9.67 个选项,也比传统 4 选项格式挑战性高得多。
SuperGPQA 核心架构分三步:来源筛选、转录、质量检测。
团队设计时,深知众包注释方法在高复杂度题目上的不足,因此引入了专家注释员,确保题目来源靠谱、难度合适。再结合最先进的 LLMs 辅助质量检测,效率拉满,也通过多模型协作降低了题目数据泄漏的风险。
此外,团队还强调严格流程管理和持续质量反馈,保证每阶段输出都达标。靠着系统化、专业化流程,SuperGPQA 题库质量飙升,后期修正成本和时间大幅减少。
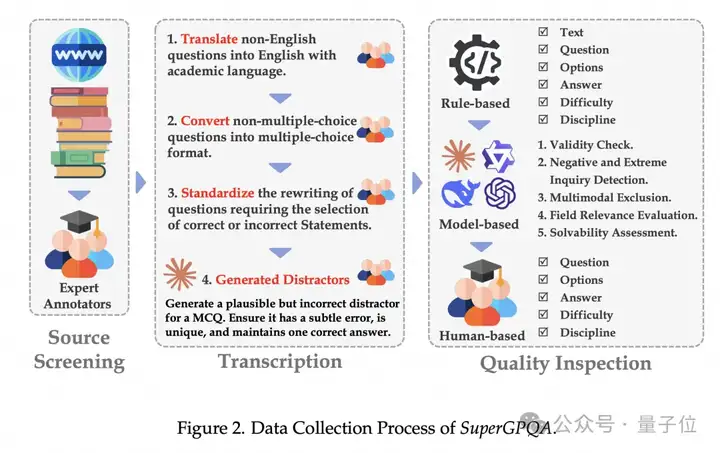
为保证题目高质量,团队直接抛弃众包注释员收集资源的老路,转而让专家注释员从可信来源(教科书、权威练习网站)筛选、收集原始问题。
这招一出,避免了早期大量无效问题的产生,并通过要求提供来源截图,大幅提升了质量检测的效率和准确性。
转录阶段,专家注释员对收集的原始问题进行语言规范化、格式转换,确保所有问题都有统一学术语言和标准多项选择题格式。
团队发现,即使是最先进的语言模型(LLMs)在生成干扰项时也存在漏洞,因此需要专家统一重写,以提高干扰项的准确性和有效性,确保题目的挑战性和区分度。
质量检测阶段采用多层次的检测机制,包括 :
1)基于规则的初步过滤:识别并过滤格式明显不合规范的题目。
2)基于 LLM 的质量检测:多个先进 LLMs(如 GPT-4、Gemini-flash 等)齐上阵,有效性、负面和极端询问检测、多模态排除、领域相关性评估、区分度标记都不在话下。
3)专家复审:专家注释员对可疑题目进行二次审核,确保题库的高可靠性和高区分度。
△LLMs 在不同划分层级上的表现
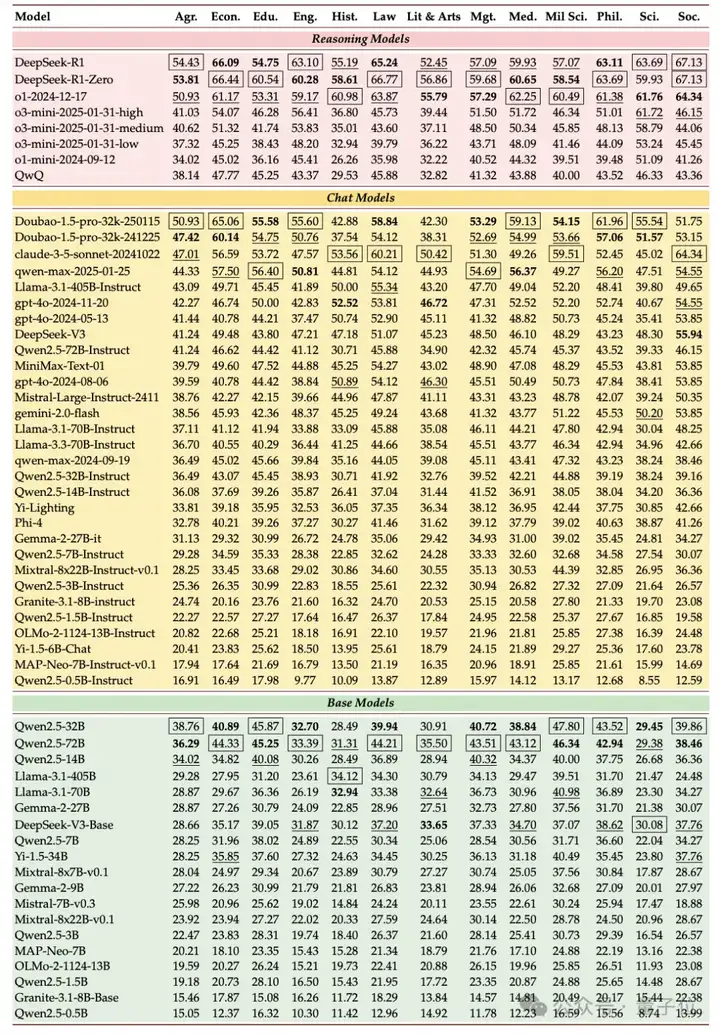
△LLMs 在不同学科上的表现
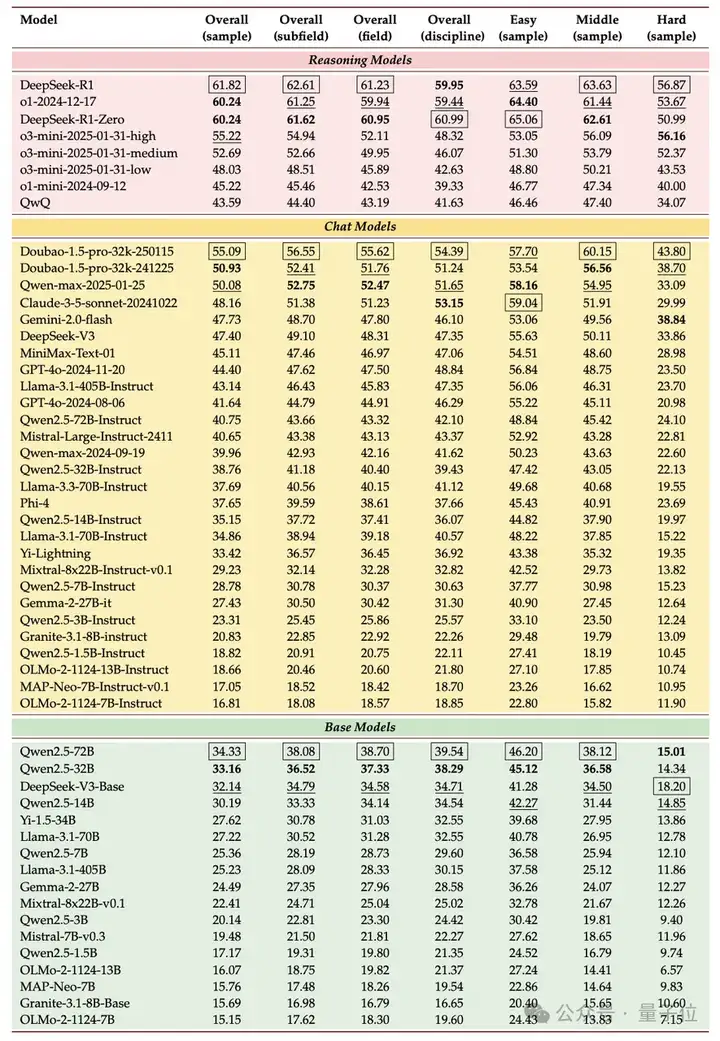
SuperGPQA 还做了全面的实验,来测试业界主流 LLM 的能力表现。评估涵盖 6 个推理模型、28 个聊天模型、17 个基础模型,闭源、开源、完全开源模型全覆盖。
团队发现,在涵盖 51 个模型的横向评测中,DeepSeek-R1 以 61.82% 准确率登顶,但其表现仍显著低于人类研究生水平(平均 85%+)。
我们从论文中还扒到三大值得关注的结论:
1、推理能力决定上限
2、国内模型突围
3、学科表现失衡 * STEM 领域优势显著:在「理论流体力学」「运筹学和控制论」等子领域,Top 模型准确率超 75%
一直以来,评估数据集对提升大模型的效果上限至关重要,甚至有可能是“最关键的部分”。
但评测数据集的搭建耗费大量人力,很大程度依靠开源贡献。早在去年,字节就在开源评测数据集上有所行动,覆盖超 11 类真实场景、16 种编程语言的代码大模型评估基准 Fullstack Bench 受到开发者好评。
此番字节再次亮出耗时半年打造的SuperGPQA,进一步打破外部关于“字节对基础工作投入不足”的印象。另一方面,也侧面暴露字节内部对模型能力的极高目标。

结合近期我们关注到的 DeepMind 大牛吴永辉加入,全员会定下“追求智能上限”的目标。
2025 年,豆包模型究竟能冲到什么水平?不妨让子弹再飞一会。
论文链接: https://arxiv.org/pdf/2502.14739
数据链接: https://huggingface.co/datasets/m-a-p/SuperGPQA
代码链接: https://github.com/SuperGPQA/SuperGPQA
文章来自微信公众号 “ 量子位 ”,作者 允中



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
