
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
来自主题: AI技术研报
9944 点击 2025-11-28 09:28
 搜索
搜索
基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。

AI模型排行榜分两类:以高考式标准化测试衡量特定能力的客观基准测试(如AAII、MMLU-Pro),以及用户匿名盲测、根据偏好对答案投票排名的人类偏好竞技场(如LMArena)。两者各有优劣和局限性,且排行榜本质是门生意。用户应基于实际需求而非榜单名次选择模型,实用性至上。

中国在人工智能领域已经成为全球竞争的重要力量。根据斯坦福 2025 年 AI 指数报告,美国虽然仍领先于顶级模型数量,但中国正在迅速缩小差距 —— 在 MMLU、HumanEval 等基准测试中的差距已从几乎双位数下降到几乎持平。

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。
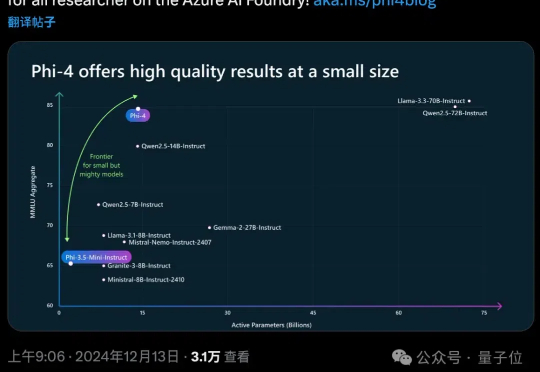
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
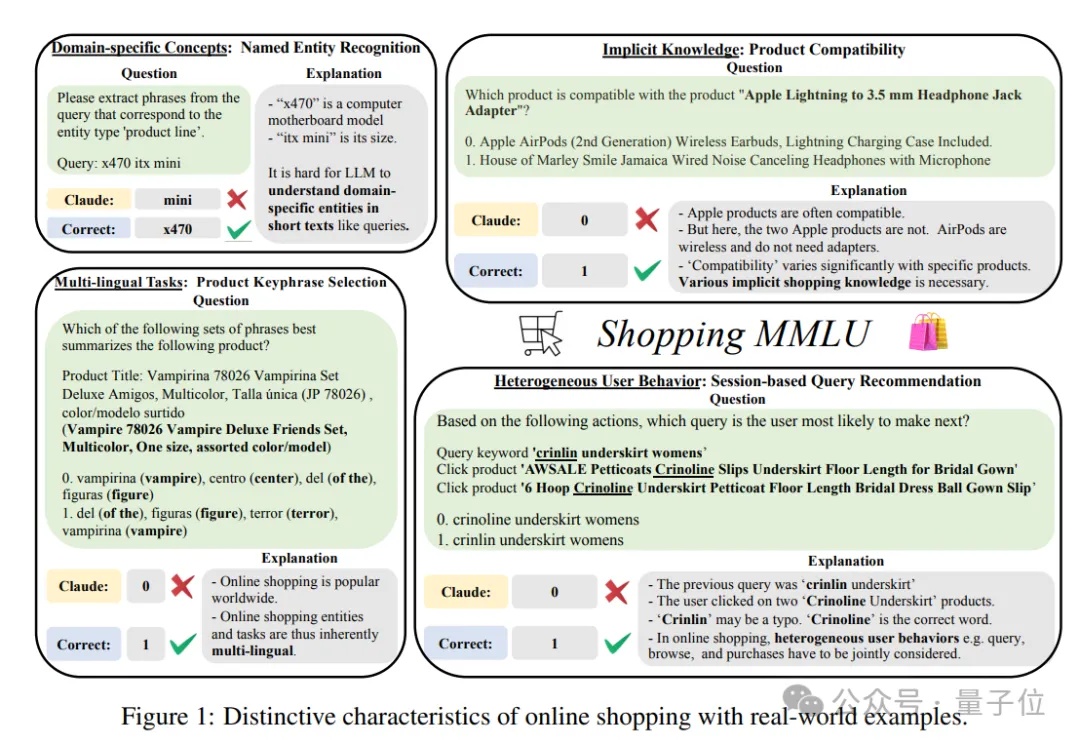
谁是在线购物领域最强大模型?也有评测基准了。
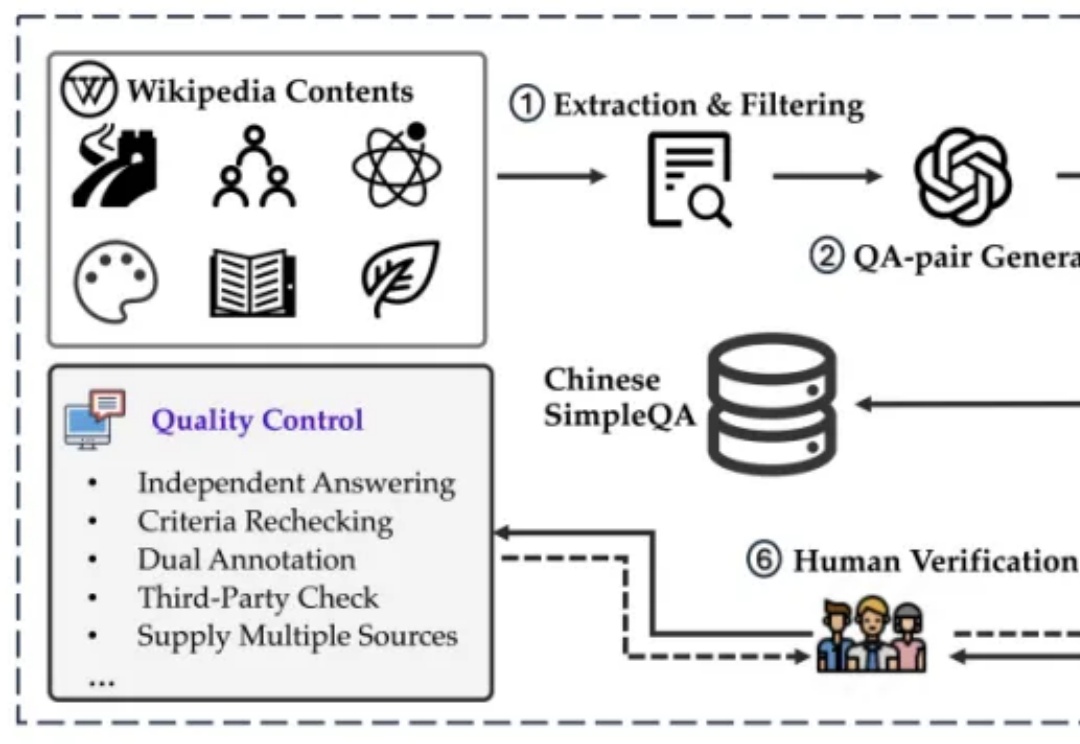
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
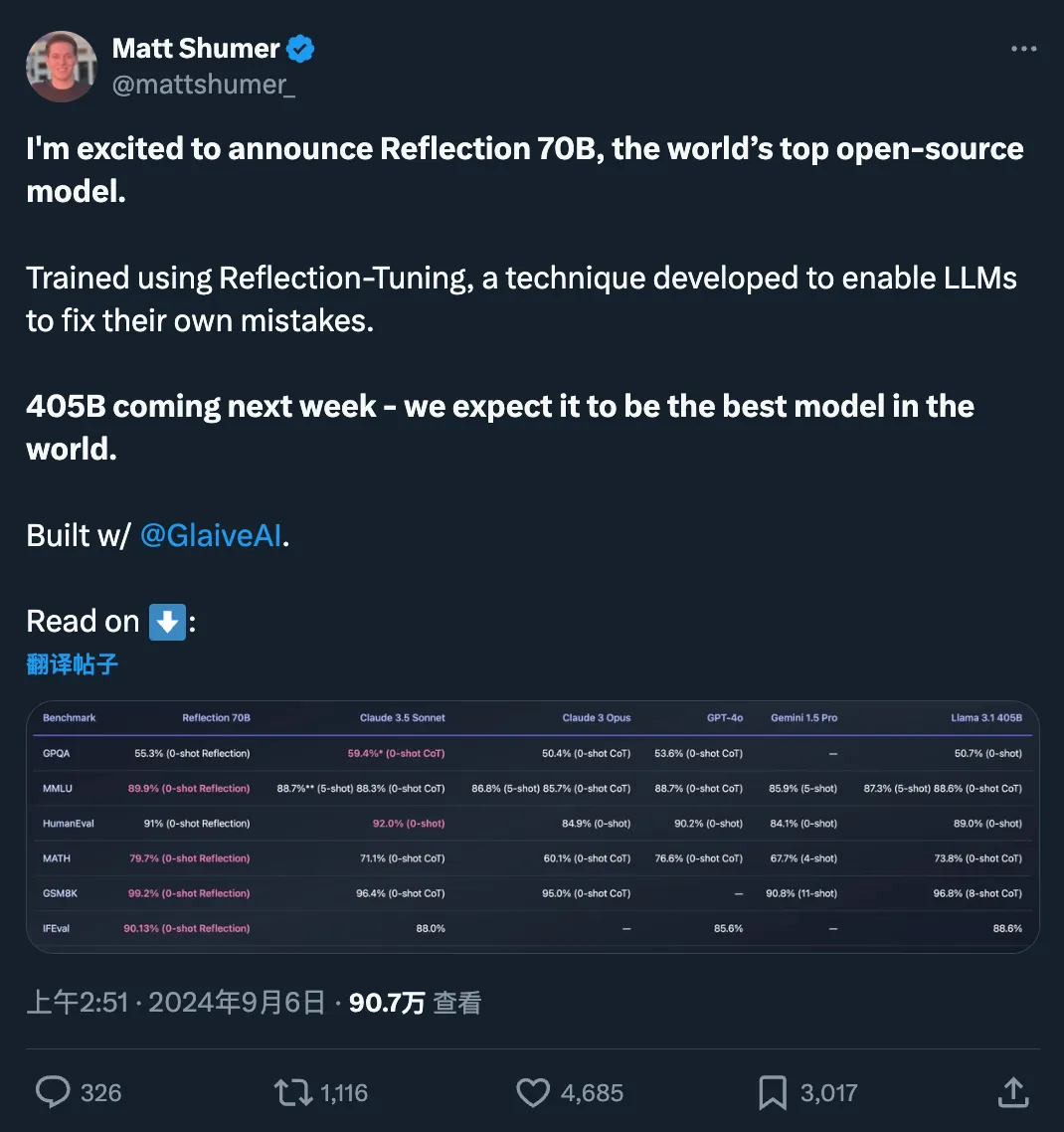
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。

大模型权威测试,翻车了?! HuggingFace都在用的MMLU-PRO,被扒出评测方法更偏向闭源模型,被网友直接在GitHub Issue提出质疑。