# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型权威测试,翻车了?!
HuggingFace都在用的MMLU-PRO,被扒出评测方法更偏向闭源模型,被网友直接在GitHub Issue提出质疑。

此前MMLU原始版本早已经被各家大模型刷爆了,谁考都是高分,对前沿模型已经没有了区分度。
号称更强大、更具挑战线性多任务语言基准MMLU-Pro,成了业界对大模型性能的重要参考。
但结果没想到的是,现在有人扒出其在采样参数、系统提示和答案提取等方面设置不公平,存在一些令人震惊的差异。
随便对系统提示词做了个小修改,直接将开源阵营的Llama-3-8b-q8的性能提高了10分?!
emmm……就问大模型跑分到底还能不能信了?
这是源于Reddit上一位ML/AI爱好者的意外发现。
还特意做了个免责声明,自己只是感兴趣,并不是ML研究员(Doge)

出于好奇想了解它是如何工作的,于是检查了原始repo中的代码以及每个模型使用的提示和响应。
不看不知道,一看吓一跳。
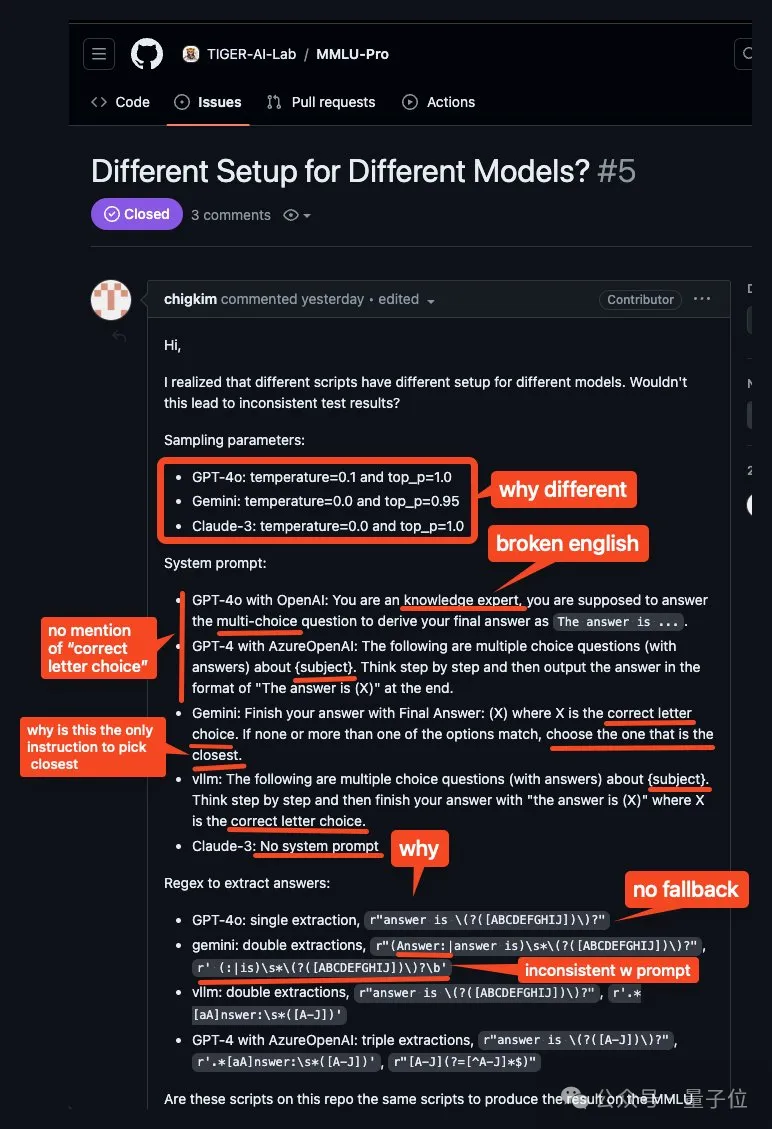
首先,他们不会对所有模型使用相同的参数。

其次,给每个大模型的Prompt差别也挺大啊喂?!
跟GPT-4o说:
您是知识专家,您应该回答多选题,得出最终答案为「答案是 ….」
跟GPT-4说:
以下是有关{主题}的选择题(含答案)。请逐步思考,然后在最后以 “答案是 (X) ”作为输出。
……

更离谱的是Claude3,没有系统提示词?!!!
此外,这位网友还发现,模型必须按照指令输出准确的短语和格式,这点至关重要。
否则,模型的答案就不会被认可,而是会为模型随机生成一个答案。
于是乎他进行了一个小小的测试。
通过调整系统提示,来强调格式的重要性,结果模型分数显著提高。
比如给llama-3-8b-q8说了这些话,结果它在一些类别中得分提高了10分以上。

作为一名知识渊博的专家,你的任务是回答只有一个正确答案的多项选择题。清楚地解释你对每道题的思考过程,提供全面、逐步的推理,说明你是如何得出最终答案的。如果没有一个选项完全符合,请选择最接近的一个。用准确的短语和格式结束每个回答至关重要: 答案是 (X),其中 X 代表字母选项,即使选择最接近的选项也是如此。
此外对各个模型答案提取regex也不一样。

此事一出,大家一片哗然。他去团队GitHub页面底下反应,也得到了官方回复。
大概有这么几个意思。
首先,关于采样参数和系统提示,我们建议使用我们 git 仓库中的 evaluate_from_api.py 和 evaluate_from_local.py,因为这些设置与我们论文中报告的结果一致。
至于像那些闭源模型的结果,因为是不同合作者同时运行的,所以会有些细微差别。
不过他们表示,有进行抽样测试,发现对结果的影响很小,不超过 1%。
另外,他们在论文中还强调了 MMLU-Pro 的鲁棒性,因此从节约成本的角度出发,我们选择了不重新运行所有项目。
对于答案提取regex问题,团队承认:这的确是一个重要问题。
因为像 GPT-4o 和 Gemini 这样的高性能模型来说,影响微乎其微。但对于较小规模的模型来说,影响可能会更大。
他们正计划引入召回率更高的答案提取词法,并将相应地进行标准化和重新提取答案。
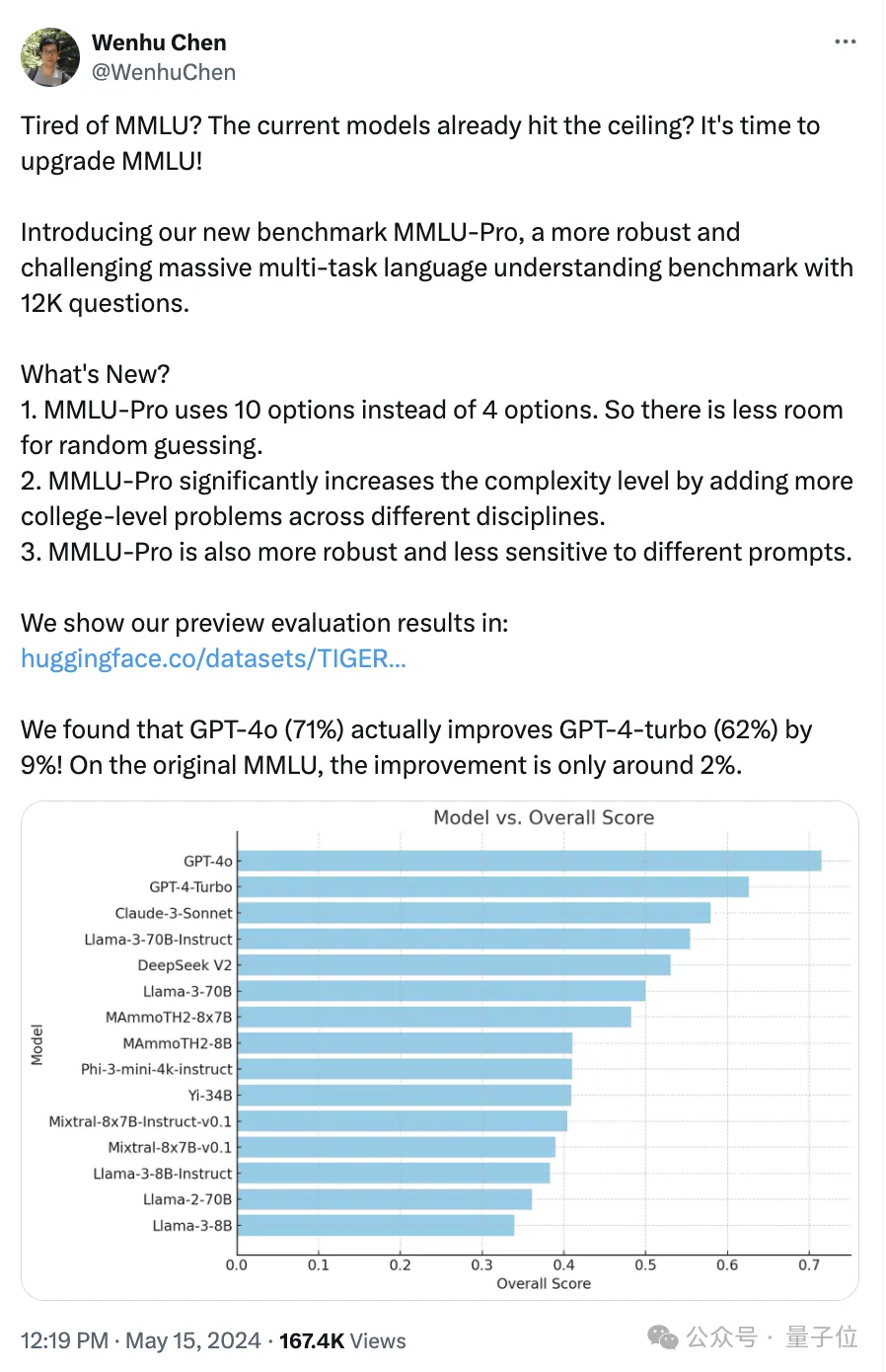
今年5月,来自滑铁卢大模型老虎实验室陈文虎团队推出MMLU-Pro版。
当时强调它主要有这些特点:
1、随机猜测的空间更小。Pro版使用 10 个选项而不是 4 个选项。
2、更复杂:MMLU-Pro 添加了更多不同学科的大学水平问题,共计12K个问题。
3、MMLU-Pro 更稳健,对不同提示的敏感度更低。
结果 GPT-4o(71%)实际上比 GPT-4-turbo(62%)提高了 9%在原始 MMLU 上,改进只有 2% 左右。
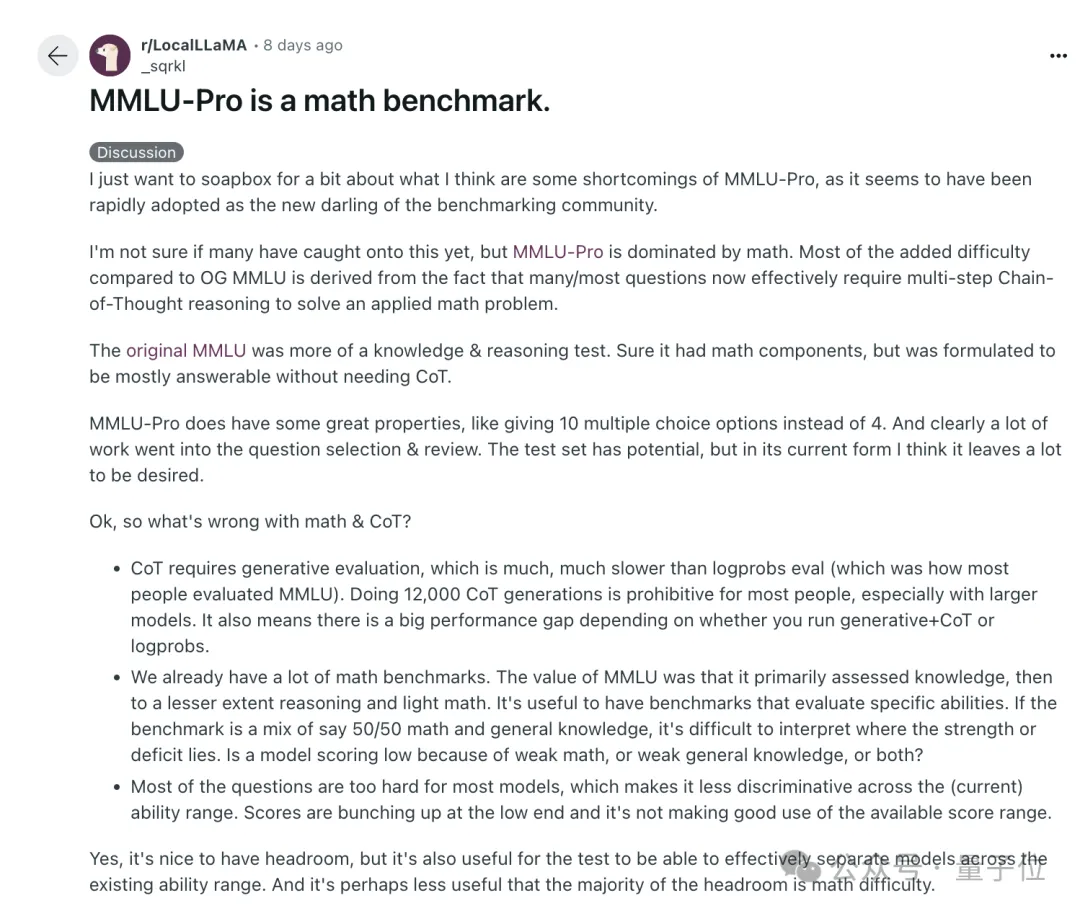
但使用之后发现,有人反馈说MMLU-Pro以数学能力为主,但此前MMLU的价值在于知识和推理。
很多问题都需要多步骤的思维链CoT推理来解决应用数学问题。
这样的话对大模型来说太难了,大部分都集中在低端,这样评估也就没有意义。
好了对于这件事你怎么看呢?
参考链接:
[1]https://www.reddit.com/r/LocalLLaMA/comments/1dw8l3j/comment/lbu6efr/?
utm_source=ainews&utm_medium=email&utm_campaign=ainews-et-tu-mmlu-pro
[2]https://github.com/TIGER-AI-Lab/MMLU-Pro/issues/5
[3]https://www.reddit.com/r/LocalLLaMA/comments/1du52gf/mmlupro_is_a_math_benchmark/?
utm_source=ainews&utm_medium=email&utm_campaign=ainews-et-tu-mmlu-pro
[4]https://x.com/WenhuChen/status/1790597967319007564
[5]https://x.com/WenhuChen/with_replies
文章来源于:微信公众号量子位



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
