# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
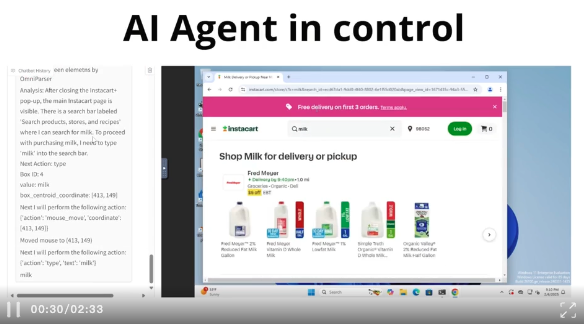
图形用户界面(GUI)自动化需要智能体具备理解和交互用户屏幕的能力。
然而,使用通用大型语言模型(LLM)作为GUI智能体仍然存在难点:1)如何可靠地识别用户界面中的可交互图标,以及 2)理解截图中各种元素的语义,并准确地将预期的操作与屏幕上的相应区域关联起来。
OmniParser通过将UI截图从像素空间「token化」为LLM可解释的结构化元素,弥合了这一差距,使得LLM能够在一组已解析的可交互元素基础上进行基于检索的下一步动作预测。
代码: https://github.com/microsoft/OmniParser/tree/master
模型: https://huggingface.co/microsoft/OmniParser-v2.0
Demo:https://huggingface.co/spaces/microsoft/OmniParser-v2
OmniParser方法概述
可交互区域检测
从UI屏幕中识别可交互区域是推理用户任务应执行何种操作的关键步骤。与其直接让GPT-4o预测屏幕上应操作的xy坐标,研究人员采用Set-of-Marks,在UI截图上叠加可交互图标的边界框,并让GPT-4V生成要操作的边界框ID。
具体而言,研究人员构建了一个独特UI截图的可交互图标检测数据集,每张图片都标注了从DOM tree提取的可交互图标的边界框。
数据采集时,首先从Bing Index热门网址中随机抽取100,000个URL,并从其DOM中提取网页的可交互区域边界框。部分网页及其可交互区域示例如图2所示。
融合功能性icon semantics
研究人员发现,仅输入带有边界框和对应ID的UI截图,往往会导致GPT-4o产生误导性预测,这一局限性可能源于GPT-4o在同时执行两个任务时的能力受限:一是识别每个图标的语义信息,二是预测特定图标的下一步操作。
为了解决这一问题,研究人员在提示(prompt)中加入功能的局部语义信息。
具体而言,对于可交互区域检测模型识别出的每个图标,使用一个微调模型生成该图标的功能描述。
通过构建专门的图标描述数据集,研究人员发现该模型在常见应用图标的描述上更加可靠;在UI截图的视觉提示基础上,加入局部边界框的语义信息(以文本提示的形式)能够显著提升GPT-4o的理解效果。
构建专用数据集
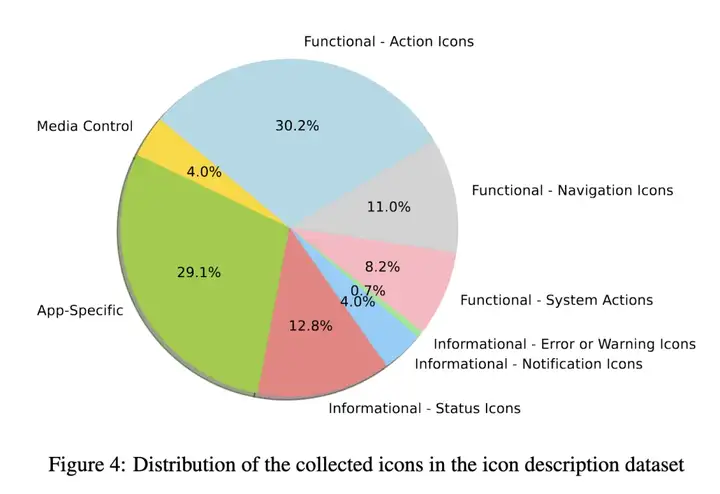
OmniParser的开发始于两个核心数据集的构建:
OmniParser V1实验结果
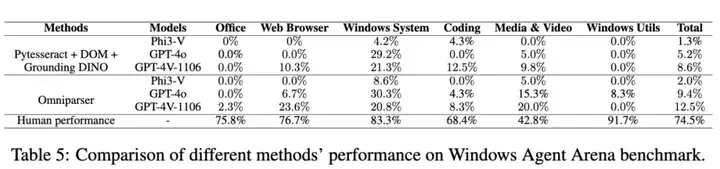
通过这些解析结果,OmniParser显著提升了GPT-4V在多个基准测试(ScreenSpot、Mind2Web、AITW、WindowsAgentArena)上的表现:
Multimodal Mind2Web
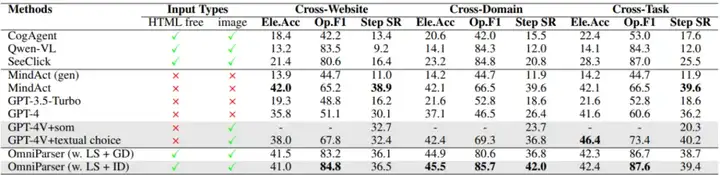
AITW

Windows agent arena
OmniParser V2带来哪些新东西?
OmniParser V2将屏幕理解能力提升到了新的水平。与V1相比,它在检测更小的可交互元素方面达到了更高的准确率,同时推理速度更快,使其成为GUI自动化的有力工具。
具体而言,OmniParser V2采用了更大规模的交互元素检测数据和图标功能描述数据进行训练。
此外,通过减少图标描述模型的图像输入尺寸,OmniParser V2的推理延迟比上一版本降低了60%
值得注意的是,OmniParser与GPT-4o结合后,在最新发布的 ScreenSpot Pro基准测试上达到了39.6%的平均准确率,该基准测试具有高分辨率屏幕和极小的目标图标,相比GPT-4o原始得分0.8有了显著提升。
为了加快不同智能体设置的实验速度,研究人员创建了OmniTool,一个Docker化的Windows系统,集成了一套代理所需的重要工具。
OmniTool开箱即用地支持OmniParser与多种最先进的LLM结合使用,包括OpenAI(4o/o1/o3-mini)、DeepSeek(R1)、Qwen(2.5VL)和Anthropic(Sonnet),从而实现屏幕理解、目标对齐、行动规划和执行等功能。
风险与缓解措施
为了符合「微软AI原则」和「负责任AI实践」,研究人员通过使用负责任AI数据训练图标描述模型来进行风险缓解,有助于模型尽可能避免推测出现在图标图像中的个人的敏感属性(如种族、宗教等)。
同时,研究人员鼓励用户仅在不包含有害内容的截图上使用OmniParser,最好在使用过程中保持人工审核,以尽量降低风险。
针对OmniTool,研究人员使用「微软威胁建模工具」进行威胁模型分析,并在GitHub仓库中提供了沙盒Docker容器、安全指南和示例。
参考资料:
https://www.microsoft.com/en-us/research/articles/omniparser-v2-turning-any-llm-into-a-computer-use-agent/
文章来自微信公众号 “ 新智元 ”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
