# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近 AI 圈最炸的瓜,毫无疑问是——Manus。
前天我们邀请了 OWL 和 OpenManus 团队为大家带来了全网首个 Manus 开源复现直播,直播回放在视频号。
今天为大家带来 Manus 开源复刻框架 OWL 的实测体验及技术拆解。
OWL 项目地址:https://github.com/camel-ai/owl
🦉 OWL 是一个基于 CAMEL-AI 框架(https://github.com/camel-ai/camel)的多智能体协作的尖端框架,它突破了任务自动化的界限,在其官方的介绍中表示:
"我们的愿景是彻底改变 AI 代理协作解决实际任务的方式。通过利用动态代理交互,OWL 可以在不同领域实现更自然、更高效和更强大的任务自动化。"
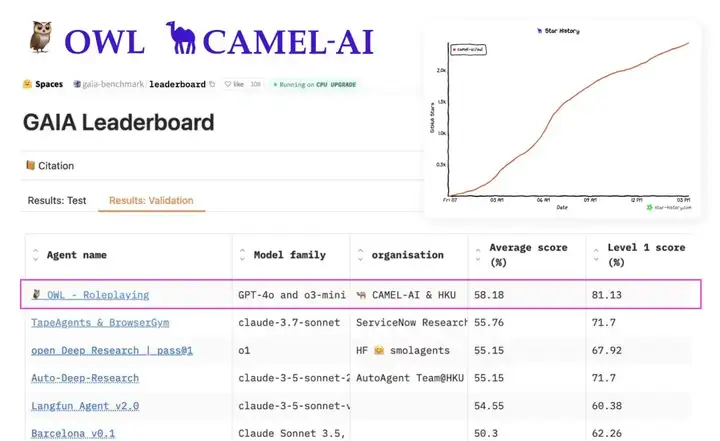
目前 OWL 在 GAIA 基准测试中取得 58.18 平均分,在开源框架中排名第一。
这里是一个演示 demo:
其实如果大家看过 Manus 的演示视频就可以发现,因为一些任务现在的大模型没有办法一次性全都处理完,Manus 在完成我们提出的问题的时候会首先对任务进行任务拆分,之后形成一个 TODO.md 用来记录自己已经完成的进度。
在 OWL 中,也是类似的思想,OWL 整个流程基于 CAMEL 框架中 RolePlaying 方法,RolePlaying 是 CAMEL 框架的独特合作式智能体框架。该框架通过预定义的提示词为不同的智能体创建唯一的初始设置。
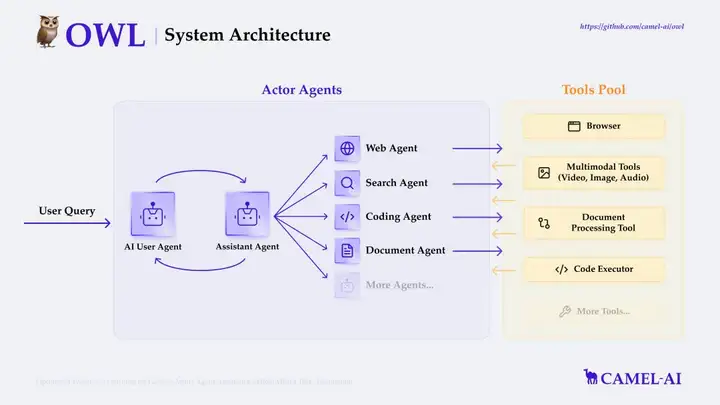
在 RolePlaying 中 User 角色负责将讲任务拆解,并且每次给出一个指令到 Assistant 角色,Assistant 角色负责实施指令,在这个过程中 Assistant 角色可以使用各种我们给它配置好的工具,比如获取实时信息(如天气、新闻)的工具、计算的工具以及在 OWL 中定义的一些特定的工具(包括控制 web 页面的工具、处理文件、表格、图像等工具)。
下面我们先来看一个 case,我的问题是"帮我在小红书上找一些3.8女神节适合送妈妈的礼物":
可以发现在运行过程中,我们的 agent 首先调用了WebToolkit,WebToolkit 实际上是一个封装了智能体的一个工具,其中包括一个planning_agent和一个web_agent。在浏览器模拟交互任务开始时,planning_agent会首先给出一个详细的规划,这个规划之后会被用于指导web_agent选择具体的执行动作。
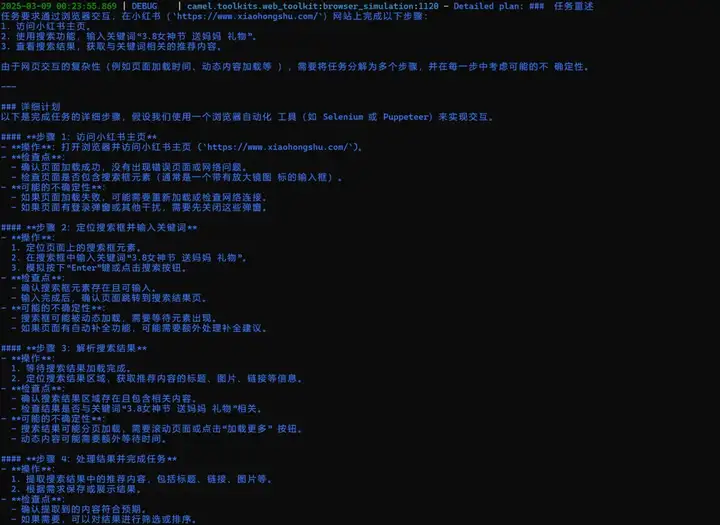
那么我们的 agent 是怎么实现控制我们的浏览器的呢,首先任务明确之后,我们首先会跳转到一个网站,该网站是由start_url来决定的,该参数是可以由用户指定,也可以是 agent 在自我规划中提出的。跳转到网站之后,我们的WebToolkit会将当前的页面截图保存下来,并且给其中的元素都打上标签。
该步骤的实现方法如下:
1. 交互元素通过 JavaScript 脚本获取:
def get_interactive_elements(self) -> List[Dict[str, Any]]:
try:
self.page.evaluate(self.page_script)
except Exception as e:
logger.warning(f"Error evaluating page script: {e}")
result = cast(
Dict[str, Dict[str, Any]], self.page.evaluate("MultimodalWebSurfer.getInteractiveRects();")
)
typed_results: Dict[str, InteractiveRegion] = {}
for k in result:
typed_results[k] = interactiveregion_from_dict(result[k])
return typed_results
2. add_set_of_mark 函数负责在截图上绘制标记:
def _add_set_of_mark(
screenshot: Image.Image, ROIs: Dict[str, InteractiveRegion]
) -> Tuple[Image.Image, List[str], List[str], List[str]]:
# ... 初始化代码 ...
# 为每个交互区域绘制标记
for idx, (identifier, region) in enumerate(ROIs.items()):
for rect in region.rects:
_draw_roi(draw, idx, font, rect)
# ... 其他处理 ...
# ... 返回结果 ...
3. _draw_roi 函数负责实际绘制:
def _draw_roi(
draw: ImageDraw.ImageDraw, idx: int, font: ImageFont.FreeTypeFont | ImageFont.ImageFont, rect: DOMRectangle
) -> None:
# 计算矩形坐标
x, y = rect["x"], rect["y"]
width, height = rect["width"], rect["height"]
# 选择颜色
color = _color(idx)
# 绘制矩形边框
draw.rectangle([(x, y), (x + width, y + height)], outline=color, width=2)
# 绘制标签
label = str(idx)
text_width, text_height = font.getsize(label)
# 确定标签位置
label_x = x + width / 2 - text_width / 2
label_y = max(y - text_height - 2, TOP_NO_LABEL_ZONE)
# 绘制标签背景和文本
draw.rectangle([(label_x - 2, label_y - 2), (label_x + text_width + 2, label_y + text_height + 2)], fill=color)
draw.text((label_x, label_y), label, fill=(255, 255, 255, 255), font=font)
该函数会在元素周围绘制彩色矩形边框,为每个元素分配数字 ID 标签,最后在元素上方绘制带背景的标签,如下图所示。
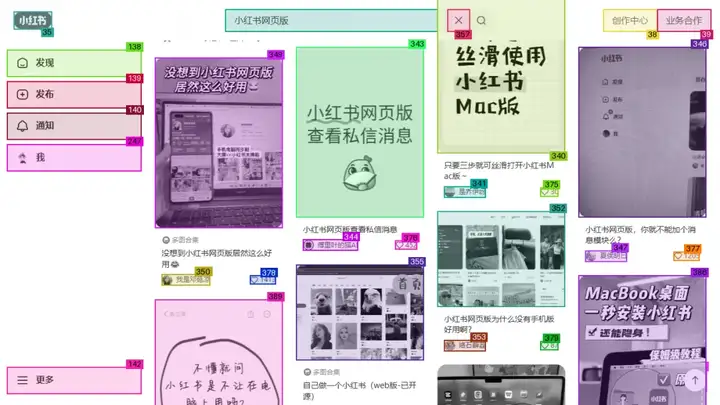
生成的带标签的页面(该页面存储在./tmp目录里)就是我们web_agent将要接收到图片输入啦,之后web_agent会根据图片和指令来进行下一步动作。要了解web_agent的工作逻辑,我们需要先了解一下planning_agent是如何工作的,下面是它的提示词:
planning_system_prompt = """
You are a helpful planning agent that can assist users in planning complex tasks which need multi-step browser interaction.
"""
这里定义了planning_agent的基本角色:一个帮助用户规划复杂任务的代理,专注于需要多步骤浏览器交互的任务。planning_agent在初始规划阶段使用以下提示:
planning_prompt = f"""
<task>{task_prompt}</task>
According to the problem above, if we use browser interaction, what is the general process of the interaction after visiting the webpage `{start_url}`?
Please note that it can be viewed as Partially Observable MDP. Do not over-confident about your plan.
Please first restate the task in detail, and then provide a detailed plan to solve the task.
"""
这个提示要求planning_agent:
在任务执行过程中,planning_agent可能需要根据新情况调整计划:
replanning_prompt = f"""
We are using browser interaction to solve a complex task which needs multi-step actions.
Here are the overall task:
<overall_task>{task_prompt}</overall_task>
In order to solve the task, we made a detailed plan previously. Here is the detailed plan:
<detailed plan>{detailed_plan}</detailed plan>
According to the task above, we have made a series of observations, reasonings, and actions. Here are the latest {self.history_window} trajectory (at most) we have taken:
<history>{self.history[-self.history_window:]}</history>
However, the task is not completed yet. As the task is partially observable, we may need to replan the task based on the current state of the browser if necessary.
Now please carefully examine the current task planning schema, and our history actions, and then judge whether the task needs to be fundamentally replanned. If so, please provide a detailed replanned schema (including the restated overall task).
Your output should be in json format, including the following fields:
- `if_need_replan`: bool, A boolean value indicating whether the task needs to be fundamentally replanned.
- `replanned_schema`: str, The replanned schema for the task, which should not be changed too much compared with the original one. If the task does not need to be replanned, the value should be an empty string.
"""
其中{task_prompt}就是我们提供的原始任务输入:"帮我在小红书上找一些3.8女神节适合送妈妈的礼物"。
{detailed_plan}则是上一次生成的规划内容,{self.history_window}默认为5,也就是说planning_agent会动态地结合最近地一些信息来进行下一步规划。在prompt中要求了planning_agent要使用结构化的输出。
生成的规划内容会传输给web_agent来帮助它完成任务。
接下来,我们可以来看一下web_agent的提示词来进一步了解它的工作逻辑。
system_prompt = """
You are a helpful web agent that can assist users in browsing the web.
Given a high-level task, you can leverage predefined browser tools to help users achieve their goals.
"""
使用一个简洁的系统提示定义了web_agent的基本角色:一个帮助用户浏览网页的代理,能够利用预定义的浏览器工具完成用户目标。
之后如果 agent 认为需要进行操作电脑,就使用我们给它配备的browser_simulation方法,该方法会循环地去观察我们的网页,web_agent在每次观察网页时会收到以下格式的提示:
observe_prompt =f"""
Please act as a web agent to help me complete the following high-level task:<task>{task_prompt}</task>
Now,Ihavemadescreenshot(onlythecurrentviewport,notthefullwebpage)basedonthecurrentbrowserstate,andmarkedinteractiveelementsinthewebpage.
Pleasecarefullyexaminetherequirementsofthetask,andcurrentstateofthebrowser,andprovidethenextappropriateactiontotake.
{detailed_plan_prompt}
Here are the current available browser functions you can use:
{AVAILABLE_ACTIONS_PROMPT}
Herearethelatest {self.history_window} trajectory (at most) you have taken:
<history>
{self.history[-self.history_window:]}
</history>
Youroutputshouldbeinjsonformat,including the following fields:
-`observation`:Thedetailedimagedescriptionaboutthecurrentviewport.Donotover-confidentaboutthecorrectnessofthehistoryactions.Youshouldalwayscheckthecurrentviewporttomakesurethecorrectnessofthenextaction.
-`reasoning`:Thereasoningaboutthenextactionyouwanttotake,andthepossibleobstaclesyoumayencounter,andhowtosolvethem.Donotforgettocheckthehistoryactionstoavoidthesamemistakes.
-`action_code`:Theactioncodeyouwanttotake.Itisonlyonestepactioncode,withoutanyothertexts(suchasannotation)
Here are an example of the output:
```json
{{
"observation": [IMAGE_DESCRIPTION],
"reasoning": [YOUR_REASONING],
"action_code":`fill_input_id([ID], [TEXT])`
}}
Here are some tips for you:
-Never forget the overall question:**{task_prompt}**
-Maybeafteracertainoperation(e.g.click_id),thepagecontenthasnotchanged.Youcancheckwhethertheactionstepissuccessfulbylookingatthe`success`oftheactionstepinthehistory.Ifsuccessful,itmeansthatthepagecontentisindeedthesameaftertheclick.Youneedtotryothermethods.
-Ifusingonewaytosolvetheproblemisnotsuccessful,tryotherways.MakesureyourprovidedIDiscorrect!
-Somecasesareverycomplexandneedtobeachievebyaniterativeprocess.Youcanusethe`back()`functiontogobacktothepreviouspagetotryothermethods.
-Therearemanylinksonthepage,whichmaybeusefulforsolvingtheproblem.Youcanusethe`click_id()`functiontoclickonthelinktoseeifitisuseful.
-AlwayskeepinmindthatyouractionmustbebasedontheIDshowninthecurrentimageorviewport,nottheIDshowninthehistory.
-Donotuse`stop()`lightly.Alwaysremindyourselfthattheimageonlyshowsapartofthefullpage.Ifyoucannotfindtheanswer,trytousefunctionslike`scroll_up()`and`scroll_down()`tocheckthefullcontentofthewebpagebeforedoinganythingelse,becausetheanswerornextkeystepmaybehiddeninthecontentbelow.
-Ifthewebpageneedshumanverification,youmustavoidprocessingit.Pleaseuse`back()`togobacktothepreviouspage,andtryotherways.
-Ifyouhavetriedeverythingandstillcannotresolvetheissue,pleasestopthesimulation,andreportissuesyouhaveencountered.
-Checkthehistoryactionscarefully,detectwhetheryouhaverepeatedlymadethesameactionsornot.
-Whendealingwithwikipediarevisionhistoryrelatedtasks,youneedtothinkaboutthesolutionflexibly.First,adjustthebrowsinghistorydisplayedonasinglepagetothemaximum,andthenmakeuseofthefind_text_on_pagefunction.Thisisextremelyusefulwhichcanquicklylocatethetextyouwanttofindandskipmassiveamountofuselessinformation.
-Flexiblyuseinteractiveelementslikeslidedownselectionbartofilterouttheinformationyouneed.Sometimestheyareextremelyuseful.
```
"""
简单使用 GPT 翻译的结果如下:
observe_prompt = f"""
请充当一个Web代理,帮助我完成以下高级任务:<task>{task_prompt}</task>
现在,我已经基于当前的浏览器状态截取了屏幕截图(仅限当前视口,不是整个网页),并在网页上标记了交互元素。
请仔细检查任务的要求以及当前浏览器的状态,并提供下一个适当的操作步骤。
{detailed_plan_prompt}
以下是你可以使用的当前可用浏览器功能:
{AVAILABLE_ACTIONS_PROMPT}
以下是你最近执行的(最多){self.history_window}条操作记录:
<history>
{self.history[-self.history_window:]}
</history>
你的输出应采用JSON格式,并包含以下字段:
observation:关于当前视口的详细图像描述。不要过于自信地假设历史操作是正确的。你应该始终检查当前视口,以确保下一步操作的正确性。
reasoning:你想要执行的下一步操作的推理,包括可能遇到的障碍以及如何解决这些问题。请检查历史操作,以避免重复错误。
action_code:你想要执行的操作代码,仅限于一个单步操作代码,不应包含任何额外的文本(如注释)。
以下是一个输出示例:
json
复制编辑
{{"observation": [IMAGE_DESCRIPTION],
"reasoning": [YOUR_REASONING],
"action_code": `fill_input_id([ID], [TEXT])`
}}
以下是一些提示:
始终牢记总体任务: {task_prompt}
在执行某些操作(例如click_id)后,页面内容可能没有发生变化。请检查历史记录中该操作的success字段,如果其值为true,则说明点击后的页面内容确实没有变化,你需要尝试其他方法。
如果使用某种方法无法解决问题,请尝试其他方法,并确保提供的ID是正确的!
某些复杂的情况可能需要通过迭代过程来完成。你可以使用back()函数返回上一页,尝试其他方法。
页面上可能有许多链接,这些链接可能有助于解决问题。你可以使用click_id()函数点击链接,以查看其是否有用。
始终记住,你的操作必须基于当前图像或视口中显示的ID,而不是历史记录中显示的ID。
不要轻易使用stop()。请记住,图像只显示了页面的一部分。如果找不到答案,请尝试使用scroll_up()和scroll_down()等功能,以查看网页的完整内容,因为关键步骤可能隐藏在页面下方。
如果网页需要人工验证,请避免处理它。请使用back()返回上一页,并尝试其他方法。
如果尝试了所有方法仍然无法解决问题,请停止模拟,并报告遇到的问题。
仔细检查历史操作,确保自己没有重复执行相同的操作。
在处理维基百科修订历史相关任务时,需要灵活思考解决方案。 首先,将单页显示的浏览历史调整到最大,然后使用find_text_on_page函数。这个功能非常有用,可以快速定位你要查找的文本,并跳过大量无关信息。
灵活使用交互元素,例如下拉选择栏,以筛选出你需要的信息。有时候,它们会非常有帮助。
"""
其中{task_prompt}就是我们提供的原始任务输入:"帮我在小红书上找一些3.8女神节适合送妈妈的礼物",
{detailed_plan_prompt}是由planning_agent生成的,{AVAILABLE_ACTIONS_PROMPT}中定义了web_agent可以使用的方法列表。
WebToolkit中的浏览器控制方法主要通过 Playwright 库来实现,在 owl 中,主要实现了以下方法:
{self.history_window}默认为 5,也就是说web_agent会动态地结合最近它做过的操作来进行下一步。在 prompt 中要求了web_agent要使用结构化的输出。
{{"observation": [IMAGE_DESCRIPTION],
"reasoning": [YOUR_REASONING],
"action_code": `fill_input_id([ID], [TEXT])`
}}
web_agent输出之后,WebToolkit会对输出的内容进行解析,之后则由_act来执行action_code,后续的一系列_act大多使用 Playwright 库来完成。Playwright 是由 Microsoft 开发的开源浏览器自动化工具,具有以下特点:
简单来说,Playwright 提供了完整的键盘和鼠标 API,可以模拟各种用户交互。
在这个 case 中,web_agent首先使用了click_id方法,也就是点击,后面的标记是 130,可以看到web_agent发现了登陆界面阻碍了它进行下一步搜索,所以它首先会去关闭这个窗口,也就是点击 130 号元素。
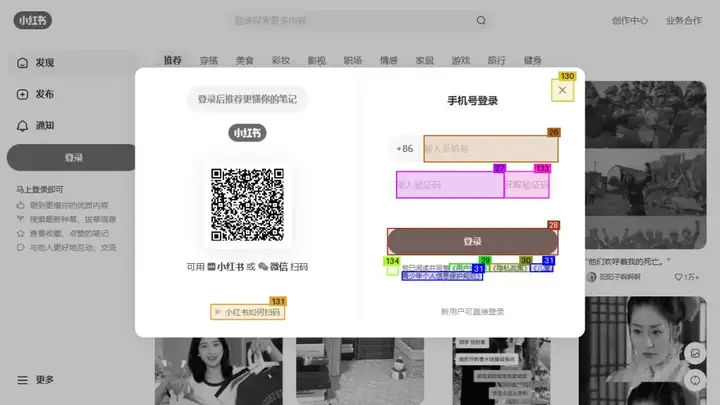

关闭掉阻碍的窗口之后,可以看到WebToolkit又重新对当前页面进行了截图并标注。

我们的web_agent也重新规划了自己的动作,使用了fill_input_id(137, "3.8女神节送妈妈礼物"),它将会在在输入框(例如搜索框)中填入给定的文本并按下回车键来完成搜索功能。

但是最后这个 case 其实执行失败了,眼尖的小伙伴可能发现了,其实 137 号不是搜索框,是搜索键,搜索框是蓝绿背景的,被 137 号盖住了,导致该任务失败。后续 OWL 团队也会优化set of mark方法并结合在命令行中进行 web search +document extractio 这种方式来使整个过程更加 solid。

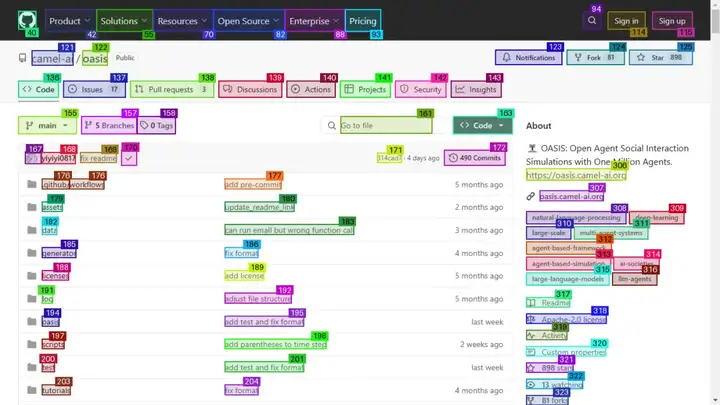
再尝试一个 case"帮我在GIthub找下CMAEL团队开发的OASIS项目,给我介绍下这个项目" 由于整个过程比较长,笔者在这里放一些片段内容:

可以看到 OWL 在自主地去浏览整个网页,这次 OWL 成功地完成了整个任务,并且完成了报告。
左图为过程截图,右图为最终报告:

再来看另一个 case,在这个 case 中我们希望 OWL 给我们制定一个长沙的三天旅游方案:

可以发现这一次,OWL 并没有使用WebToolkit,而是走了另一套流程,它使用了 Google 搜索的 API 来检索到了 6 条内容,然后从中筛选出来了 3 条结果。
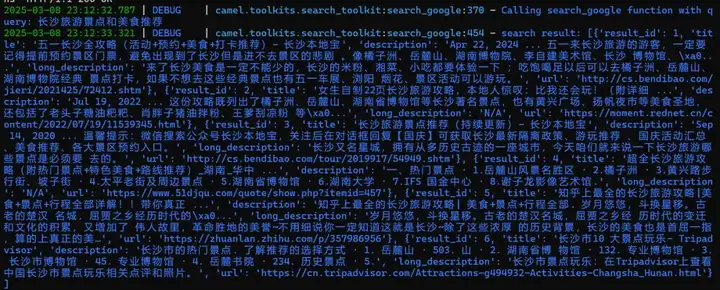
初步检索
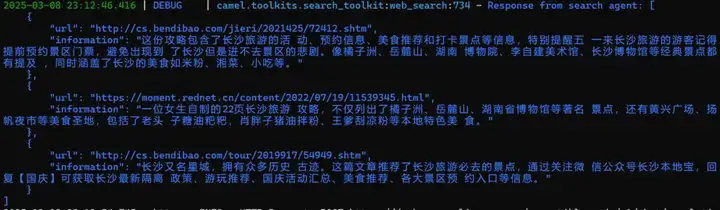
筛选的结果
检索到足够的结果之后,会将这些结果的 url 交给我们的DocumentProcessingToolkit来处理,该工具包集成了Firecrawl 及 Chunkr等处理工具,可以对 url 进行内容解析。

最后再将整个过程的内容总结成我们最后的旅游攻略:
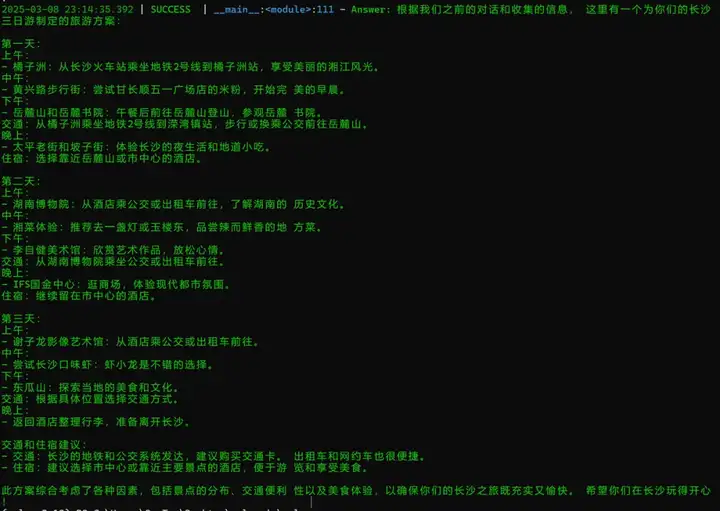
作为在长沙上过学的我来说,这份攻略还是相当实用的~
通过多个案例的实际测试,OWL 展现出令人惊喜的多模态处理能力和智能体协作机制,尤其是它会自主去关闭一些阻碍的页面,这点真的令我感到很兴奋!因为之后再体验 Manus 的时候,在遇到相同的情况 Manus 会直接退出该界面,换另一个方式,哪怕我们在 prompt 要求他必须要在某个网站上进行搜索。
OWL 会根据你的任务自主去决定最快捷的方式来完成。并且整体的流程也给了我们很大的想象空间。比如是不是未来可以代替人类进行一些图片标注任务,可以省去大量人工成本。
对于WebToolkit的实现也非常的巧妙,它实现了两个 Agent 的协作机制:PlanningAgent:负责"战略"层面,提供整体规划,而WebAgent负责"战术"层面,执行具体操作。整体的协作流程也非常像人类由大脑先思考然后下达指令,人体再去执行的过程。

但其实我们可以感受到,有的情况下,直接使用一些 API 来完成任务实际上会比使用WebToolkit速度快很多,但WebToolkit的优势在于能做的事情更加的多(如操作未开放接口的网站),并且对于多模态的支持可能更加丰富。
OWL 另外强大的地方在于对各种工具包的集成与适配做的非常好,包括各种搜索工具、文档处理工具、视频、图像、音频理解工具等等。这使得 OWL 在应对各种情况都显得游刃有余。
说了这么多,小伙伴一定也迫不及待想要一块来体验一下我们的 OWL 吧!下面,笔者将带着大家一起配置好我们需要的环境。
先我们下载与好 owl 的源码并且配置好我们的环境。
git clone https://github.com/camel-ai/owl.git
cd owl
设置虚拟环境
使用 Conda(推荐):
conda create -n owl python=3.11
conda activate owl
使用 venv(备用):
python -m venv owl_env
# Windows 系统
owl_env\Scripts\activate
# Unix 或 MacOS 系统source owl_env/bin/activate
安装依赖:
python -m pip install -r requirements.txt
playwright install
对于模型的设置可以参考笔者的配置,其中模型的选择都使用 Qwen 系列模型,其中需要注意的是WebAgent必须使用多模态模型,因为会接收到图片的输入,关于 API 的申请一并放在下方:
快速体验(只需要配置 QWEN_API_KEY 即可)
from dotenv import load_dotenv
load_dotenv()
from camel.models import ModelFactory
from camel.toolkits import WebToolkit,SearchToolkit,FunctionTool
from camel.types import ModelPlatformType,ModelType
from loguru import logger
from utils import OwlRolePlaying, run_society
import os
qwen_api_key = '你申请到的API'
def construct_society(question: str) -> OwlRolePlaying:
r"""Construct the society based on the question."""
user_role_name = "user"
assistant_role_name = "assistant"
user_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
assistant_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
search_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
planning_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
web_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-vl-plus-latest",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
tools_list = [
*WebToolkit(
headless=False,
web_agent_model=web_model,
planning_agent_model=planning_model,
output_language='中文'
).get_tools(),
]
user_role_name = 'user'
user_agent_kwargs = dict(model=user_model)
assistant_role_name = 'assistant'
assistant_agent_kwargs = dict(model=assistant_model,
tools=tools_list)
task_kwargs = {
'task_prompt': question,
'with_task_specify': False,
'output_language': '中文',
}
society = OwlRolePlaying(
**task_kwargs,
user_role_name=user_role_name,
user_agent_kwargs=user_agent_kwargs,
assistant_role_name=assistant_role_name,
assistant_agent_kwargs=assistant_agent_kwargs,
)
return society
# Example case
question = "在百度热搜上,查看第一条新闻,然后给我一个总结报告"
society = construct_society(question)
answer, chat_history, token_count = run_society(society)
logger.success(f"Answer: {answer}")
完整功能的配置(需要配置更多的 API_KEY)
from dotenv import load_dotenv
load_dotenv()
from camel.models import ModelFactory
from camel.toolkits import (
WebToolkit,
DocumentProcessingToolkit,
VideoAnalysisToolkit,
AudioAnalysisToolkit,
CodeExecutionToolkit,
ImageAnalysisToolkit,
SearchToolkit,
ExcelToolkit,
FunctionTool
)
from camel.types import ModelPlatformType
from camel.configs import QwenConfig
from loguru import logger
from utils import OwlRolePlaying, run_society
import os
qwen_api_key = '你申请到的API'
def construct_society(question: str) -> OwlRolePlaying:
r"""Construct the society based on the question."""
user_role_name = "user"
assistant_role_name = "assistant"
user_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
assistant_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
search_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
planning_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-max",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
web_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-vl-plus-latest",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
multimodal_model = ModelFactory.create(
model_platform=ModelPlatformType.QWEN,
model_type="qwen-vl-plus-latest",
model_config_dict={"temperature": 0},
api_key=qwen_api_key,
)
tools_list = [
*WebToolkit(
headless=False,
web_agent_model=web_model,
planning_agent_model=planning_model
).get_tools(),
*DocumentProcessingToolkit().get_tools(),
*VideoAnalysisToolkit(model=multimodal_model).get_tools(), # This requires multimodal model
*AudioAnalysisToolkit().get_tools(), # This requires OpenAI Key
*CodeExecutionToolkit().get_tools(),
*ImageAnalysisToolkit(model=multimodal_model).get_tools(), # This requires multimodal model
*SearchToolkit(model=search_model).get_tools(),
#FunctionTool(SearchToolkit(model=search_model).search_duckduckgo),如果没有Google相关api可以用duckduckgo代替
*ExcelToolkit().get_tools()
]
user_role_name = 'user'
user_agent_kwargs = dict(model=user_model)
assistant_role_name = 'assistant'
assistant_agent_kwargs = dict(model=assistant_model,
tools=tools_list)
task_kwargs = {
'task_prompt': question,
'with_task_specify': False,
'output_language': '中文',
}
society = OwlRolePlaying(
**task_kwargs,
user_role_name=user_role_name,
user_agent_kwargs=user_agent_kwargs,
assistant_role_name=assistant_role_name,
assistant_agent_kwargs=assistant_agent_kwargs,
)
return society
# Example case
question = "在百度热搜上,查看第一条新闻,然后给我一个总结报告"
society = construct_society(question)
answer, chat_history, token_count = run_society(society)
logger.success(f"Answer: {answer}")
其中使用到的 API 在以下网站可以申请到 QWEN_API_KEY:
🔗:https://help.aliyun.com/zh/model-studio/new-free-quota
使用 API 调用大模型需要 API 密钥,这里我们以 Qwen 为例,您可以从百炼平台获取 API_KEY
在阿里云百炼的模型库(https://bailian.console.aliyun.com/model-market#/model-market)中选择推理 API-Inference ,里面的模型都可以选择。
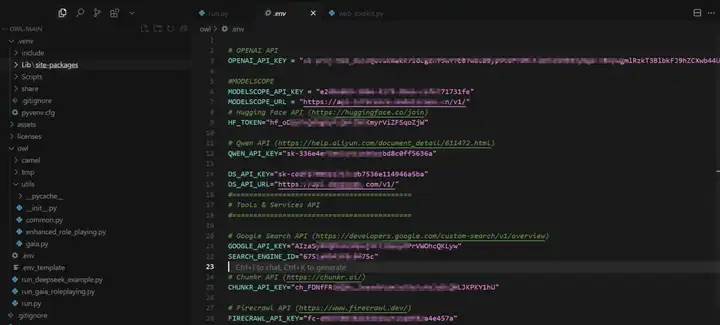
之后在./owl目录下新建一个.env文件,可以参考.env_template(https://github.com/camel-ai/owl/blob/main/owl/.env_template),在里面配置好相关的 KEY,如果只想快速体验我们的第一个案例,则只需要配置QWEN_API_KEY,如果想体验相对完整的功能,需要配置QWEN_API_KEY、CHUNKR_API_KEY、FIRECRAWL_API_KEY、GOOGLE_API_KEY、SEARCH_ENGINE_ID(如果没有GOOGLE相关 API 可以使用 duckduckgo来代替,参考上文的快速体验)。
一切都配置好之后我们就可以运行啦:
python run.py
Datawhale 多智能体教程、CAMEL、OWL 开源地址:
文章来自于“Datawhale”,作者“孙韬”。




【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
