# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚填完坑就又埋下“惊喜预告”??
预告多日之后,稚晖君正式官宣首个通用具身基座模型——智元启元大模型(Genie Operator-1,以下简称GO-1),将具身智能迈向通用全能的门槛进一步降低了。
而且剧透明天还有惊喜。
话不多说,我们直接看今天发布的东西:

概括而言,此次发布的GO-1大模型主要有以下几个特点:
网友们也纷纷表示,通用机器人指日可待了!


具体来看,GO-1大模型由智元机器人联合上海AI Lab共同发布。
通过大规模、多样化的数据训练,GO-1展现出强大的通用性和智能化能力,突破了大量以往具身智能面临的瓶颈。
按照官方说法,GO-1除了拓展机器人的运动能力,更重要的是加强了其AI能力,从而大大增加了机器人的实用价值。
首先,通过学习人类操作视频,机器人能快速学习新技能了。
比如下面这个倒水的动作:

而且机器人还具备了一定的物体跟踪能力,即使随意移动水杯位置,它也能精准倒水。

与此同时,机器人不止掌握已经学过的操作,还能识别并操作未见过的物品(仅通过百条级数据就能实现快速泛化)。
比如倒完水之后,再烤烤面包并抹上果酱:

另外,当前的具身模型通常针对单一机器人本体(Hardware Embodiment)进行设计,这导致两个问题:
而用上GO-1大模型之后,这些问题都被解决了。

可以看到,多个相同/不同本体的机器人能够共同协作完成复杂任务。

此外,GO-1大模型还支持数据飞轮持续提升。即在实际操作过程中不断回流数据尤其是执行出现问题的数据,持续驱动优化模型性能。
比如下面这个例子中,机器人放咖啡杯时出现失误,就可以通过数据回流(加上人工审核)针对性优化。

对了,GO-1大模型也为机器人增加了新的语音交互方式,这极大便利了用户在现实场景中自由表达需求。

事实上,GO-1大模型的构建核心围绕对数据的充分利用展开。
基于具身领域的数字金字塔,GO-1大模型吸纳了人类世界多种维度和类型的数据:
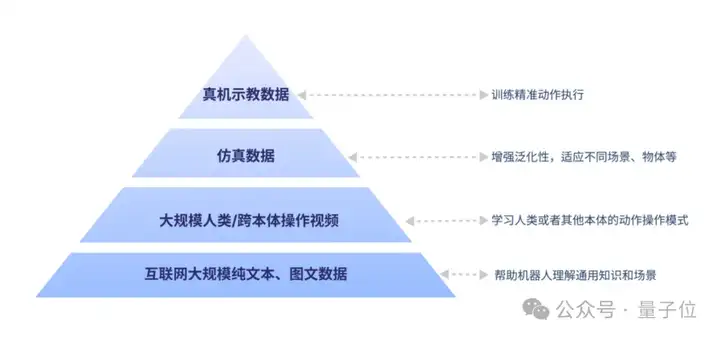
有了这些数据,可以让机器人在一开始就拥有通用的场景感知和语言能力,通用的动作理解能力,以及精细的动作执行力。
当然,过程中也少不了一个合适的数据处理架构。
由于现有的VLA(Vision-Language-Action)架构没有利用到数字金字塔中大规模人类/跨本体操作视频数据,缺少了一个重要的数据来源,导致迭代的成本更高,进化的速度更慢。
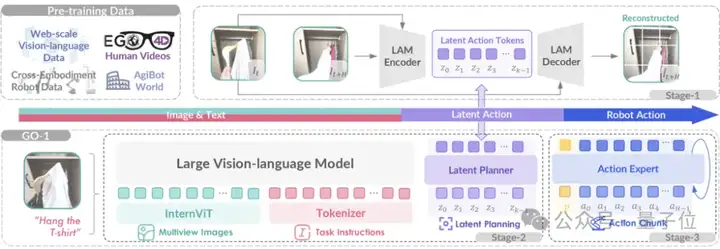
因此,智元团队创新性地提出了ViLLA(Vision-Language-Latent-Action)架构。
与VLA架构相比,ViLLA通过预测Latent Action Tokens(隐式动作标记),弥合图像-文本输入与机器人执行动作之间的鸿沟。它能有效利用高质量的AgiBot World数据集以及互联网大规模异构视频数据,增强策略的泛化能力。
展开来说,ViLLA架构是由VLM(多模态大模型)+MoE(混合专家)组成。
其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力。
推理时,VLM、Latent Planner和Action Expert三者协同工作:
举个例子,假如用户给出机器人指令“挂衣服”,模型就可以根据看到的画面,理解这句话对应的任务要求。然后模型根据之前训练时看过的挂衣服数据,设想这个过程应该包括哪些操作步骤,最后执行这一连串的步骤,完成整个任务的操作。
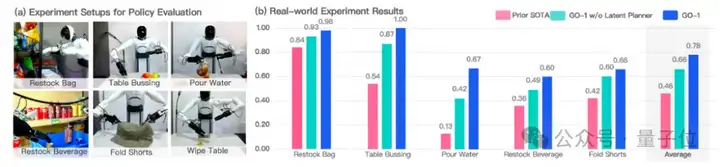
与此同时,通过ViLLA架构,智元团队在五种不同复杂度任务上测试GO-1。
结果显示,相比已有的最优模型,GO-1成功率大幅领先,平均成功率提高了32%(46%->78%)。其中 “Pour Water”(倒水)、“Table Bussing”(清理桌面) 和 “Restock Beverage”(补充饮料) 任务表现尤为突出。
此外团队还单独验证了ViLLA 架构中Latent Planner的作用,可以看到增加Latent Planner可以提升12%的成功率(66%->78%)。
GO-1发布视频的最后,相信大家也看到了一个彩蛋:

不知道内容是否和稚晖君的最新预告有关,明天我们继续蹲蹲~
论文:
https://agibot-world.com/blog/agibot_go1.pdf
文章来自于“量子位”,作者“一水”。




