# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种!
眼睛一闭一睁,阿里通义实验室薄列峰团队又开卷了,哦是开源,R1-Omni来了。
同样在杭州,这是在搞什么「开源双feng」(狗头保命)?
他们都做了啥?
DeepSeek-R1带火了RLVR(可验证奖励强化学习),之前已有团队将RLVR应用于图像-文本多模态LLM,证明其在几何推理和视觉计数等任务上表现优异。
然鹅,尚未探索将其与包含音频、动态视觉内容的全模态LLM结合。
薄列峰团队首次将RLVR与全模态LLM结合,聚焦的是视觉和音频模态都提供关键作用的情感识别任务。
团队实验发现,模型在三个关键方面有显著提升:
RLVR的引入不仅提高了模型在分布内数据上的整体性能,而且在分布外数据集上也展现出了更强的鲁棒性。
更重要的是,提升后的推理能力使得能够清晰分析在情感识别过程中不同模态所起的作用。

R1-Omni在X上也吸引了不少网友关注:
非常有趣的论文,我立刻就能预见到它在市场营销和广告领域进行情感倾向分析的潜力。

还有网友表示可解释性+多模态学习就是下一代AI的方向。
一起具体来看R1-Omni。

在研究方法上,论文首先介绍了DeepSeek同款RLVR和GRPO。
RLVR是一种新的训练范式,其核心思想是利用验证函数直接评估输出,无需像传统的人类反馈强化学习(RLHF)那样依赖根据人类偏好训练的单独奖励模型。
给定输入问题q,策略模型πθ生成响应o,接着使用可验证奖励函数R(q,o)对其进行评估,其优化目标为最大化验证奖励减去基于KL散度正则化项的结果。

RLVR在简化了奖励机制的同时,确保了其与任务内在的正确性标准保持一致。
GRPO是一种全新的强化学习方法,它与PPO等传统方法有所不同,PPO依赖于一个评论家模型来评估候选策略的性能,而GRPO直接比较生成的响应组,避免了使用额外的评论家模型,简化了训练过程。
利用归一化评分机制,GRPO鼓励模型在组内优先选择奖励值更高的响应,增强了模型有效区分高质量和低质量输出的能力。

遵循DeepSeek-R1中提出的方法,团队将GRPO与RLVR相结合。
R1-Omni模型构建方面,团队采用了一种受DeepSeek-R1训练方法启发的冷启动策略。
在包含232个可解释多模态(视觉和音频)情感推理数据集(EMER)样本和348个手动标注的HumanOmni数据集样本的组合数据集上对HumanOmni-0.5B(一个专为人为场景理解设计的开源全模态模型)进行微调,使模型具备初步推理能力,了解视觉和音频线索是如何对情感识别产生作用的。
之后,通过RLVR训练优化模型,奖励函数由准确率奖励和格式奖励组成,准确性奖励评估预测情感与真实情感的匹配度,格式奖励确保模型输出符合指定的HTML标签格式。
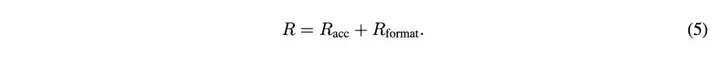

模型输出预期包含两部分:一个推理过程,封装在"<think></think>"标签内,解释模型如何整合视觉和音频线索得出预测;一个最终情感标签,封装在"<answer></answer>"标签内,表示预测的情感。
实验评估中,研究者将R1-Omni与三个基线模型进行比较:原始的HumanOmni-0.5B、在EMER数据集上进行监督微调的模型EMER-SFT、直接在MAFW和DFEW训练集上基于HumanOmni-0.5B进行监督微调的模型MAFW-DFEW-SFT。
评估指标包括无加权平均召回率(UAR)和加权平均召回率(WAR),这些指标衡量模型在不同情感类别中准确分类情感的能力。
重要的是,所有评估都在开放词汇情感测试(OV-emotion)协议下进行。在这种设置中,模型不提供预定义的情感类别,而是直接从输入数据中生成情感标签,这增加了评估的挑战性和实际应用价值。
实验结果表明,R1-Omni在三个关键方面优于三个对比模型:推理能力增强、理解能力提高、泛化能力更强。
研究者展示了一系列可视化示例,比较R1-Omni与其它三个模型的输出,R1-Omni提供了更连贯、准确和可解释的推理过程。
相比之下原始HumanOmni-0.5B和MAFW-DFEW-SFT模型表现出有限的推理能力,而EMER-SFT虽具备一定推理能力但推理过程连贯性较差且容易产生幻觉。

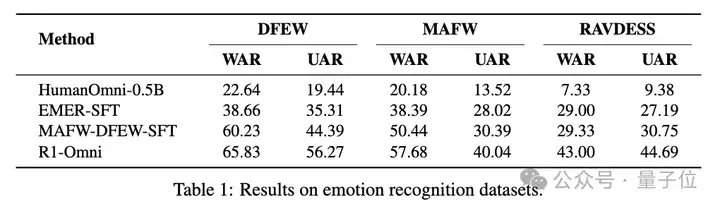
在MAFW和DFEW数据集上,R1-Omni在UAR和WAR指标上均优于其它模型。
例如在DFEW数据集上,R1-Omni实现了65.83%的UAR和56.27%的WAR,明显优于MAFW-DFEW-SFT的60.23%UAR和44.39%WAR。
为了评估模型的泛化能力,研究者在RAVDESS数据集上进行了实验,该数据集作为分布外(OOD)测试集。
与主要由电影片段组成的MAFW和DFEW数据集不同,RAVDESS数据集特点是专业演员以中性北美口音发表词汇匹配的陈述,这种数据分布的显著差异使RAVDESS成为评估模型泛化到未见场景能力的理想基准。
R1-Omni在RAVDESS数据集上相较于MAFW-DFEW-SFT模型有显著提升,实现了43.00%的UAR和44.69%的 WAR。
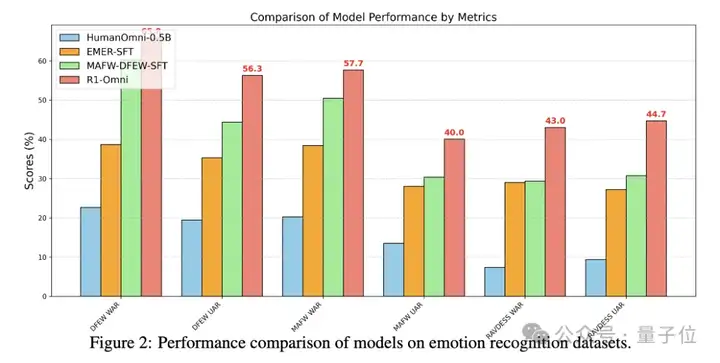
目前,基础模型HumanOmni-0.5B、冷启动模型EMER-SFT,还有MAFW-DFEW-SFT以及最终模型R1-Omni已全部开源。

参考链接:
[1]https://arxiv.org/abs/2503.05379
[2]https://github.com/HumanMLLM/R1-Omni
文章来自于“量子位”,作者“西风”。




【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
