# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在32道高等数学测试中,LLM表现出色,平均能得分90.4(按百分制计算)。GPT-4o和Mistral AI更是几乎没错!向量计算、几何分析、积分计算、优化问题等,高等AI模型轻松拿捏。研究发现,再提示(Re-Prompting)对提升准确率至关重要。
朋友会离开你,兄弟会背叛你。
但数学不会,数学不会就是不会。
相信学不好高等数学的人,对上面这个梗深有感悟。
数学不会好像是真不会:出口成章也好,身体素质惊人也好,面对微积分,能有什么招?
那大语言模型(LLMs)是不是也是一个偏科生呢?
最新研究用32道测试题,总计320分,涵盖4大主题:向量计算、几何分析、积分计算、优化问题,评估了AI模型在高等数学的表现。
总体而言,结果表明LLM高等数学不错,平均得分为90.4(按百分制计算):
-ChatGPT 4o和Mistral AI在不同类型的数学问题上表现稳定,准确率较高,展现出较强的数学推理能力和可靠性。
-Gemini Advanced(1.5 Pro)和Meta AI在某些积分和优化问题上表现较弱,显示出需要针对性优化的领域。
其中, ChatGPT 4o和Mistral AI表现优异,并列第一:

有7款AI模型参与了测试:ChatGPT 4o、Gemini Advanced(1.5 Pro)、Copilot Pro、Claude 3.5 Sonnet、Meta AI、Mistral AI、Perplexity。
此外,研究发现再提示(Re-Prompting)对提升准确率至关重要。
某些情况下,模型首次回答错误,但在重新提示后能够修正答案,这表明改进交互方式可提升模型解题效果。
新研究对教育工作者、研究人员和开发者在数学教育与实践应用中的LLM选择具有重要参考价值,同时也为LLM技术的进一步优化和发展提供了关键的灵感。

论文链接:https://arxiv.org/abs/2503.03960
微积分以其复杂的概念和严谨的解题方法,是测试LLM能力极限的理想领域。
解决微积分问题不仅需要计算的准确性,还要求模型具备深厚的数学原理理解能力、逻辑推理能力,以及将理论概念应用于实际问题的能力。

新研究所选问题涵盖微积分的多个重要主题,包括向量分析、几何解释、积分计算和优化问题。
通过评估这些模型在解题过程中的表现,希望识别它们的优势、劣势和可改进之处,从而推动更强大、更可靠的LLM技术的发展。
随着教育机构和工业界越来越多地探索AI技术的应用,深入了解LLM在处理复杂数学问题方面的能力和局限性变得至关重要。
新研究的分析结果对多个群体具有重要价值,包括开发AI辅助学习工具的教育工作者、致力于提升LLM能力的研究人员,以及希望在实际应用中部署这些技术的从业者。
此外,本研究还回应了对AI模型在专业领域进行系统评估的日益增长的需求。
通过精心设计的一组测试题和详细的评分体系,本研究为评估LLM在数学问题求解方面的表现提供了一种方法论框架。
此外,本研究还引入了重新提示(re-prompting)机制,并对错误模式进行了深入分析,以探讨模型的学习能力以及提高其准确性和可靠性的潜在策略。这些研究结果有助于更全面地理解LLM在数学推理中的优势和局限性,并为未来的优化提供有价值的参考。
大型语言模型(LLMs)在架构和训练方法上,大多集中在语言处理任务上,但也各具特色:
ChatGPT 4o以其先进的自然语言理解和生成能力而闻名;
Gemini Advanced with 1.5 Pro旨在处理高性能语言任务;
Copilot Pro专注于编程和数学问题求解;
Claude 3.5 Sonnet强调准确且具上下文意识的文本生成;
Meta AI旨在提供多功能的语言理解和生成;
Mistral AI以其高效且精准的语言处理能力著称;
Perplexity则专为复杂问题求解和推理任务设计。
现在就关心一个问题:这些模型高等数学到底会不会?

这次评估共涉及32道测试题,总分320分。
如果模型在首次尝试中给出正确答案,则得10分;如果在第二次尝试中找到正确答案,则得5分。
测试题涵盖多个微积分主题,包括:向量计算与几何解释、积分计算及其应用、优化问题与约束优化、微分方程及其应用以及高级微积分概念(如格林定理、曲线积分等)。
模型的评估主要基于两个核心标准:
为了进一步测试模型的错误修正能力,本研究引入了重新提示(re-prompting)机制。
如果模型首次解答错误,则会再次提示它解决该问题,并对修正后的答案进行评估。该机制有助于更全面地分析模型的问题解决能力及其从错误中学习和修正答案的能力。
总体来看,所有LLM的平均得分为90.4(按百分制计算),显示出较强的整体表现。其中ChatGPT 4o和Mistral AI得分310,并列第一,具体结果如下:
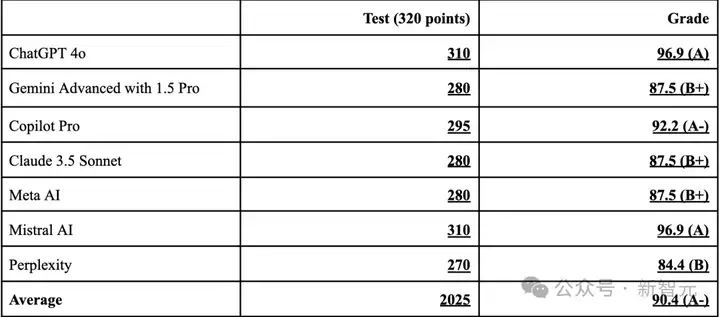
ChatGPT 4o和Mistral AI等模型展现出了较高的准确性和精确度,而其他模型在某些类型的问题上表现较为吃力。
比如,在关于向量分解的问题上,所有模型都正确计算了一个向量在另一个向量上的投影以及正交分量,表明它们在处理向量分解问题时具有较高的准确性和稳定性。
找到向量u=3i−5j+2k在向量v=7i+j−2k上的投影,以及u中与v正交的分量,显示所有步骤。

然而,不同模型在具体问题的解答能力上仍存在明显差异。
比如,求正交向量上,只有Claude 3.5 Sonnet最初回答错误,但在重提示后纠正了错误。
求一个同时正交于向量u=⟨4,−3,1⟩和v=⟨2,5,3⟩的单位向量,并展示所有步骤。

而在优化领域的求极值上,谷歌的Gemini Adavnced with 1.5 Pro直接翻车,提示它错误后,没有改正过来,两次持续出错,暴露了其在优化问题上的特定弱点。
检查函数的相对极值和鞍点:f(x, y)=-5x^2+4xy-y^2+16x+10。并给出全部步骤。

Meta AI在求一道积分问题上,回答错误;而ChatGPT 4o经过再提示后,几乎不会出错。
总体二样,大语言模型,在微积分测试中的表现存在差异。
其他20多个问题的具体测试结果,请参考原文。
对LLMs在微积分测试中的表现分析揭示了多个关键见解和趋势,这对于理解它们在数学问题求解中的能力和局限性至关重要。
ChatGPT 4o和Mistral AI以96.9%的得分并列第一,表现最优。
ChatGPT 4o在广泛的问题类型中均表现出色,展现了其强大的数学推理能力。而Mistral AI在向量微积分和多元微积分方面表现尤为突出。Gemini Advanced、Claude 3.5 Sonnet和Meta AI的表现相同,得分均为87.5%。
简单问题的稳定性:ChatGPT 4o 和Mistral AI在解答基础性问题(如向量计算、几何解释和基本求导)时展现出一致的准确性。这表明它们在处理基础微积分概念方面具备较强的稳健性和可靠性。
重新提示(Re-prompting)的有效性:在多次测试中,某些模型最初给出的答案错误,但在重新提示后成功修正。这表明通过迭代提问和反馈机制可以有效提升模型的表现。
特定领域的高准确性:在涉及方向余弦、偏导数、曲线积分等问题时,所有模型的解答均正确。这表明它们在这些微积分专题上具备较强的共识和理解能力。
复杂积分计算:在处理复杂积分(如迭代积分、三重积分和曲线下区域面积计算)时,模型普遍表现不佳。这表明它们在微积分求解方面仍有待改进。
优化问题:部分模型(尤其是Gemini Advanced with 1.5 Pro)在求解优化问题时表现较弱,尤其是在相对极值和鞍点的识别方面存在困难,说明其优化技术仍需加强。
持续性错误:某些模型在特定问题上反复出错。例如,Meta AI在积分计算上存在较大困难,而Gemini Advanced with 1.5 Pro在梯度计算上表现不佳。这些持续性错误表明其算法可能需要进一步优化。
本研究强调了重新提示机制在提高解题准确性方面的重要作用。
多个模型在第一次解答错误后,通过重新提示成功修正答案。
这表明迭代提问和反馈机制可以显著提高模型的解题能力,尤其是在复杂问题上,初始错误的可能性更大,而重新提示可以提高最终正确率。
本研究对各模型的表现进行了详细分析,为LLM技术的持续优化提供了有价值的见解。
研究结果揭示了当前LLM的优势与不足,为未来的定向改进提供了清晰的路线图,尤其是在以下几个方面:复杂积分计算、优化问题求解、梯度计算的精确性。
如果开发者能针对这些弱点进行优化,在数学问题求解中,将有助于提升LLM的整体性能和可靠性。
本研究的结果对教育工作者、研究人员和开发者都具有重要意义,尤其是在数学教育和实际应用方面:
参考资料:
https://arxiv.org/abs/2503.03960
文章来自于“新智元”,作者“KingHZ”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
