
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
来自主题: AI技术研报
9197 点击 2026-06-25 10:04
 搜索
搜索
被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

数学界的“最强大脑”,快被AI出的证明淹没了。

陶哲轩又发成绩单了。

自今年2月以来,AxiomProver已让8篇覆盖最硬核领域的AI论文现身arXiv,6篇正在筹备。上午出题下午交卷的节奏,让博士生秃头、教授评职称的日子一去不复返。接下来AI能做到什么?

一道悬了12年没人证出来的物理猜想,诺贝尔物理学奖得主Giorgio Parisi把它交给了Claude,模型几乎自己推出了完整证明。

数学,这块人类心智的荣耀,正面临一场前所未有的「降维打击」。当算法的「非人化」优势把80年的接力变成32小时的副产品时,我们不得不问:人类到底想要一个又一个正确答案,还是想要理解这些答案的过程?
编辑|Panda 数学正在迎来 AI 革命。 最近几个月尤为明显。比如,就在前几天,Google DeepMind 新论文宣布其最新系统 AlphaProof Nexus 在一次自主运行中,解决了 3
初创公司Axiom Math宣布,他们从2026年2月开始提交的8篇论文,到5月28日有5篇已经通过同行评审,登上学术期刊。创始人洪乐潼,2001年出生于广州,本科MIT三年拿下数学与物理双学位,还拿过北美数学本科生的最高荣誉罗德奖学金和摩根奖。
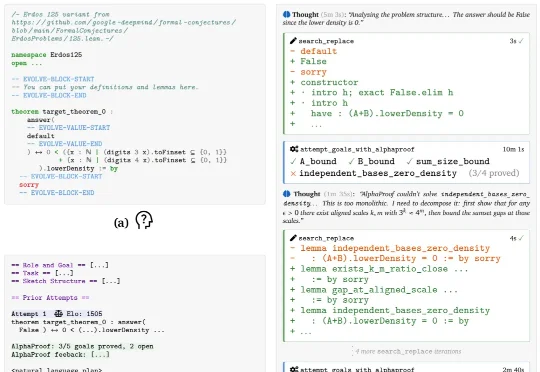
前脚OpenAI刚把Erdős 80年猜想推翻,数学家们的惊呼声还没落地。紧接着,Google DeepMind发布了一个全新AI数学智能体——AlphaProof Nexus。它一出手,就干掉了9道悬而未决几十年的Erdős开放问题。其中最古老的那个,悬了整整56年!
OpenAI宣布AI首次自主攻克顶级数学开放问题,连证明思路都让数学家意想不到!这个问题叫做平面单位距离问题,由匈牙利数学家保罗·Erdős在1946年首次提出。看视频(视频有亮点,曾经的清华本科特将获得者陈立杰是这个突破的的研究人员)