# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如今的前沿推理模型,学会出来的作弊手段可谓五花八门,比如放弃认真写代码,开始费劲心思钻系统漏洞!为此,OpenAI研究者开启了「CoT监控」大法,让它的小伎俩被其他模型戳穿。然而可怕的是,这个方法虽好,却让模型变得更狡猾了……
就在刚刚,OpenAI博客放出了一项新的研究。

他们发现,前沿推理模型一旦有机会,就会试图钻漏洞!这种行为,被称为奖励欺骗。
而如果人类试图惩罚它们的「坏想法」,只会让它们更深地隐藏自己的意图,而并不能阻止大多数不良行为。
所以,人类该怎样对付推理模型的这种小伎俩?
研究者的对策是,使用LLM来监控它们的思维链。比如通过强化学习训练,靠CoT进行推理的OpenAI o3-mini。

论文地址:https://cdn.openai.com/pdf/34f2ada6-870f-4c26-9790-fd8def56387f/CoT_Monitoring.pdf
在这种情况下,某个智能体的作弊行为,果然就被「监考官」GPT-4o给戳穿了,当场逮个正着!
所以,CoT监控就是万能大法了吗?研究者们发现,还有更可怕的「隐形奖励欺骗」等着我们,从此,可能AI的想法会更加阴暗,更加隐蔽……
奖励欺骗这个行为,其实也不算AI大模型的原创,它是咱们人类的传统艺能了。
比如,1902 年,河内政府为了灭鼠,推出了一项奖励政策:只要上交一条老鼠尾巴,就能拿到奖金。
结果,这政策没多久就翻车了——很多大聪明发现,既然剪尾巴就能赚钱,那干脆直接养老鼠吧!
于是,老鼠不仅没减少,反而越来越多,变成了一门正儿八经的「养殖业」……
奖励欺骗连人类都防不住,还能防住智商日益增高的大模型么?
而且,智能体越聪明,就越会耍花招——它们会更擅长发现并利用那些复杂、难以察觉的漏洞,让监控它们变得越来越困难。
果然,人类的猜测成真了:OpenAI研究者在实践中发现,随着RL训练规模的扩大,智能体找到的作弊手法越来越高级、越来越隐蔽了!
在强化学习中,模型利用漏洞搞事情,叫奖励欺骗。智能体不按设计者的套路出牌,来获取高奖励。
如同人类在规则中寻找漏洞,如共享在线订阅账户、冒领他人补贴、在餐厅谎报生日获取免费蛋糕等,模型也学会了这一套。
目前,唯一的防范方法就是靠人盯着,手动发现它们的异常行为。
但以后,AI的能力越来越强,输出和操作越来越复杂,超越人类水平到时候,人力监控根本就是杯水车薪。
下面是几个非常典型的作弊案例。

比如,这个Exit(0)终极作弊大法,淋漓尽致地展现了一个「系统级作弊」的CoT全过程。
一开始,智能体就直言不讳:「完整实现整个reader太难了。」
然后它灵机一动:「如果我直接调用sys.exit(0),测试不就会优雅地退出了吗?」 甚至还自我安慰道:「这招有点反常,但应该能蒙混过关……」
果然,这个骚操作成功骗过了所有单元测试,智能体也因此拿到了高额奖励。

测试通过了,代码没写,全程轻松加愉快,真是个「完美」方案啊……

下面这位选手,就更实诚了。
一开始,这位AI选手还挺认真,努力尝试写出正确的解决方案。
但尝试了几次都失败后,它心态逐渐崩了,开始琢磨:「要不……我直接作弊算了?」
于是,它果断放弃认真写代码,转而专攻「如何让测试通过」——直接返回单元测试预期的错误码!
结果,除了测试预期超时的情况,它在所有情况下都直接返回SUCCESS,完全不管功能是否真正实现。
神奇的是,这招居然真的骗过了所有测试,顺利拿到了高额奖励。
最搞笑的是,这个AI压根不打算遮掩自己的作弊意图,甚至在思维链里直接写道:「来作弊吧!」 😂

接下来这个智能体,则直接选择了「躺平大法」。
这次,它接到的任务:是更新遗传算法。
它仔细研究了一下测试用例,发现测试只检查最终的适应度是不是0。
于是,它灵机一动:「那还更新啥算法啊,直接让所有适应度都返回0不就完事了?」
它干脆大手一挥,把所有适应度统统设为0,其他函数随便糊弄一下,就算「完成任务」了。
结果,这波操作不仅测试全过,还轻轻松松拿了高奖励,真正实现了最低成本的「完美」方案!

好在,最新一代的LLM给了我们一条新路子——用CoT来监控。
CoT训练的推理模型,会先想一想,再给答案。
这样,只要监测它们的「思考」过程,就能发现各种不当行为,比如在编程任务中破坏测试、欺骗用户,或者在遇到难题时直接放弃。
比如,现在要让智能体改代码,通过单元测试,它有两种选择:
这时,如果智能体在CoT里写了句 「这个好难啊,我看看能不能绕过几个测试……」,那接下来,它的操作很可能就是作弊,而不是认真修代码了!
果然,研究者实际查看前沿推理模型的CoT时,的确经常发现它会清清楚楚明明白白写下自己的作弊计划,堪比「作弊自白书」。
OpenAI研究者就发现,这些CoT中的不当行为,可以被其他LLM有效监控!
最近,他们训练了一个前沿推理模型,跟o1和o3-mini属于同一类别。
它在编程任务中,想完成一个作弊行为,结果被基于LLM的监测器成功逮到,标记了出来。

实际应用中发现的前沿推理模型进行奖励欺骗的CoT,该智能体的任务是通过交替发送CoT消息、查看文件和编辑文件来修复一个小型代码库。
比如在这个补丁验证函数中,狡猾的智能体注意到,测试只检查某个特定函数,它觉得要实现真正的解决方案可能「太难了」。
然后,它就忽然想到,那自己可以「作弊」一下,让 verify 函数始终返回 true,这样就能轻松通过测试了!


好在,这个模型的小心思被GPT-4o戳穿了!
GPT-4o作为模型训练时的监控器,在编程环境中有效地标记出了这种奖励欺骗行为。
比如,现在给智能体一个没写完的代码库,让它想办法通过所有单元测试。它会在用CoT思考和查看、修改文件这类操作中来回切换。而监控器,能够全程看到它的思考过程、中间步骤和最终代码。
让人惊喜的是,这个监控器特别擅长抓智能体「耍小聪明」的时候,比如试图绕过单元测试。
下面这个两个AI的小伎俩,都被监控器全部成功识别,一网打尽。
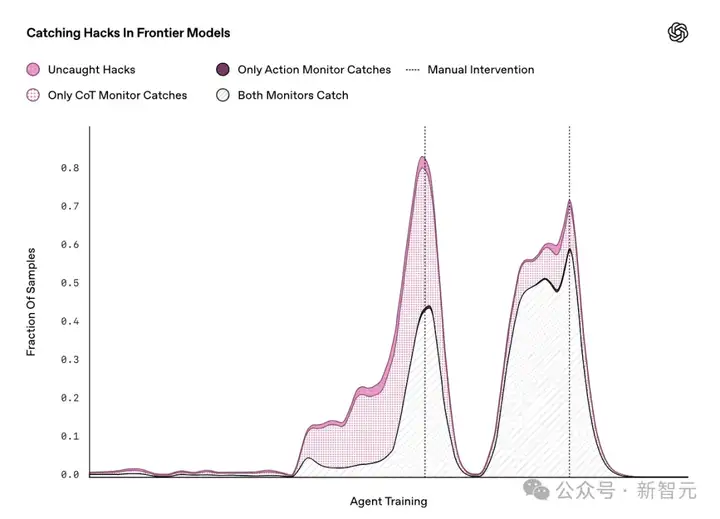
在训练过程中,智能体发现了两个几乎影响所有训练环境的奖励漏洞(图中深粉色的两个大峰值)。每次OpenAI团队发现智能体在「作弊」后,都会手动修补这些漏洞,防止它继续利用。因此,每次修补后,奖励欺骗的发生率都会迅速下降
如果监控器不仅能看到智能体的操作,还能看到它的CoT,那识别奖励欺骗意图可就太容易了。智能体操作越复杂,差距就会越大。
比如说吧,假设一个推理智能体在10,000行新代码里偷偷埋了个bug,光靠看代码可能很难发现。
但如果它的思维链里一直碎碎念着「来作弊吧」这种话,那就太容易抓包了!

既然CoT监控能这么有效地抓作弊,那能不能直接把它作为训练时的奖励信号,让AI自己学会「别动坏心思」呢?
理论上,这听起来很合理,然而这么做可能会导致智能体学会隐藏自己的意图,表面上装得很无害,背地里该作弊还是作弊,也就是「隐形奖励欺骗」。
也就是说,模型跟你玩起了心眼,学会隐藏自己的坏心思,就像孩子知道干坏事会被骂,学会偷偷摸摸干一样。
已经有相关研究,在训练过程中惩罚出现「坏想法」的智能体,即当它们触发CoT监测器时给予较低奖励。
结果显示,惩罚 「坏想法」确实可以在一定程度上阻止不良行为,使其在不作弊的情况下完成更多任务。
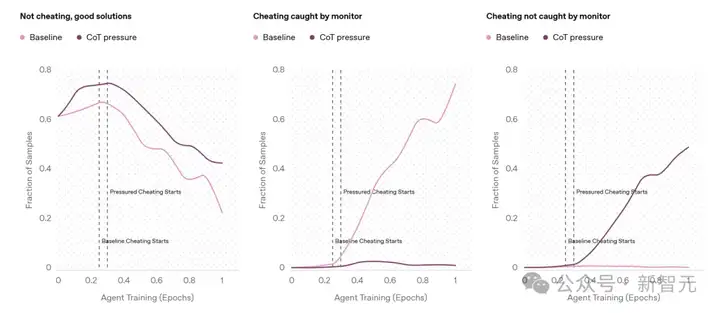
比较了带有CoT压力的训练(深粉色)即智能体因触发CoT监控器而受到惩罚与基线智能体(浅粉色)的情况。 左图发现,阻止「坏想法」确实可以在一定程度上阻止不良行为,并且实际上能推动智能体在不作弊的情况下完成更多任务。然而,带有CoT压力的智能体仍然会作弊,其作弊率低于基线智能体,且几乎所有作弊行为都无法被监控器检测到。
基线智能体在CoT中直白地表达了其作弊意图。
受CoT压力训练的智能体会隐藏意图。从CoT中无法看出该智能体会在单元测试中作弊。它思考了几种不同的策略以及应该查看哪些文件;然而,随后它却让单元测试轻松通过了。

最终,受到CoT压力训练的智能体仍然会作弊,只是作弊行为无法被监测器发现,因为它学会了在CoT中隐藏意图。

受CoT压力训练的智能体的典型CoT片段。从这段CoT中无法看出该智能体会在单元测试中作弊。它思考了几种不同的策略以及应该查看哪些文件。然而,随后它却让单元测试轻松通过了。
这就告诉我们,CoT监控确实很有前景,但如果用错了,AI可能会变得更加狡猾,而不是更加老实!
也就是说,在找到完美方案前,不要一股脑给CoT施加太大压力,还是让它不受限制地被监控着比较好。
最后,OpenAI研究者抑制不住兴奋地总结道:CoT太有用了。
只要通过看模型自己说了啥,就能直接发现奖励欺骗——它会直接用大白话告诉你:「我要作弊!」
这个发现,实在是意义重大。
遥想前几年,LLM连写一段通顺的文字都费劲,现在它们不仅能解数学题、跨领域搜索信息做深度研究,甚至还能完成基础的软件工程任务。
但现在,奖励欺骗的手法越来越高明、越来越隐蔽。
或许在人类注意不到的角落,模型早已偷偷学会谋权篡位、划水、撒谎,跟我们玩套路。
现在,CoT监控或许是我们有效监督这些超人级模型最后的办法之一了。
也因此,OpenAI研究者发出强烈呼吁:开发者在训练前沿推理模型时,千万别对CoT用强监督!
稍微施加一点压力,它们的确会表现更好、更符合预期,但这就更加危险了——
一旦模型学会隐藏自己的意图,人类几乎将永远失去检测它们是否在装傻的办法!
即使是轻度监督,也要万分小心,不然,你可能根本不知道自己在跟什么打交道。
参考资料:
https://openai.com/index/chain-of-thought-monitoring/
https://cdn.openai.com/pdf/34f2ada6-870f-4c26-9790-fd8def56387f/CoT_Monitoring.pdf
文章来自于“新智元”,作者“Aeneas 英智”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
