# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型长序列文本生成效率新突破——
生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!
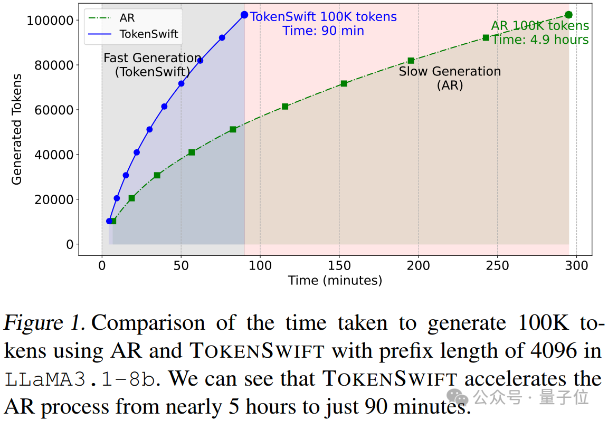
最新研究提出了一个名为TOKENSWIFT框架,从模型加载、KV缓存管理到Token生成策略进行了全方位的优化。
实验结果证明,该方法不仅能大幅提升生成效率,更在保证生成质量和多样性上实现了无损加速。
而且支持R1-Distill,团队发布经过微调的DeepSeek-R1-Distill-Qwen-32B模型,同样具备3倍加速效果。
来看demo展示:
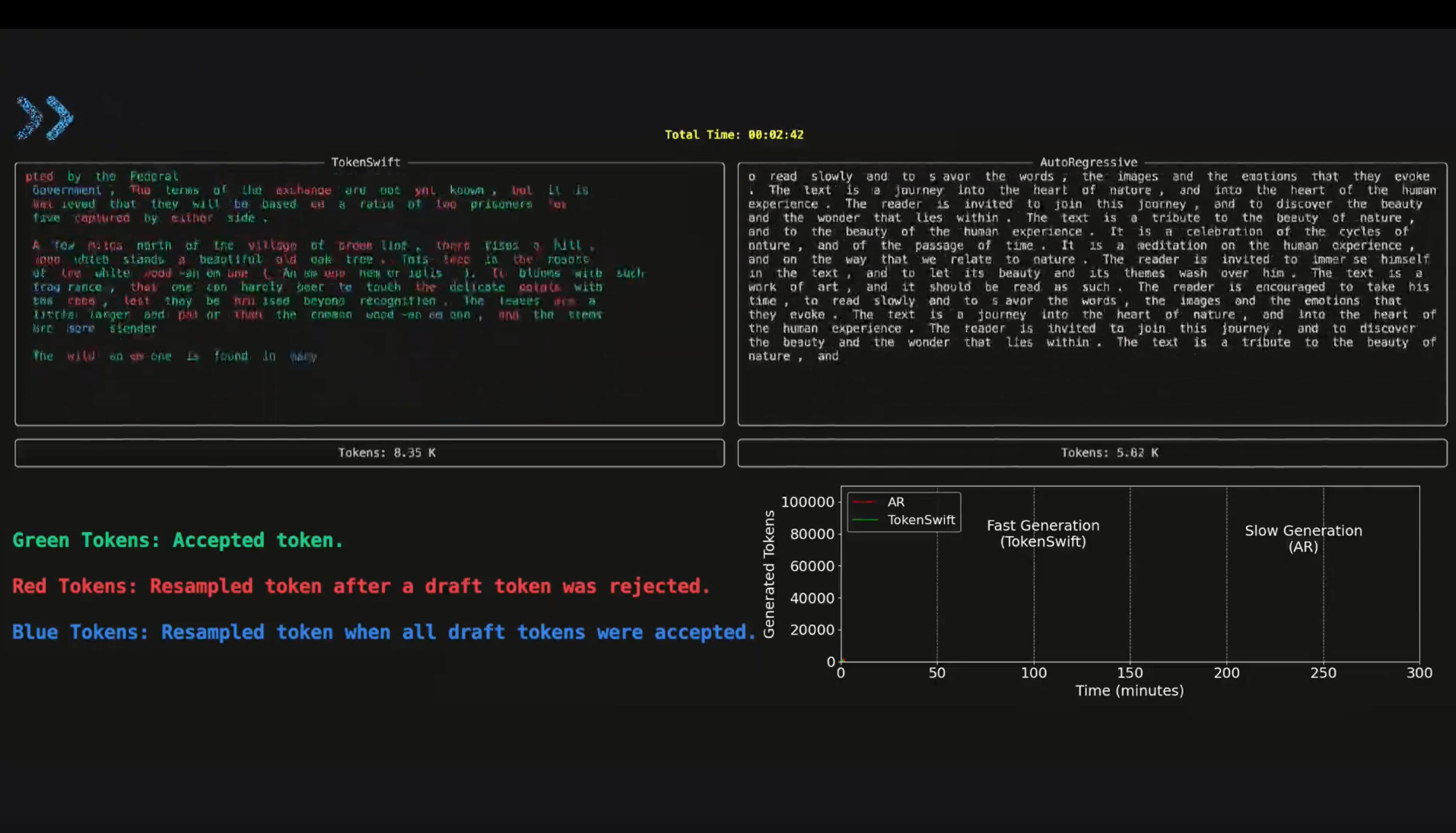
本研究由来自北京通用人工智能研究院的团队完成,以下是更多细节。

随着LLMs长上下文窗口能力的不断提升,复杂任务对超长文本生成的需求越来越高。
传统的自回归(AR)生成方式虽然在短文本上表现良好,但在长文本生成中存在明显瓶颈,主要体现在以下三个方面:
由于自回归生成每生成一个Token都需要从GPU存储中重新加载模型权重,导致I/O操作频繁、延迟高。
在生成10万Token时,模型需要重复加载上万次,严重拖慢整体生成速度。
生成超长文本过程中,模型内部的键值对(KV Cache)不断增长,若直接使用全量KV缓存,不仅超出内存预算,还会大幅增加计算时间。
如何在保证关键信息不丢失的前提下,实现KV缓存的高效更新成为一大难题。
长序列生成易出现重复和冗余问题,影响文本的多样性和质量。虽然重复问题并非论文的主要聚焦点,但在超长文本生成中依然需要有效抑制。
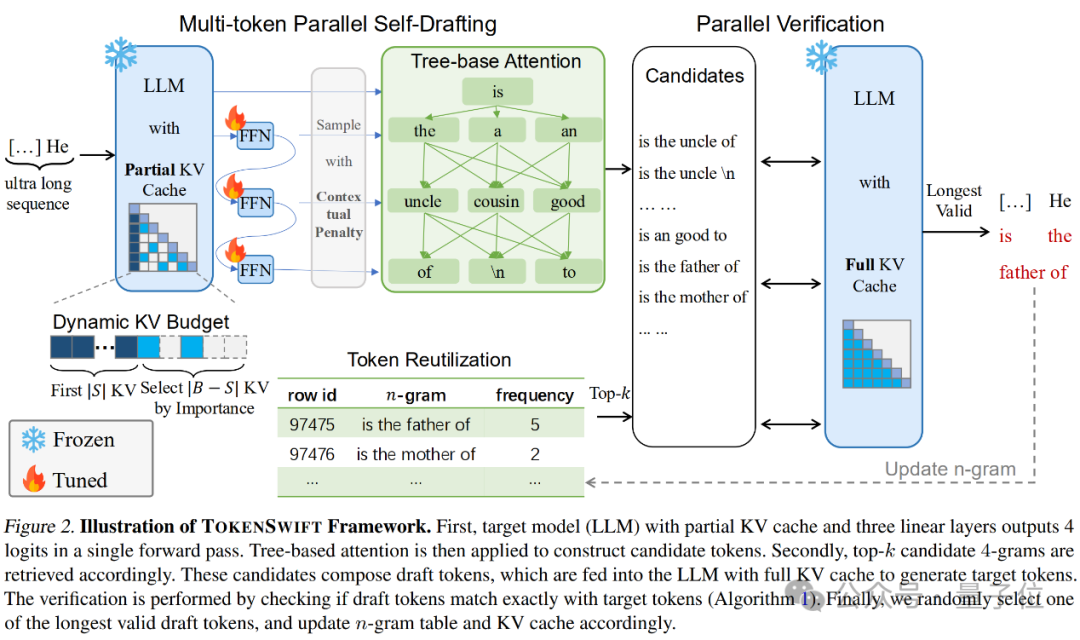
为解决上述难题,论文提出了TOKENSWIFT——一个全新的框架,旨在实现无损加速超长序列生成,其主要创新点体现在以下几个方面:
1)多Token并行生成与Token复用
论文借鉴了Medusa等方法,通过引入额外的线性层,使模型在一次前向传播中能够同时生成多个草稿Token。
更重要的是,基于生成文本中的n-gram频率信息,系统会自动检索并复用高频短语,从而进一步减少模型重新加载的次数,提升整体效率。
2)动态KV缓存更新策略
在KV缓存管理上,TOKENSWIFT采用动态更新策略。系统在生成过程中将初始KV缓存保留,同时根据Token的重要性对后续缓存进行有序替换。
这种方式不仅有效控制了缓存的规模,还确保了关键信息始终被保存,大幅降低了因缓存加载带来的延迟。
3)基于树结构的多候选Token验证
为保证生成结果与目标模型预测的一致性,TOKENSWIFT引入了树形注意力机制。
通过构建包含多个候选Token组合的树形结构,并采用并行验证的方式,从中随机选择最长且有效的n-gram作为最终输出,确保生成过程无损且多样性得到提升。
4)上下文惩罚策略
为了进一步抑制重复生成问题,论文设计了一种上下文惩罚方法。
该方法在生成过程中为近期生成的Token施加惩罚,使得模型在选择下一Token时更倾向于多样化输出,从而有效减少重复现象。
实验部分,论文在多种模型架构(包括MHA和GQA)及不同规模(1.5B、7B、8B、14B)上进行了充分测试。
结果表明,TOKENSWIFT在生成10万Token长序列时,相较于传统自回归方法,平均实现了3倍以上的加速,且生成结果在准确性和多样性上基本保持无损。
1)加速效果
实验数据显示,在LLaMA3.1-8B模型下,传统AR生成10万Token约需4.9小时,而使用TOKENSWIFT后仅需90分钟,大幅节省时间。
在Qwen2.5-14B时,传统AR生成10万Token更是达到了7.9小时,加速后仅需142分钟。这一成果对于实际应用中需要实时或高效长文本生成的场景具有重要意义。
2)验证率与接受率
论文设计了多项指标来评估生成质量,包括Token接受率和Distinct-n指标。
结果表明,TOKENSWIFT不仅在速度上显著领先,还能在保持无损生成的前提下,有效提升文本的多样性。
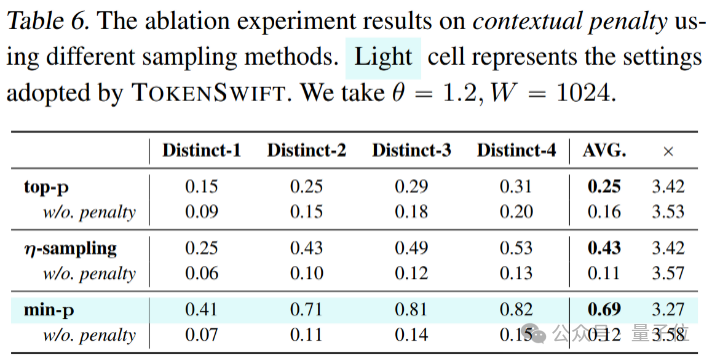
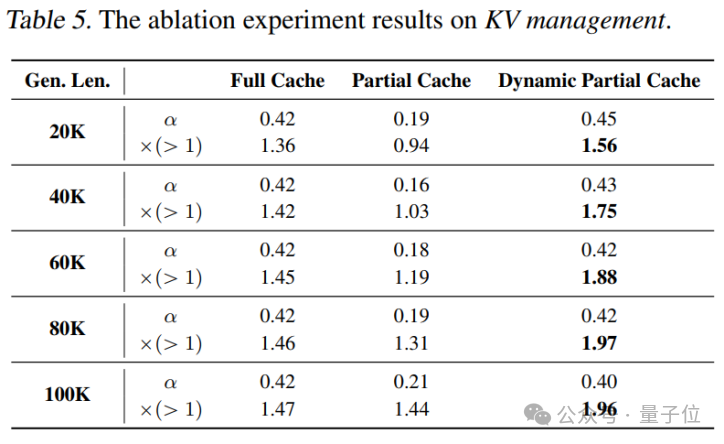
在深入理解TOKENSWIFT各模块贡献的过程中,论文还进行了全面的消融实验和案例分析,为优化方案提供了充分依据。
表明复用机制在减少模型加载次数、提升整体效率方面发挥了关键作用。
结果表明,全量缓存虽然在接受率上略占优势,但其高计算开销使得整体加速效果不理想;而一次性更新则因缓存膨胀导致性能下降。
动态更新策略则在保持高接受率的同时,实现了最佳的速度与资源平衡。
例如,在min-p采样场景下,Distinct-n平均得分从0.12提升至0.69,仅带来约8%的速度损失,充分验证了该策略在抑制重复生成方面的有效性。
论文还对比了在有无上下文惩罚条件下生成文本的差异,案例分析结果令人印象深刻:
而采用上下文惩罚后,重复问题明显延迟至约60K Token,且重复部分多表现为语义层次上的相似,而非直接复制,整体文本连贯性和可读性大幅改善。
为实际应用提供了更高质量的文本输出。

通过这些消融实验和案例分析,论文不仅证明了各关键技术模块的重要性,也为后续优化指明了方向,
充分体现了TOKENSWIFT在超长文本生成领域的先进性和实用性。
Arxiv:https://arxiv.org/abs/2502.18890
Github:https://github.com/bigai-nlco/TokenSwift
Blog:https://bigai-nlco.github.io/TokenSwift/
文章来自于微信公众号“量子位”,作者 :TOKENSWIFT团队



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
