# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让机器人轻松学习复杂技能有新框架了!
深圳大学大数据系统计算技术国家工程实验室李坚强教授团队联合鹏城国家实验室、北京理工莫斯科大学,提出了奖励函数与策略协同进化框架ROSKA。
在多个高维度机器人任务上,在仅使用89%训练样本的情况下,比现有SOTA方法平均性能提升95.3%。

众所周知,随着机器人技术的快速发展,其应用已渗透至日常生活和工业生产场景。
然而在多自由度机器人控制领域,传统强化学习方法高度依赖人工设计的奖励函数。
这类奖励函数需在任意状态转移过程中提供有效反馈,否则可能导致学习策略性能不足,这对开放环境下的机器人自主学习构成了关键挑战。
而ROSKA框架创新融合大语言模型的推理与代码生成能力,使机器人在学习过程中能够根据实时任务目标和策略表现动态调整奖励函数,
实现了奖励函数与强化学习策略的协同进化,并在一系复杂机器人技能学习任务上取得突破性进展。
实验结果显示,ROSKA框架在六类复杂多自由度机器人任务中均刷新了SOTA性能,相较于NVIDIA 2023年度十大进展之一的Eureka方法,
ROSKA方法在人类归一化得分指标上平均性能提升高达95%。
目前该成果被人工智能顶级会议AAAI 2025收录,深圳大学助理教授黄畅昕作为第一作者,并在大会上做口头报告(Oral)。
在高维机器人控制任务中,奖励函数的设计不仅需要考虑任务目标,还需要考虑机器人各个关节之间的复杂关系以及环境的动态变化。
传统方法依赖专家经验,设计周期长、成本高,难以推广到复杂任务中。
尽管大语言模型(LLM)为自动生成奖励函数提供了新思路,但现有方法(如Eureka)仍需从头训练策略,导致训练效率低下和计算资源浪费。
而ROSKA框架通过奖励-策略协同进化机制,解决了上述问题。
ROSKA框架的核心思想是将奖励函数的设计与策略的优化过程紧密结合,形成一个动态进化的闭环,从而在减少数据使用量的同时,显著提升策略的性能。
实验结果表明,ROSKA框架在多个高维机器人控制任务中表现优异。
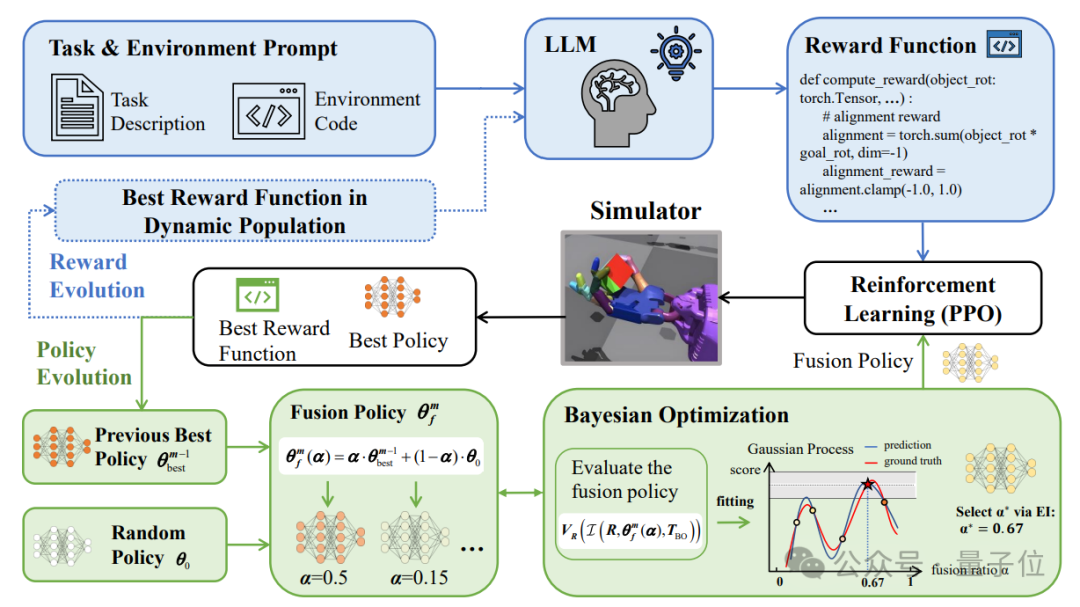
ROSKA框架通过将奖励函数和策略的进化过程结合起来,使得两者能够相互促进、共同优化。
奖励函数的进化过程可以根据策略的表现动态调整奖励函数的设计,而策略的进化过程则可以利用历史最优策略的知识来加速新奖励函数下的策略优化,
这种协同进化的方式不仅能够提高训练效率,还能够提升策略的适应性和可塑性,使得机器人能够在复杂环境中更快地学习和执行任务。
在策略进化部分,ROSKA框架通过融合历史最优策略和随机策略来生成新的策略候选。
策略的进化过程通过结合历史最优策略的知识和随机策略的探索能力,确保策略既能够继承已有经验,又具备足够的可塑性以适应新的奖励函数。
为了高效找到最优的策略融合比例,ROSKA采用了贝叶斯优化方法,通过评估不同融合比例下的策略表现,快速确定最优的融合方案。
实验在Isaac Gym仿真环境中进行,选择了六个具有代表性的机器人任务进行评估,
包括 Ant、Humanoid、ShadowHand、AllegroHand、FrankaCabinet 和 ShadowHandUpsideDown。
实验结果展示了ROSKA框架在多个高维机器人控制任务中的显著性能提升,这些任务涵盖了从简单的运动控制到复杂的物体操作,
能够全面测试ROSKA框架在不同场景下的表现。
各方法在机器人任务中的MTS柱状图如下:
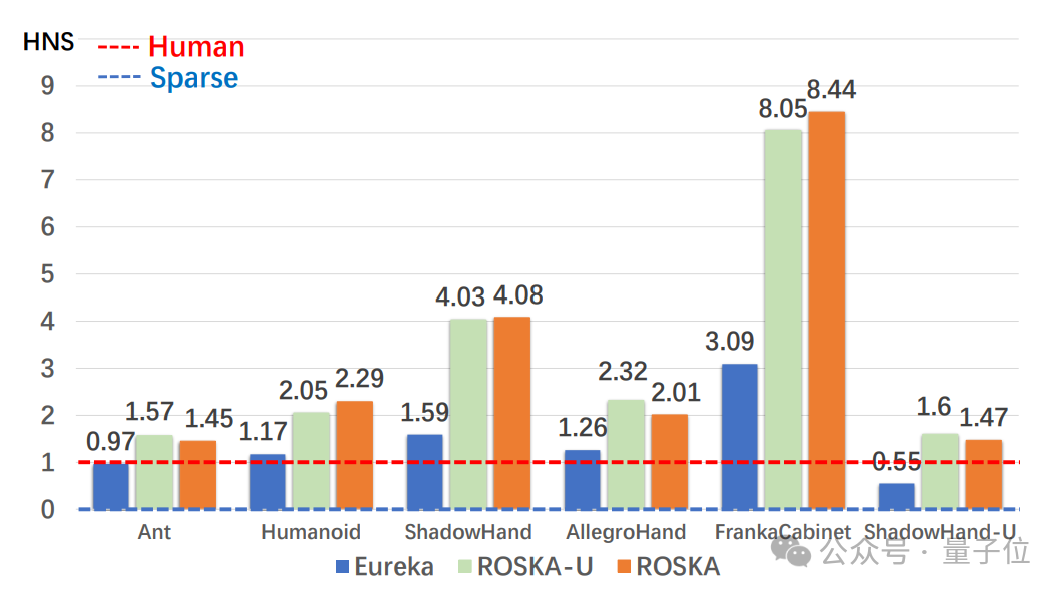
为了更直观地比较不同方法的性能,团队采用了人类归一化得分(Human Normalized Score) 作为评价指标。
HNS通过将算法的表现与人类设计的奖励函数表现进行对比,提供了更直观的性能评估。
如上图所示,ROSKA在所有任务中的HNS均超过了人类专家基线(红色线条),表明其性能优于人类设计的奖励函数。
特别是在ShadowHand和FrankaCabinet任务中,ROSKA方法远超其他基线方法。
与SOTA方法Eureka相比,ROSKA在HNS指标上的平均改进率达到95.3%,进一步验证了其在高维机器人控制任务中的优越性。
其中在ShadowHand任务中,ROSKA方法相比Eureka提升了 154.6%。在ShadowHandUpsideDown任务中,ROSKA方法相比Eureka提升了184.07%。
这些结果表明,ROSKA通过奖励-策略协同进化机制,能够显著提升策略的性能,尤其是在复杂任务中表现尤为突出。
整体而言,ROSKA框架借助大规模合成数据与智能进化机制训练而成,采用奖励函数-策略协同进化机制,
通过动态奖励种群生成与短路径贝叶斯优化策略实现双向优化。
实验验证框架在多项高维度机器人控制任务中实现显著突破。
相比现有SOTA方法Eureka,在仅使用89%训练样本的情况下,在多个高维度机器人任务上实现了平均95.3%的标准化性能提升,
验证了该框架在机器人技能学习任务中的强大适应能力。
更多方法和实验细节,请参考论文。
项目地址:
https://github.com/NextMyLove/ROSKA
论文:
https://arxiv.org/abs/2412.13492
文章来自于微信公众号 “量子位”,作者 :ROSKA团队



