# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Google DeepMind,交卷!
刚刚,Jeff Dean和Hassabis联手发文,一同回顾了Google Research和Google DeepMind在2023年的全部成果。
这一年开年,比起风靡全球的ChatGPT,谷歌看上去输惨了。当时,数不清的资本热钱向着OpenA流去,OpenAI的市值、知名度瞬间飙至前所未有的高度。
4月,陷入被动的谷歌放出终极大杀招:谷歌大脑和DeepMind正式合并!「王不见王」的两大部门惊人合体,Jeff Dean和Hassabis终于联手。
5月,谷歌在I/O大会上一雪前耻。全新的PaLM 2反超GPT-4,办公全家桶炸裂升级,Bard直接史诗级进化。
12月,谷歌深夜放出了复仇杀器Gemini,最强原生多模态直接碾压了GPT-4。虽然在产品demo上有加工制作的成分,但不可否认,谷歌已经把全世界的多模态研究推至前所未有的高度。
让我们看一看,谷歌的诸位神人们是怎样团结在一起,打响23年的复仇之战的。
这一年,生成式AI正式进入了大爆发。
2月,谷歌紧急推出了Bard,慢于OpenAI两个月推出了自己的AI聊天机器人。
5月,谷歌在I/O大会上宣布了积累数月和数年的研究和成果,包括语言模型PaLM 2。它整合了计算优化扩展、改进的数据集组合和模型架构,即使在很高级的推理任务中,表现也很出色。

针对不同目的对PaLM 2进行微调和指令调整后,谷歌将其集成到了众多Google产品和功能中,包括:
1. Bard
现在,Bard能支持40多种语言和230多个国家和地区,在日常使用的Google工具(如Gmail、Google地图、YouTube)中,都可以使用Bard查找信息。
2. 搜索生成体验(SGE)
它用LLM重新构想如何组织信息以及如何帮用户浏览信息,为谷歌的核心搜索产品创建了更流畅的对话式交互模型。
3. MusicLM
这个由AudioLM和MuLAN提供支持的文本到音乐模型,可以从文本、哼唱、图像或视频、音乐伴奏、歌曲中制作音乐。
4. Duet AI
Google Workspace中的Duet AI可以帮助用户创作文字、创建图像、分析电子表格、起草和总结电子邮件和聊天消息,总结会议等。Google Cloud中的Duet AI可以帮助用户编写、部署、扩展和监控应用,以及识别和解决网络安全威胁。
文章地址:https://blog.google/technology/developers/google-io-2023-100-announcements/
继去年发布文本到图像生成模型Imagen之后,今年6月,谷歌又发布了Imagen Editor,它提供了使用区域掩码和自然语言提示编辑生成图像的功能,从而对模型输出进行更精确的控制。

随后,谷歌又发布了Imagen 2,它通过专门的图像美学模型改进了输出,这个图像美学模型参考了人类对良好照明、取景、曝光和清晰度的偏好。

10月,谷歌推出了Google搜索的一项新功能,帮助用户练习口语、提高语言技能。
实现这一功能的关键技术,就是和谷歌翻译团队合作开发的一种全新深度学习模型,名为Deep Aligner。
与基于隐马尔可夫模型(HMM)的对齐方法相比,这个单一的新模型极大提高了所有测试语言对的对齐质量,将平均对齐错误率从25%降低到5%。
11月,谷歌与YouTube合作发布了Lyria,这是谷歌迄今为止最先进的AI音乐生成模型。
12月,谷歌推出了Gemini,这是谷歌最强大、最通用的AI模型。
从一开始,Gemini就被构建为跨文本、音频、图像和视频的多模态模型。
Gemini有三种不同尺寸,Nano、Pro和Ultra。Nano是最小、最高效的模型,用于为Pixel等产品提供设备端体验。Pro模型功能强大,最适合跨任务扩展。Ultra模型是最大、性能最强的模型,适用于高度复杂的任务。
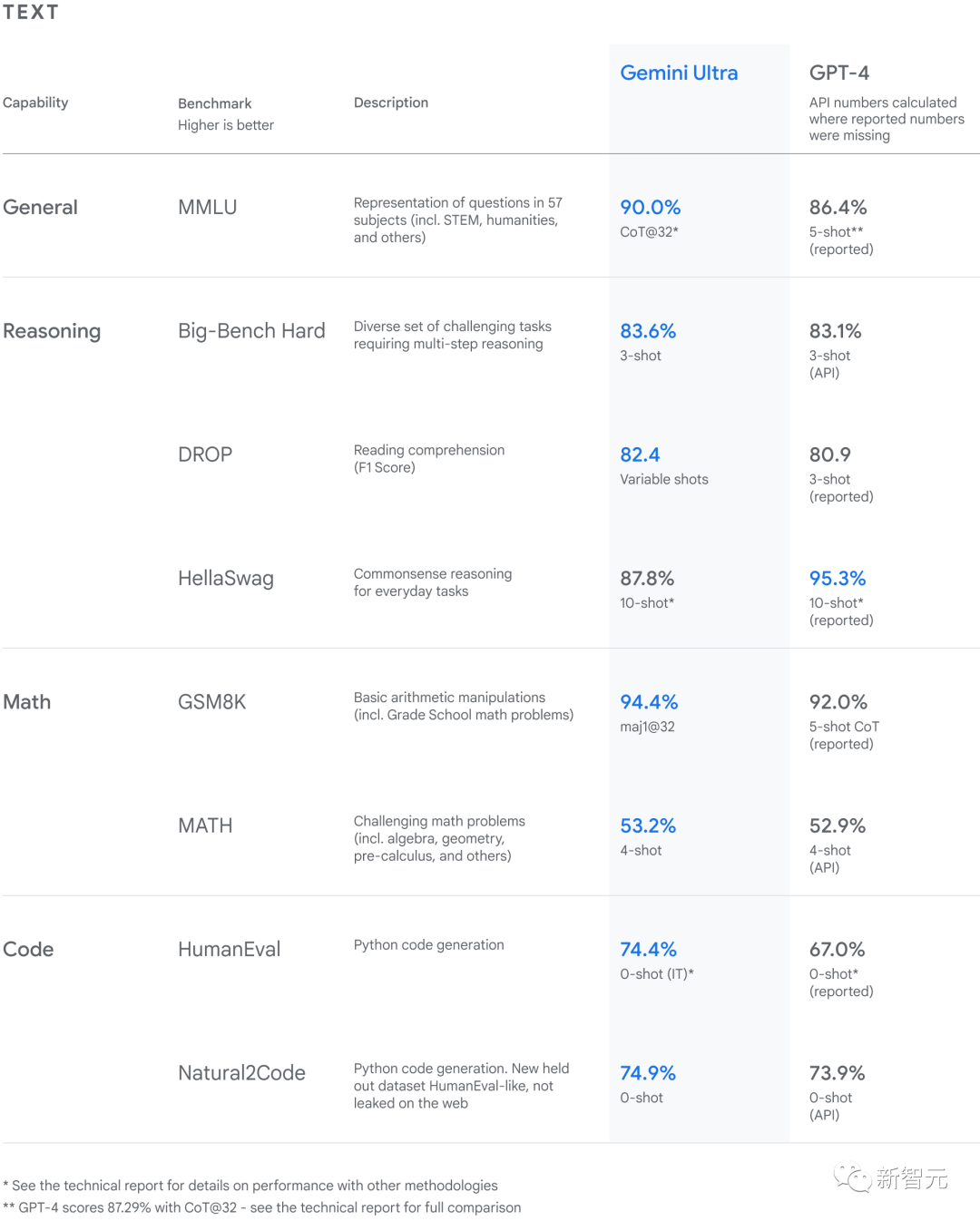
根据Gemini模型的技术报告,Gemini Ultra的性能超过了32个广泛使用的学术基准中的30个最新结果。
Gemini Ultra的得分为 90.04%,是第一款在MMLU上表现优于人类专家的模型,并在新的MMMU基准测试中获得了59.4%的最高分。
在AlphaCode的基础上,谷歌推出了由Gemini的专用版本支持的AlphaCode 2,这是第一个在编程竞赛中取得中位数水平表现的AI系统。
跟原始AlphaCode相比,AlphaCode 2解决的问题为1.7倍以上,表现要优于85%的参赛者。

同时,Gemini Pro模型的加持让Bard也获得了大升级,理解、总结、推理、编码和计划能力都大大提高。
在八项基准测试中的六项中,Gemini Pro的表现都优于GPT-3.5,包括LLM的关键标准之一MMLU和衡量小学数学推理的GSM8K。
明年初,Gemini Ultra也会引入Bard,届时必将引发全新的尖端AI体验。
而且,Gemini Pro也可用于Vertex AI,这是Google Cloud的端到端 AI 平台,使开发人员能够构建处理文本、代码、图像和视频信息的应用程序。

应用程序,可以处理文本、代码、图像和视频信息的应用程序。Gemini Pro 也于 12 月在 AI Studio 中推出。
可以看到,Gemini能够做到的事情包括但不限于——
解锁科学文献中的见解。
擅长竞争性编程。
处理和理解原始音频。
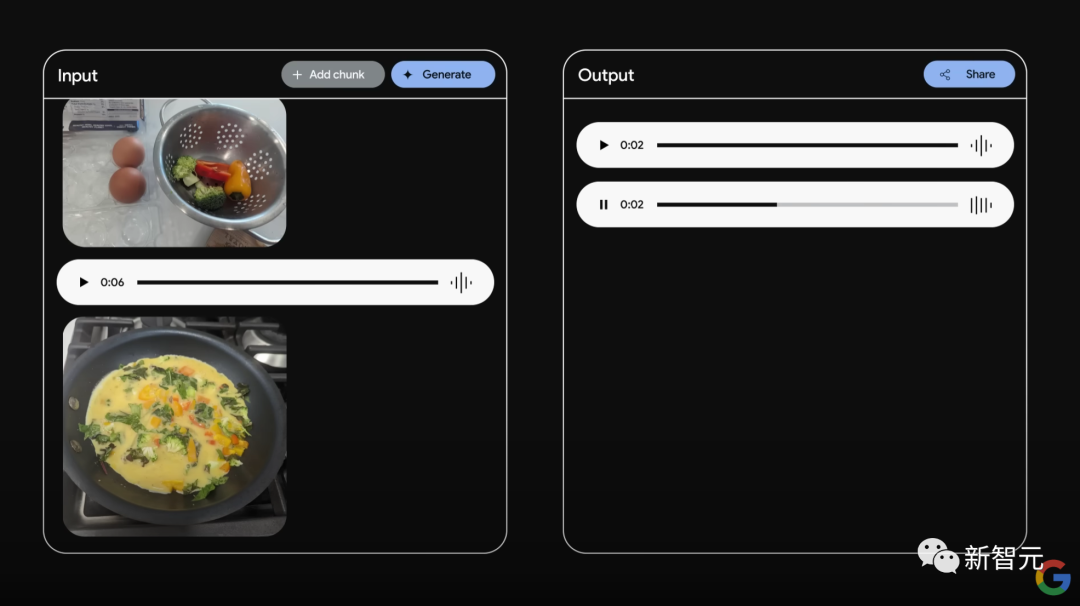
Gemini可以回答为什么这个菜还没炒熟:因为鸡蛋是生的
解释数学和物理中的推理。
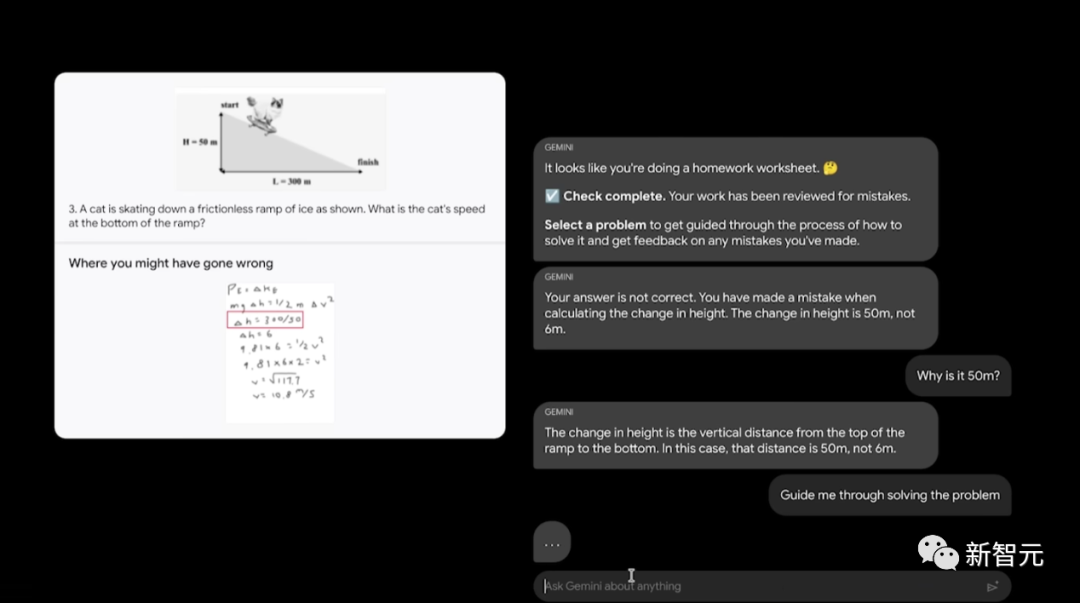
了解用户意图,提供定制体验。
除了在产品和技术方面的进步外,这一年谷歌也在机器学习和AI研究的更广泛领域,取得了许多重要进展。
如今最先进的机器学习模型,核心架构便是谷歌研究人员在2017年开发的Transformer架构。
起初,Transformer是为语言而开发的,但如今,它已被证明在计算机视觉、音频、基因组学、蛋白质折叠等各种领域都有极大作用。
今年谷歌在扩展视觉Transformer方面的工作,在各种视觉任务中都达到了SOTA,还能用于构建功能更强大的机器人。
扩展模型的多功能性,需要执行更高层次和多步骤推理的能力。
今年,谷歌通过几个研究接近了这个目标。
例如,算法提示(algorithmic prompting)的新方法,通过演示一系列算法步骤来教语言模型推理,然后模型可以将其应用于新的上下文中。
这种方法将中学数学基准的准确率从25.9%提高到了61.1%。

在视觉问答领域,谷歌与UC伯克利的研究人员合作,通过将视觉模型与语言模型相结合,使其更好地回答复杂的视觉问题——「马车在马的右边吗?」
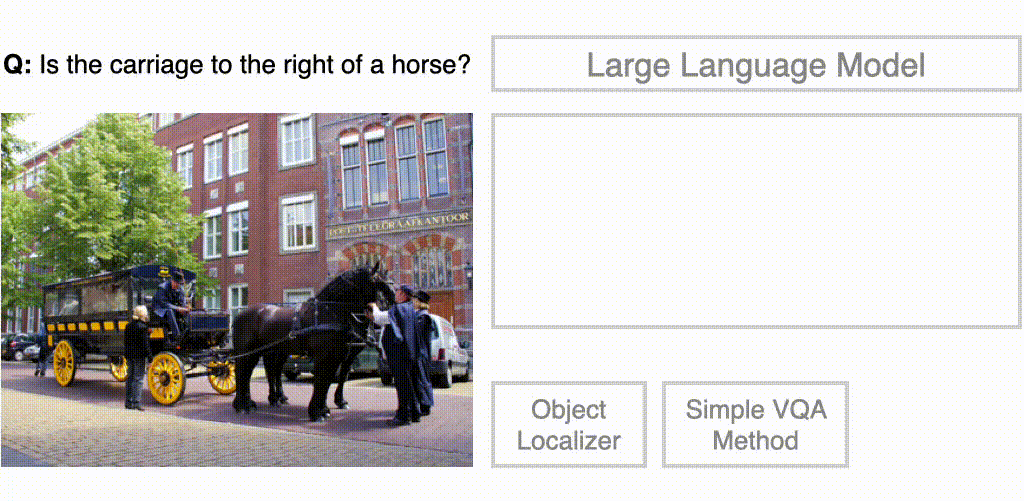
CodeVQA方法的图示。首先,大语言模型生成一个Python程序,该程序调用表示问题的可视化函数。在此示例中,使用简单的VQA方法来回答问题的一部分,并使用对象定位器来查找所提及对象的位置。然后,程序通过组合这些函数的输出来生成原始问题的答案
其中语言模型被训练为通过合成程序执行多步骤推理,来回答视觉问题。
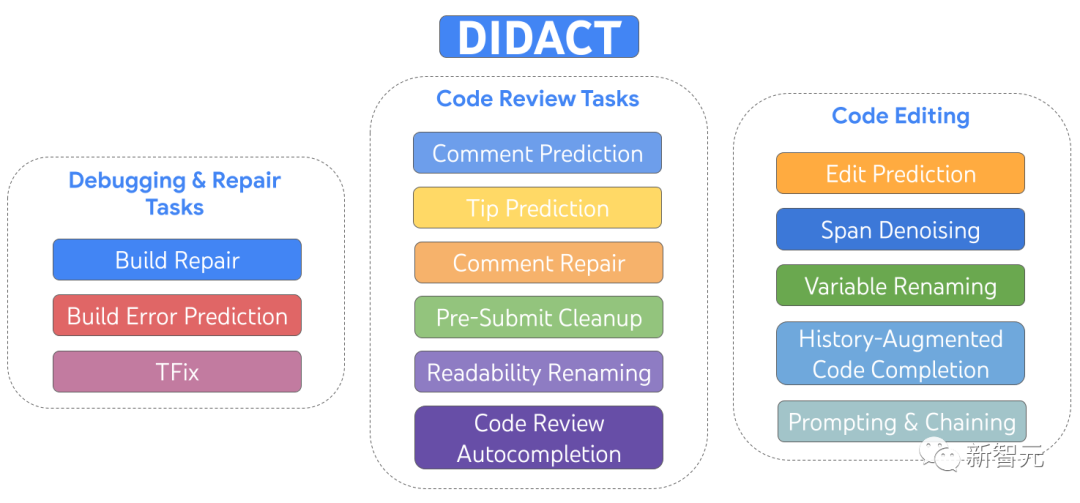
为了训练用于软件开发的大型机器学习模型,谷歌开发了一个名为DIDACT的通用模型。
它了解软件开发生命周期的方方面面,可以自动生成代码审查注释、响应代码审查注释、为代码片段提出性能改进建议、修复代码以响应编译错误等等。
与谷歌地图团队的多年合作中,谷歌扩展了逆强化学习,并将其应用于为超过10亿用户改进路线建议的世界级问题。
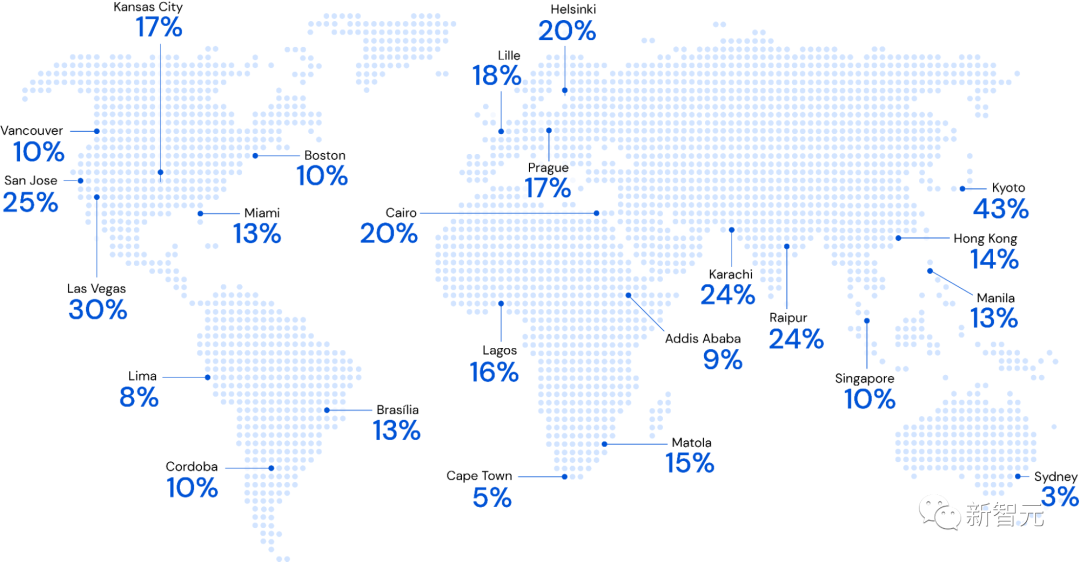
使用RHIP逆强化学习策略时,Google地图相对于现有基准的路线匹配率有所改进
这项工作最终使全球路线匹配率相对提高了16-24%,确保路线更好地符合用户偏好。
谷歌也在继续研究提高机器学习模型推理性能的技术。
在研究神经网络中剪枝连接的计算友好方法时,团队设计出一种近似算法,来解决计算上难以解决的最佳子集选择问题,该算法能够从图像分类模型中修剪70%的边缘,并且仍然保留原始模型的几乎所有精度。
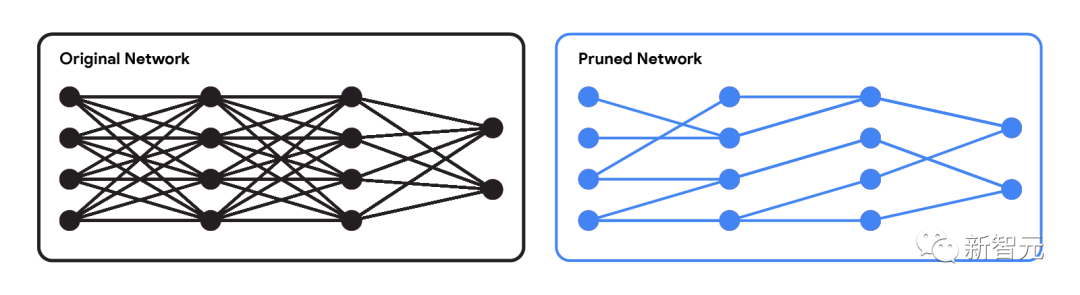
原始网络与修剪后的网络
在加速设备端扩散模型的过程中,谷歌对注意力机制、卷积核和操作融合进行各种优化,以便在设备上运行高质量的图像生成模型。
现在只需12秒,就能在智能手机上生成「被周围花朵包围的可爱小狗的逼真高分辨率图像」。
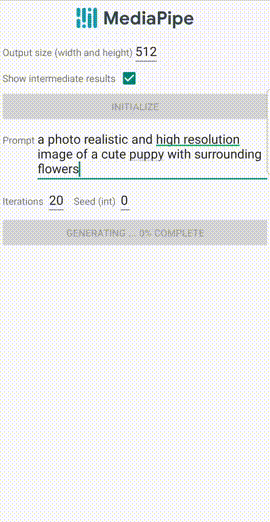

移动GPU上的LDM的示例输出,prompt:「一张可爱的小狗的照片逼真的高分辨率图像,周围有花朵」
语言和多模态模型的进步,也有利于机器人研究工作。
谷歌将单独训练的语言、视觉和机器人控制模型组合成PaLM-E(一种用于机器人的具身多模态模型)和Robotic Transformer 2(RT-2)。
这是一种新颖的视觉-语言-行动(VLA) 模型,它从网络和机器人数据中学习,并将这些知识转化为机器人控制的通用指令。
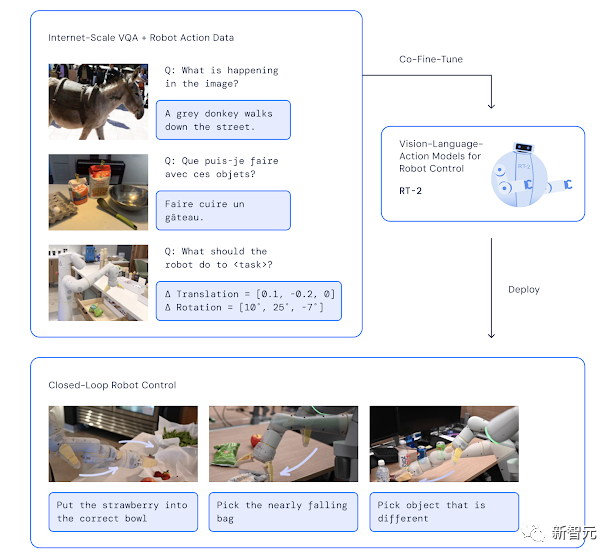
RT-2架构和训练:在机器人和网络数据上共同微调预训练的视觉语言模型。生成的模型接收机器人摄像头图像,并直接预测机器人要执行的动作
此外,谷歌还研究了使用语言来控制四足机器人的步态。

SayTap使用脚部接触模式(例如,插图中每只脚的0和1序列,其中0表示空中的脚,1表示地面的脚)作为桥接自然语言用户命令和低级控制命令的接口。通过基于强化学习的运动控制器,SayTap允许四足机器人接受简单直接的指令(例如,「缓慢向前小跑」)以及模糊的用户命令(例如,「好消息,我们这个周末要去野餐!」),并做出相应的反应
同时探索了通过使用语言来帮助制定更明确的奖励函数,以弥合人类语言和机器人动作之间的差距。
语言到奖励系统由两个核心组件组成:(1) 奖励翻译器和 (2) 运动控制器。Reward Translator将来自用户的自然语言指令映射到表示为python代码的奖励函数。运动控制器使用后退水平优化来优化给定的奖励函数,以找到最佳的低级机器人动作,例如应施加到每个机器人电机的扭矩量。
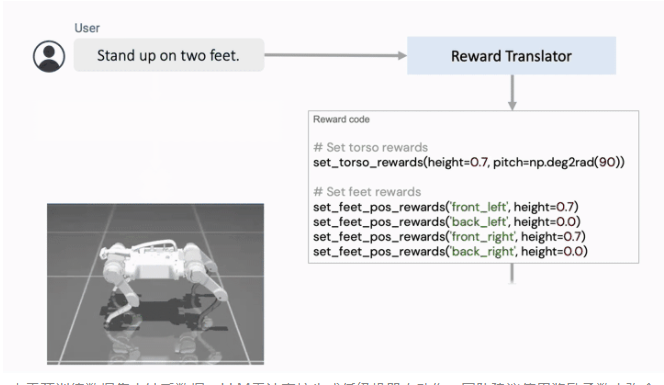
由于预训练数据集中缺乏数据,LLM无法直接生成低级机器人动作。团队建议使用奖励函数来弥合语言和低级机器人动作之间的差距,并从自然语言指令中实现新颖的复杂机器人运动

在Barkour中,团队对四足机器人的敏捷性极限进行了基准测试。

几位狗狗被邀请来参与障碍赛,结果显示:小型犬能在约10秒内完成障碍赛,机器狗一般要花20秒左右
算法与优化
设计高效、稳健和可扩展的算法始终是谷歌研究的重点。
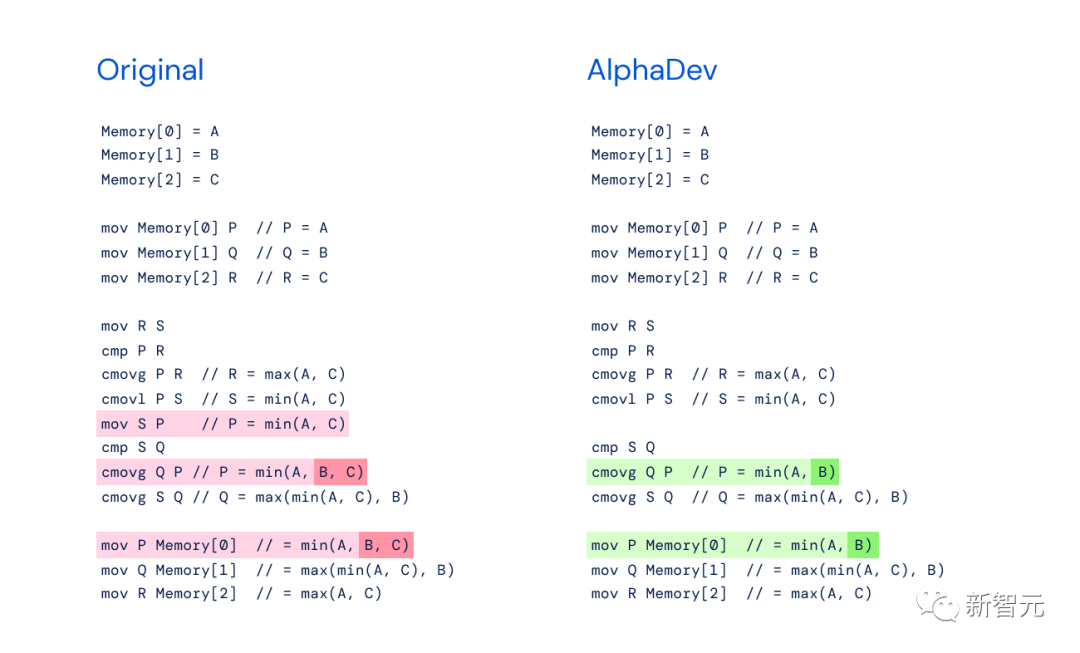
最为重磅的成果之一,便是打破了十年算法瓶颈的AlphaDev。
它的创新意义在于,AlphaDev并不是通过改进现有算法,而是利用强化学习完全从头开始发现了更快的算法。

论文地址:https://www.nature.com/articles/s41586-023-06004-9
结果显示,AlphaDev发现新的排序算法,为LLVM libc++排序库带来了明显的改进。对于较短的序列,速度提高了70%,而对于超过250,000个元素的序列,速度提高了约1.7%。
现在,这个算法已经成为两个标准C++编码库的一部分,每天都会被全球的程序员使用数万亿次。
为了更好地评估大型程序的执行性能,谷歌开发了可以用来预测大型图(large graphs)特性的全新算法,并配合发布了全新的数据集TPUGraphs。
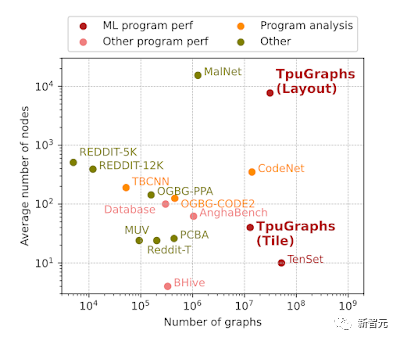
TPUGraphs数据集包含4400万个用于机器学习程序优化的图
此外,谷歌还提出了一种新的负载均衡算法——Prequal,它能够在分配服务器查询时,显著节约CPU资源、减少响应时间和内存使用。
谷歌通过开发新的计算最小割、近似相关聚类和大规模并行图聚类技术,改进了聚类和图算法的SOTA。
其中包括,专为拥有万亿条边的图设计的新型分层聚类算法TeraHAC;可以同时实现高质量和高可扩展性的文本聚类算法KwikBucks;以及用于近似多嵌入模型标准相似函数Chamfer Distance的高效算法,与高度优化的精确算法相比,该算法的速度提高了50倍以上,并可扩展至数十亿个点。
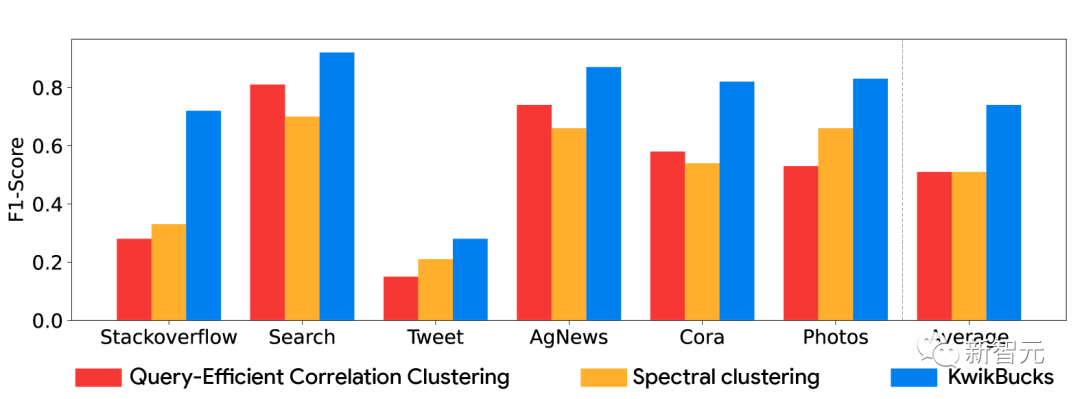
此外,谷歌还对大规模嵌入模型 (LEMs) 了进行优化。
其中包括,统一嵌入 (Unified Embedding),它在大规模机器学习系统中提供了经过实战测试的特征表示,以及序列注意力 (Sequential Attention) 机制,它在模型训练过程中可以发现高效的稀疏模型结构。
在不远的将来,AI在科学研究中的应用,有望将某些领域的发现速度提升10倍、100倍甚至更多。
从而推动生物工程、材料科学、天气预测、气候预报、神经科学、遗传医学和医疗保健等众多领域取得重大突破。
在对飞机尾流 (contrails) 的研究中,谷歌通过分析大量天气数据、历史卫星图像和以往的飞行记录,训练了一个能够预测飞机尾流的形成区域,并据此调整航线的AI模型。结果显示,这一系统可以将飞机尾流减少54%。
为了帮助抵御气候变化带来的种种挑战,谷歌一直致力于开发全新的技术方法。
举例来说,谷歌的洪水预报服务目前已经覆盖了80个国家,能够直接影响超过4.6亿人口。

此外,谷歌在天气预测模型的开发上也有了最新的进展。
在MetNet和MetNet-2的基础上,谷歌打造了更强的MetNet-3,可以在长达24小时的时间范围内,实现超越传统数值天气模拟的效果。
在中期天气预报领域,全新AI模型GraphCast可在1分钟内,精准预测10天全球天气,甚至还可以预测极端天气事件。

论文地址:https://www.science.org/doi/10.1126/science.adi2336
研究发现,与行业黄金标准天气模拟系统——高分辨率预报(HRES)相比,GraphCast在1380个测试变量中准确预测超过90%。
而且,GraphCast还能比传统预报模型更早地识别出恶劣天气事件——提前3天预测出未来气旋的潜在路径。
值得一提的是,GraphCast模型的源代码已经全部开放,从而让世界各地的科学家和预报员可以造福全球数十亿人。
在医疗健康领域,AI展现出了巨大的潜力。
初代Med-PaLM,是第一个通过美国医学执照考试的AI模型。随后的Med-PaLM 2,又在此基础上进一步提升了19%,达到了86.5%的专家级准确率。
而最近发布的多模态Med-PaLM M,不仅可以处理自然语言输入,而且还能够解释医学图像、文本数据以及其他多种数据类型。
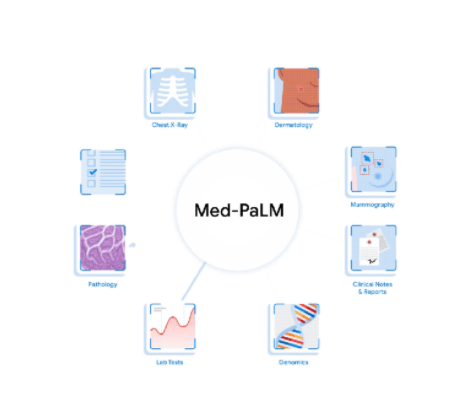
Med-PaLM M是一个大规模多模态生成模型,它能用相同的模型权重灵活地编码和解释生物医学数据,包括临床语言、成像和基因组学数据
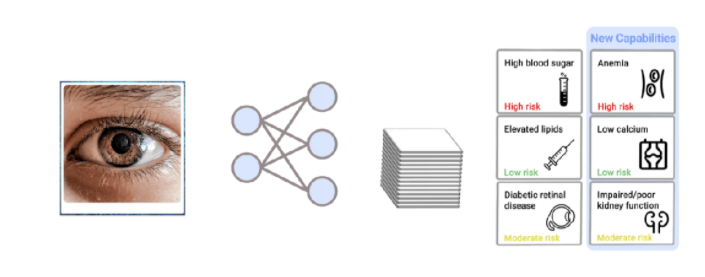
不仅如此,AI系统还能在现有医疗数据中探索出全新的信号和生物标记。
通过分析视网膜图像,谷歌证明了可以从眼睛的照片中预测出多个与不同器官系统(如肾脏、血液、肝脏)相关的全新生物标记。
在另一项研究中,谷歌还发现,将视网膜图像与基因信息相结合有助于揭示一些与衰老相关的根本因素。
在基因组学领域,谷歌与60家机构的119位科学家合作,绘制出了新的人类基因组图谱。
并且,在开创性的AlphaFold基础上,为所有7100万个可能的错义变体中的89%,提供了预测目录。
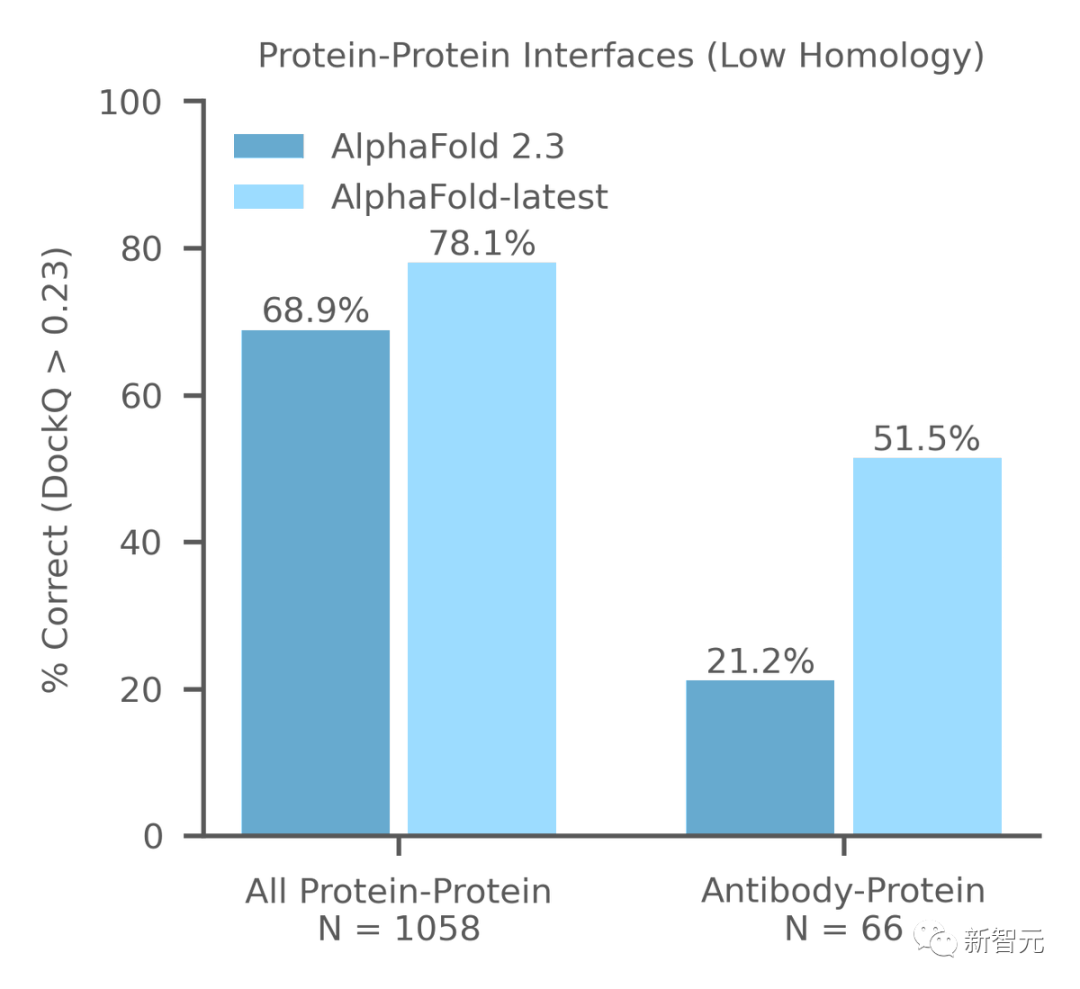
此外,谷歌还发布了AlphaFold最新进展——「AlphaFold-latest」,它可以对蛋白质数据库(PDB)中几乎所有分子,进行原子级精确的结构预测。
这一进展不仅深化了我们对生物分子的理解,而且还大幅提升了在配体(小分子)、蛋白质、核酸(DNA和RNA)以及含有翻译后修饰(PTMs)的生物大分子等多个重要领域的准确性。
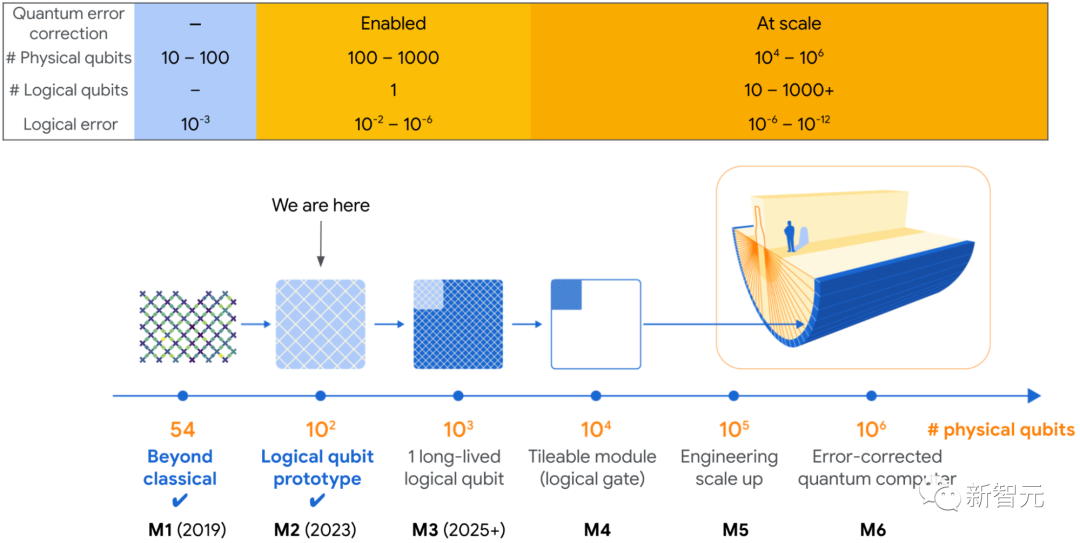
量子计算机具有解决科学和工业领域重大现实问题的潜力。
但要实现这一潜力,量子计算机的规模必须比现在大得多,而且必须能够可靠地执行经典计算机无法执行的任务。
为了保证量子计算的可靠性,还需要将它的错误率从现在的10^3分之一降低到10^8分之一。
今年,谷歌在开发大型实用量子计算机的道路上迈出了重要一步——有史以来首次通过增加量子比特来降低计算错误率。
生成式AI正在医疗、教育、安全、能源、交通、制造和娱乐等众多领域带来革命性的影响。
面对这些飞跃的发展,确保技术设计符合谷歌的AI原则依然是首要任务。

在不断推进机器学习和人工智能的最新技术的同时,谷歌也致力于帮助人们理解并将AI应用于特定问题。
为此,谷歌推出了基于网页的平台Google AI Studio,帮助开发者打造并迭代轻量级的AI应用。
同时,为了帮助AI工程师能够更深入地理解和调试AI,谷歌还推出了最先进的开源机器学习模型调试工具——LIT 1.0。
作为谷歌最受欢迎的工具之一,Colab可以让开发者和学生直接在浏览器中访问强大的计算资源,目前已拥有超过1000万用户。
前段时间,谷歌又在Colab中加入了AI代码辅助功能,让所有的用户都够在数据分析和机器学习工作流中,拥有更加便捷和一体化的体验。
就在最近,谷歌为了确保AI能够在实际应用中提供正确无误的信息,创新性地推出了FunSearch方法。
通过进化算法和大语言模型的结合,FunSearch能够在数学科学领域生成经过验证的真实知识。
具体来说,FunSearch将预训练的LLM与自动「评估器」配对使用。前者的目标是以计算机代码的形式提供创造性的解决方案,后者则防止幻觉和错误的想法。在这两个组件之间反复迭代之后,初始的解决方案便会「进化」为新知识。

论文地址:https://www.nature.com/articles/s41586-023-06924-6
通过发表研究成果、参与和组织学术会议,谷歌正在持续推动AI和计算机科学的发展。
今年,谷歌已发表了500多篇论文。其中,有不少都被收录在了包括ICML、ICLR、NeurIPS、ICCV、CVPR、ACL、CHI和Interspeech等众多顶会之中。
此外,谷歌还联合33个学术实验室,通过汇总来自22种不同机器人类型的数据,创建了Open X-Embodiment数据集和RT-X模型。
谷歌在MLCommons标准组织的支持下,带头在行业内推动AI安全基准的建立,参与者包括 OpenAI、Anthropic、Microsoft、Meta、Hugging Face等在生成式AI领域举足轻重的机构。
随着多模态模型(multimodal models)的不断进步,它们将助力人类在科学、教育乃全新的知识领域取得惊人的成就。
随着时间的推进,谷歌的产品和研究也不断进步,而人们也将会找到更多富有创意的AI应用方式。
在这篇年终总结的最后,让我们回到开头的话题,正如谷歌在「Why We Focus on AI (and to what end)」中所言:
「如果大胆而负责地推进AI的发展,我们相信AI能够成为一项基础技术,彻底改变全世界人的生活——这正是我们追求的目标,也是我们的激情所在!」

参考资料:
https://blog.research.google/2023/12/2023-year-of-groundbreaking-advances-in.html
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
