# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
王鑫涛,复旦大学博士生,师从肖仰华、汪卫教授,致力于探索用AI创造具有人格的数字生命。
研究方向聚焦大语言模型与Agent技术,在AI角色扮演领域发表多篇ACL/EMNLP论文,以及该领域首篇研究综述,总计引用量三百余次。
他的研究寻求AI技术与人类情感需求的结合。科研之外,他是一位二次元爱好者、业余Coser。该研究完成于他在阶跃星辰实习期间,指导者为王亨老师。

角色扮演 AI(Role-Playing Language Agents,RPLAs)作为大语言模型(LLM)的重要应用,近年来获得了广泛关注。
无论是用于情感陪伴、故事创作、游戏中的 AI 角色,还是真人的数字分身,都需要模型能够准确捕捉和模拟特定角色的设定、个性和行为模式。
特别是当扮演小说、动漫中的知名角色时,模型需要获取并利用关于这些角色的大量知识。
然而,现有的角色扮演 AI 面临两大核心挑战:缺乏高质量的真实角色数据集,以及缺少有效的评估方法。
为解决这些问题,复旦大学和阶跃星辰合作发表了一篇工作,CoSER(Coordinating LLM-Based Persona Simulation of Established Roles),
一个包含当下最大的真实数据集、SoTA 开源模型和最深入的评估方法的完整框架,用于高效构建和评估角色扮演 AI。
本文的代码、数据集和模型已在 Github 和 Huggingface 上开源,用于促进角色扮演 AI 在研究和应用中的发展。

从世界最知名的 771 本书中,本文构建了 CoSER Dataset,迄今为止最大、最真实、最丰富的角色扮演数据集,包含:
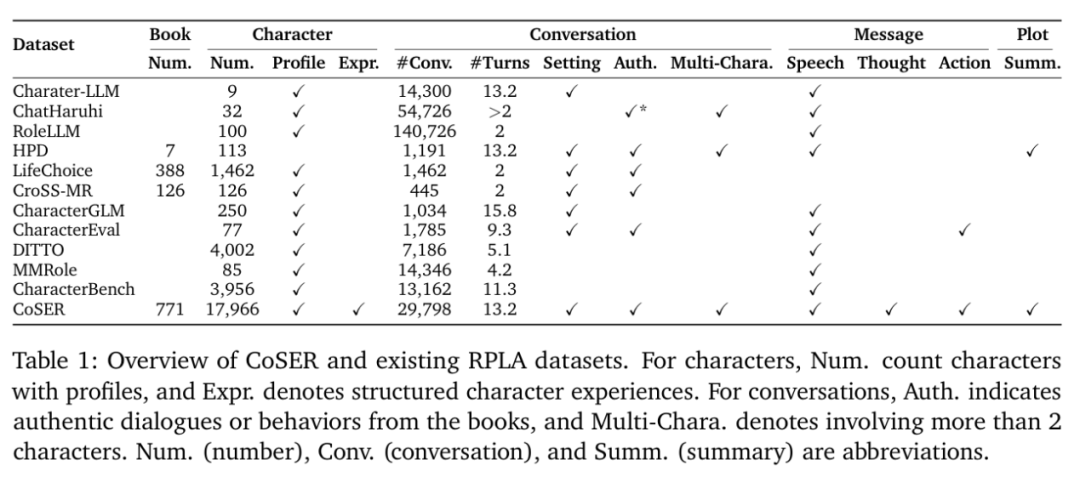
上图将 CoSER Dataset 与之前的数据集进行了比较。概括来说,CoSER 的独特之处在于:
1. 真实性:不同于此前数据集中大量使用的 LLM 生成的角色问答对,CoSER 数据集从经典文学作品中提取真实角色对话,
在忠实刻画角色的同时,保留了真实对话的复杂性,是天然的多轮、多角色的优质对话数据。
2. 全面性:CoSER 数据集不仅包含角色概述和对话,还包括剧情摘要、角色经历和对话背景等丰富内容。
详细的对话背景在角色扮演的训练和评估中非常重要,而剧情摘要、角色经历提供了更丰富的角色知识。
3. 多维表达:对话内容涵盖语言(speech)、动作(action)和想法(thought)三个维度,使角色表现更为立体。
其中,想法数据能帮助模型在训练中更好地理解角色的行为和语言。
4. 环境作为特殊角色:将环境视为特殊角色,扩展了角色对话能表达的信息,使对话数据可以表示书中的环境反馈、大众角色反应等信息。
Given-Circumstance Acting
角色扮演的训练与评估方法
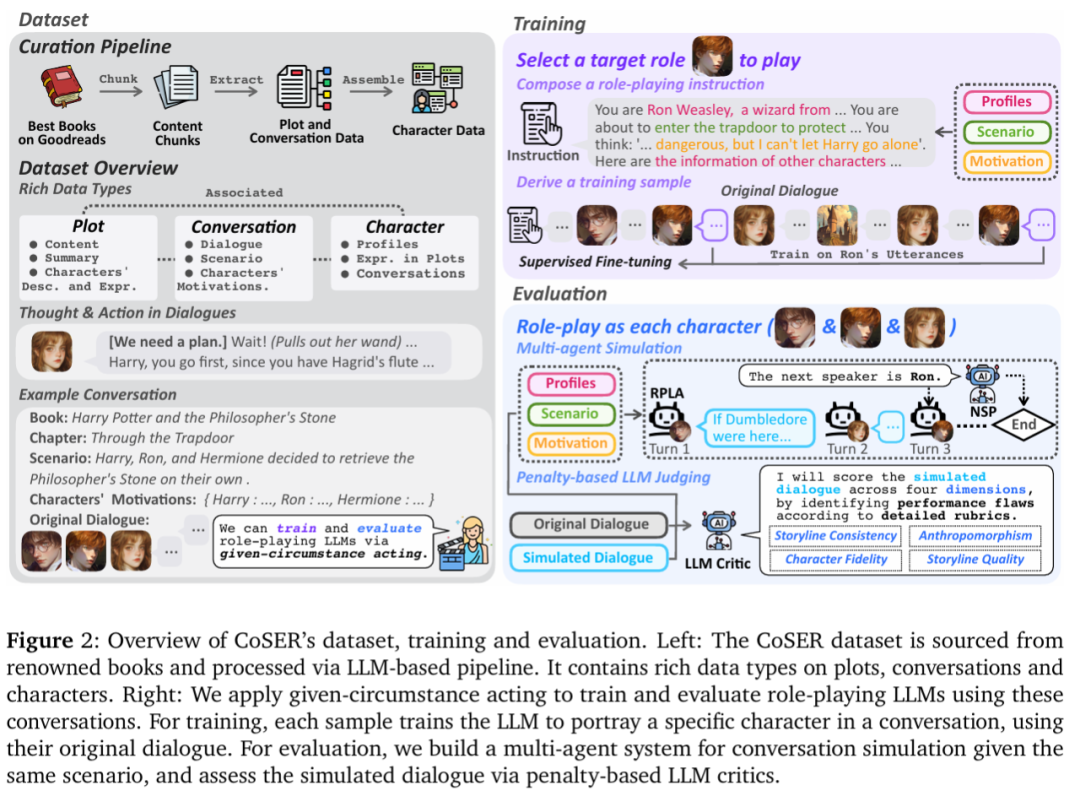
本文引入了给定情境表演(Given-Circumstance Acting,GCA)方法用于训练和评估 LLM 的角色扮演能力,
这一方法受到了《演员的自我修养》的作者 - 斯坦尼斯拉夫斯基 - 的表演理论的启发。
在训练阶段,给定一段对话及其上下文情景,本文让模型每次扮演对话中的一个角色,并在相应的台词上进行训练。
基于这一方法,本文训练了 CoSER 8B 和 CoSER 70B 两个模型,它们基于 LLaMA-3.1 构建,展现了真实、生动的角色表现能力,
并在多项角色扮演评估上取得 SoTA 成绩。
在评估阶段,GCA 评估由两个步骤组成:
1. 多智能体模拟(Multi-agent Simulation):
构建一个多智能体系统,让被评估模型依次扮演不同角色,在给定情境下进行模拟,获得一段由多个角色 AI 交互生成的对话。
2. 基于惩罚的 LLM 评判(Penalty-based LLM Juding):
让 LLM 扮演评判者,使用详细评分标准(rubrics)和原始对话作为参考,按照 “采点扣分制” 识别明确的表演缺陷来评估模拟对话的质量。
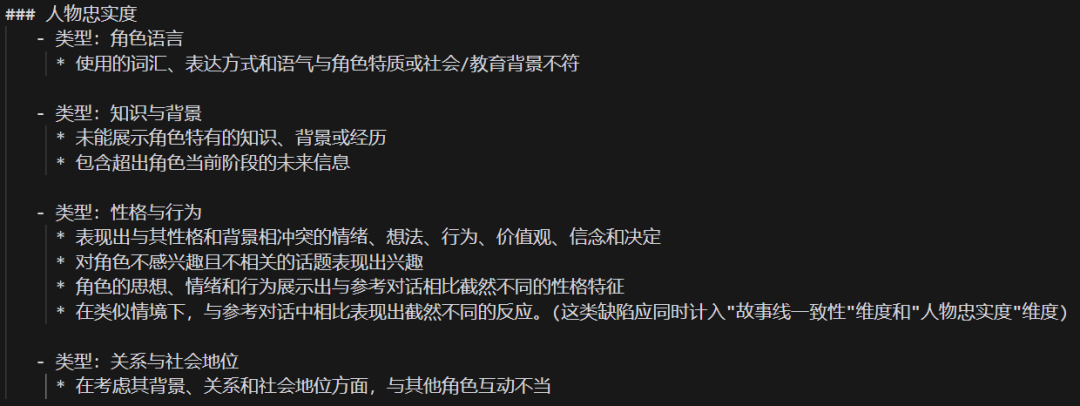
下图展示了 “人物忠实度” 维度的扣分标准:
本文将评估维度按照 1. 关注自身质量 or 关注忠于原作;2. 关注单一角色 or 关注整体模拟,分成了以下四个维度。
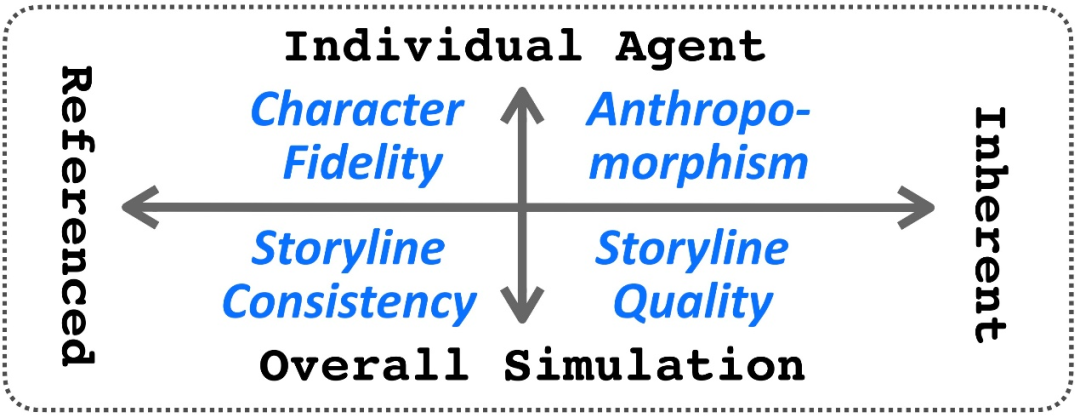
GCA 评估方法的优势在于:1. 通过多智能体模拟,全面反映模型的多轮、多角色的扮演能力;
2. 基于原著中的真实对话作为 Groundtruth,并提供专家级评分标准指导 LLM 评判者。
关键实验与结论
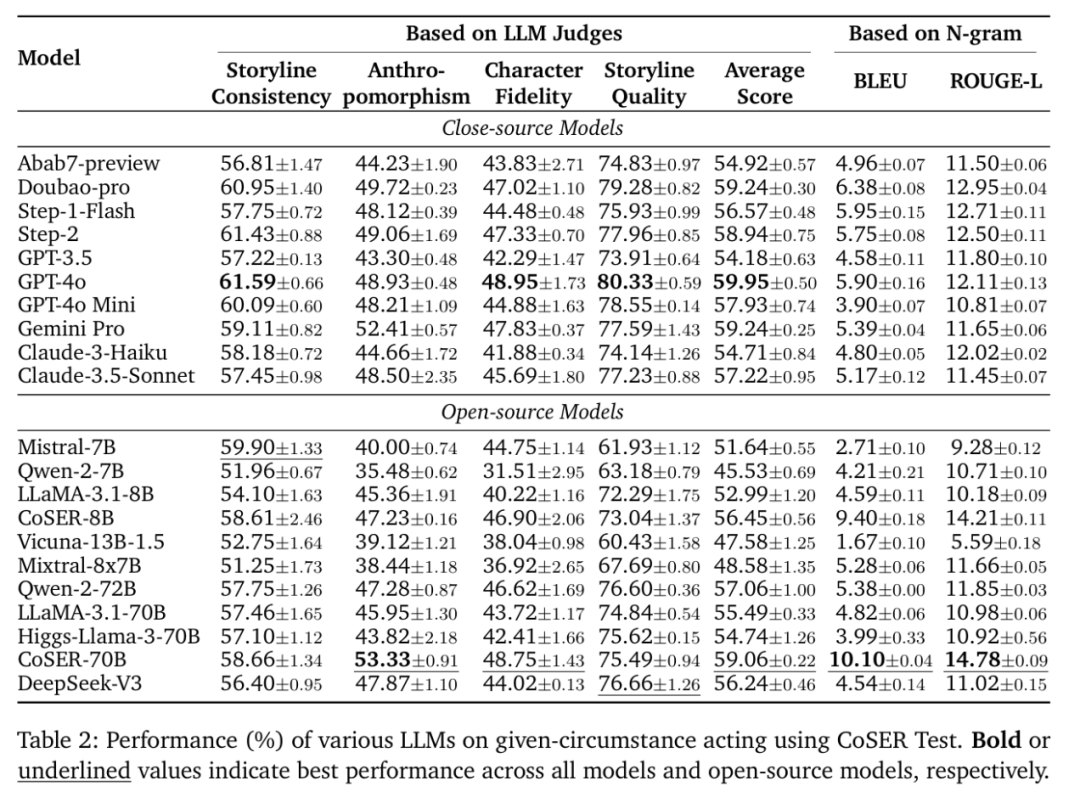
在本文提出的 GCA 评估中,CoSER-70B、GPT-4o、Step-2、Doubao-pro 取得了最好的表现,其中,CoSER-70B 的表现远超其他开源模型。
进一步,本文在实验中还汇报了 BLEU、ROUGE-L 等指标来比较模型生成对话与 Groundtruth 对话的一致性,在这一指标上 CoSER-70B 超过了所有的现有模型。
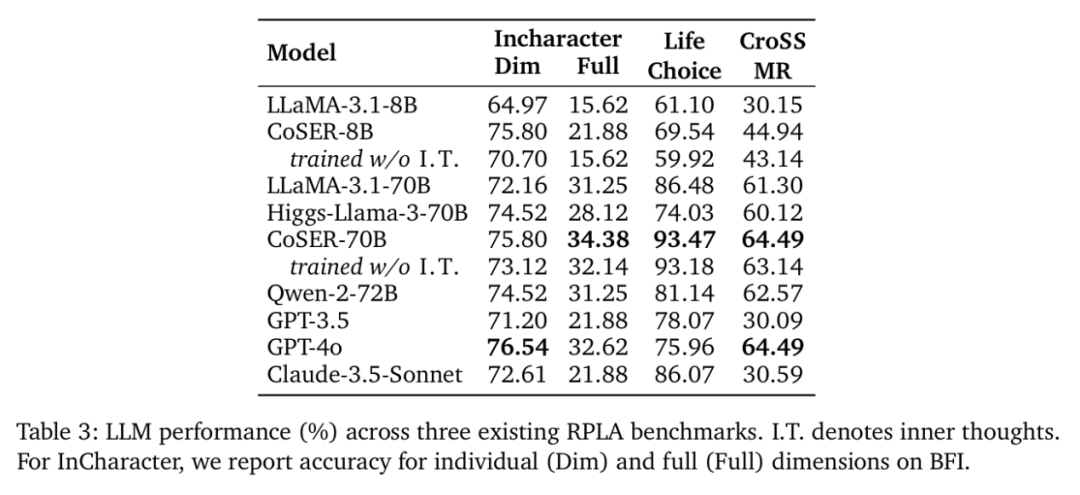
在 InCharacter、LifeChoice 等基于分类和多选题的角色扮演基准测试上,CoSER 模型也取得了优秀的表现。
其中,CoSER-70B 在 InCharacter 和 LifeChoice 基准测试上分别达到了 75.80% 和 93.47% 的准确率,超越或匹配 GPT-4o。
在论文中,作者还进行了其他实验,证明了想法数据在训练 / 推理阶段的重要性、
将 CoSER 数据用于检索增强(RAG)的有效性等结论,感兴趣的读者可以在论文原文中找到相应的实验。
Case Study
最后,下图列出了 CoSER 测试集中的一个例子(出自《权力的游戏》),包括其中的对话场景、Groundtruth 对话及 CoSER-70B 生成的结果。
在这个例子中,我们看到,CoSER-70B 不仅将角色的背景、性格模仿得活灵活现,
还用上了原作的角色的经典台词(不在数据中出现),体现了 CoSER 模型在扮演小说角色时的优秀表现。


文章来自于微信公众号 “机器之心”,作者 :王鑫涛




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
