# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,代码评测集数量激增,但质量参差不齐。为规范其开发,香港科技大学联合多所高校研究了过去十年的274个代码评测集,发现诸多问题,如数据重复、测试用例错误、隐私信息未删除等。基于此,他们推出了《代码评测集发展指南55项》(How2Bench),涵盖设计、构建、评测、分析、发布五大阶段,旨在提升代码评测集的质量与可靠性。
近年来,大模型层出不穷,令人目不暇接。为更好理解大模型的能力,许多评测集(Benchmarks)应运而生。
然而,这些评测集的质量常常受到质疑:标准答案出错、指令模糊或错误、题目重复、数据泄漏等。
那么,代码评测集的现状究竟如何?
为了回答这个问题,由香港科技大学牵头,联合香港中文大学、中山大学等多所机构,耗费近一年时间,深入调研了过去10年间的274个代码评测集,推出了一份《代码评测集发展指南55项》(英文名:How2Bench,下称《指南》)。

论文链接:https://arxiv.org/pdf/2501.10711
该指南涵盖代码评测集设计、构建、评测、分析、发布五大阶段,共包含55条检查项。
研究团队指出,代码评测集的质量不容乐观:
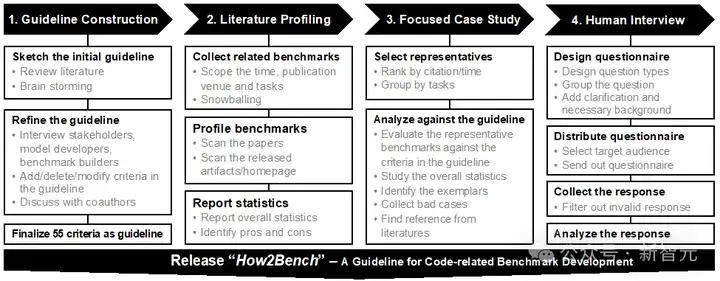
图1 研究过程大纲
研究团队将研究过程分为四个步骤:指南构建、文献综述、焦点案例分析、问卷调查。
研究团队将代码评测集的开发过程分为五个阶段(如图2):设计、构建、测评、分析、发布。
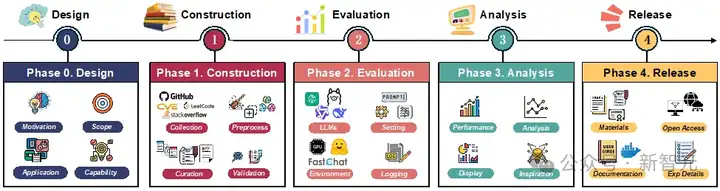
图2 代码基准开发的生命周期
研究团队可视化了所深入研究的274个代码评测集,展示了它们的时间分布(图3)、引用量分布(图4)、代码任务分布(图5)等。
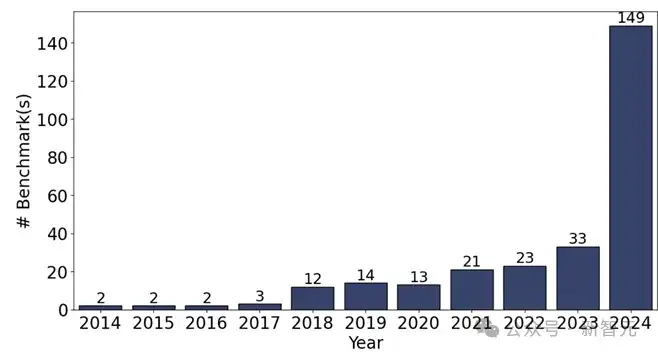
图3 代码评测集时间分布
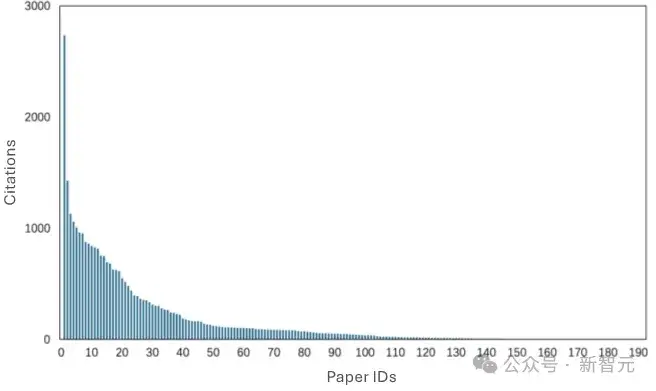
图4 代码评测集引用量分布
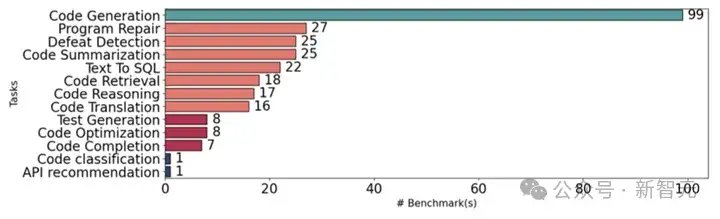
图5 代码任务分布图
研究团队还对代码评测集的继承关系进行分析。如图6所示,HumanEval、MBPP、Spider、CodeSearchNet被下游代码评测集继承得较为频繁。
另外,值得注意的是,18%的代码评测集(50/274)被后续评测集继承、扩展。这也意味着上游代码评测集的质量不仅影响自身的评估可靠性,还将持续影响下游代码评测集。
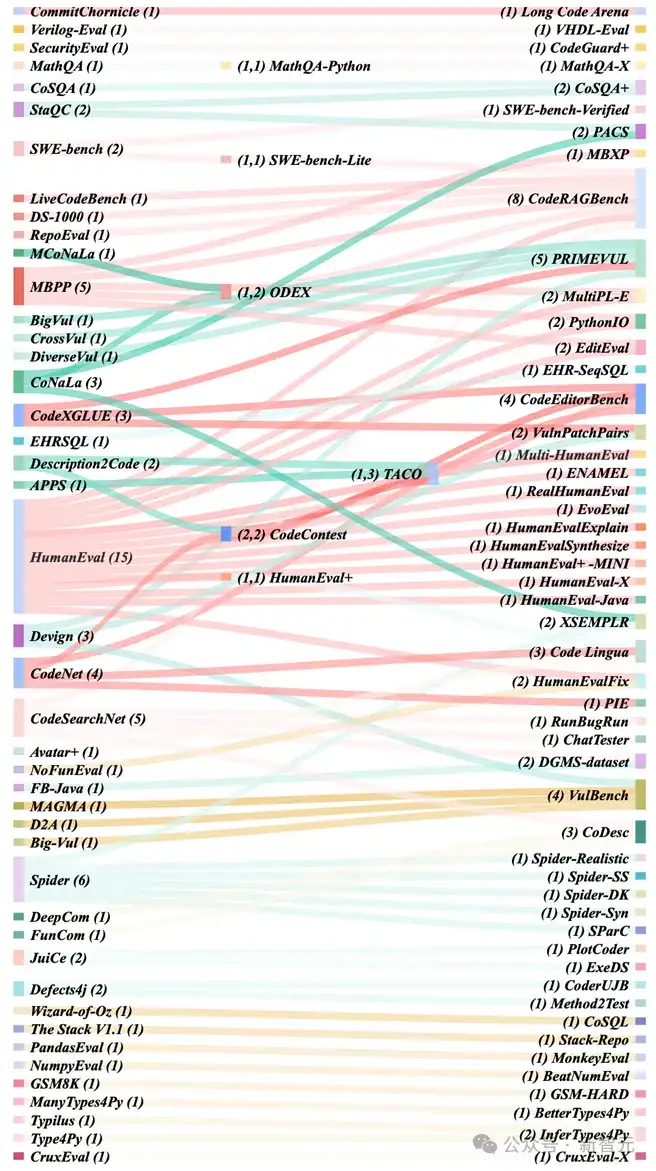
图6 代码评测集之间的继承关系
针对「设计」阶段,研究团队提出了4条检查项。《指南》指出,在构建之前,从业者应先做好调研,以确保提出新的评测集的必要性和重要性(如,是否已存在大量相似的评测集);明确定义评测集所评估的模型能力范围(如,评测的是代码续写能力、理解能力,或是其他);思考清楚待评估的能力是否符合真实应用场景(如,输入是否符合实际;输出形式是否真的为实际应用场景所需)。

综述发现,现有的代码评测集偏科严重:
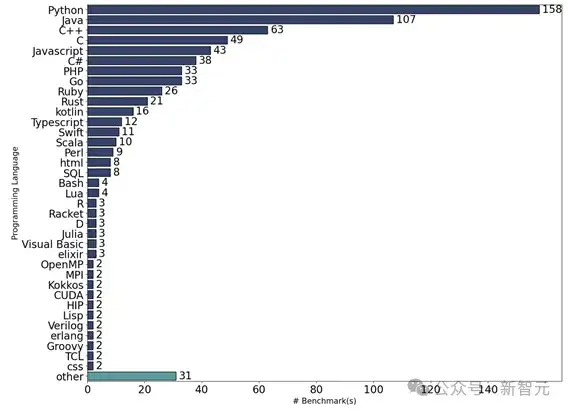
图7 编程语言分布
研究团队指出,在焦点研究的评测集中,10%的评测集没有写明所评估的模型能力,或出现预期评估的能力与实际评估的能力不相符的例子。
例如,被广泛使用的MBPP(Most-basic Python Problems)致力于评估评估模型最基础的Python 编程能力(measure the ability of these models to synthesize short Python programs from natural language descriptions),然而,其中有一道题是实现一个狗的年龄与人类年龄的对照转换(如图8)。

图8 所评估能力与实际评估能力不符的例子
研究团队对代码评测集「构建」阶段提出了19条检查项。《指南》指出,从数据收集、清洗、降噪、去重,质量审查(如人工筛查、代码运行)、数据污染缓解,到最后构建完整输入输出对、匹配评估方案(oracle)等,都要尽量做到「有迹可循、有记录可查、有质量保障,构建过程公开、透明、可复现」等规范,保证代码评测集构建的可靠性。

综述发现,现有的代码评测集构建过程「质量堪忧」:
在构建评测集时,确保数据质量至关重要。
然而,研究团队展示的统计数据(如图9)令人失望:67.9% 的评测集没有采取任何数据质量保证措施。
在做了质量保障的代码评测集中,人工检查占多数(22.6%);代码执行仅占2.2%;使用大模型进行验证占1.5%;其他方法还包括:代码仓库下载量、点赞数等。
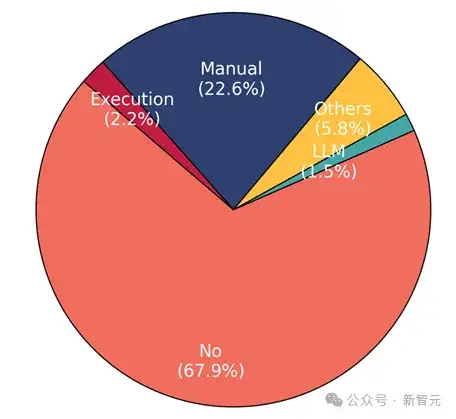
图9 数据质量保障方式分布
研究团队在文中给出了一些反例,例如评测集中存在重复问题(如图10)、标准答案不正确(如图11)、测试数据错误(如图12)等。

图10 数据重复的例子(id为71的题目和id为141的题目重复)

图11 标准答案不可运行的例子(函数swap 未定义)

图12 测试用例错误的例子(第7、8行预期输出应为2)
研究团队对代码评测集「评估」阶段提出了12条检查项。《指南》指出,实验设计应具有代表性和完整性;实验过程要记录,以提高可复现性;评估过程中应考虑偶然因素(如大模型所天然具有的随机性)对实验结果带来的风险,并尽量避免。
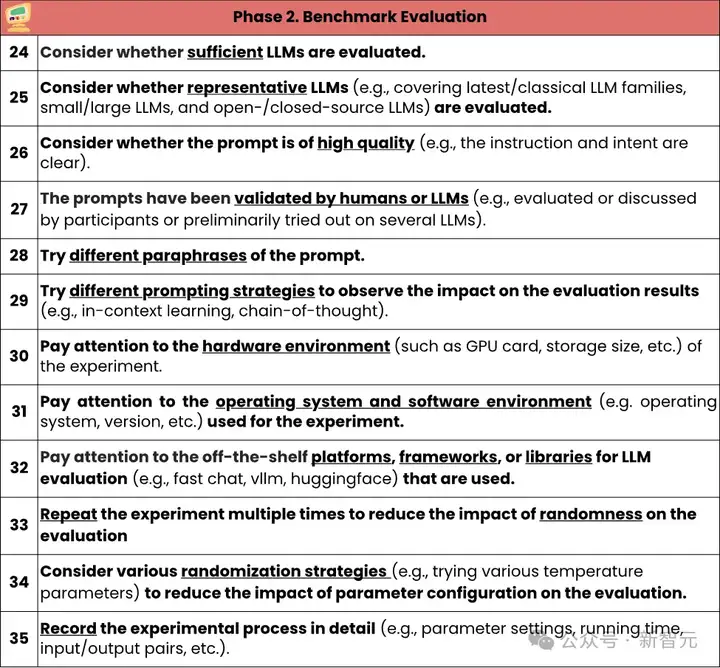
研究团队先将代码评测集中针对大模型的评测集筛选出来(67%=183/274),对这部分评测集的评估过程进行统计。
经过观察,研究团队指出,在代码评测集的评估阶段,主要存在的问题包括:评估过程不透明,评估存在随机性,且可复现性堪忧:
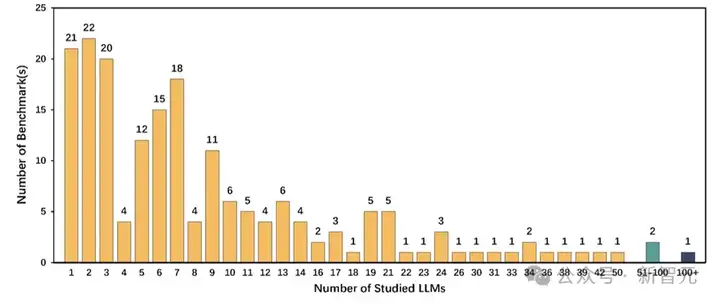
图13 评估阶段评测的大模型数量分布
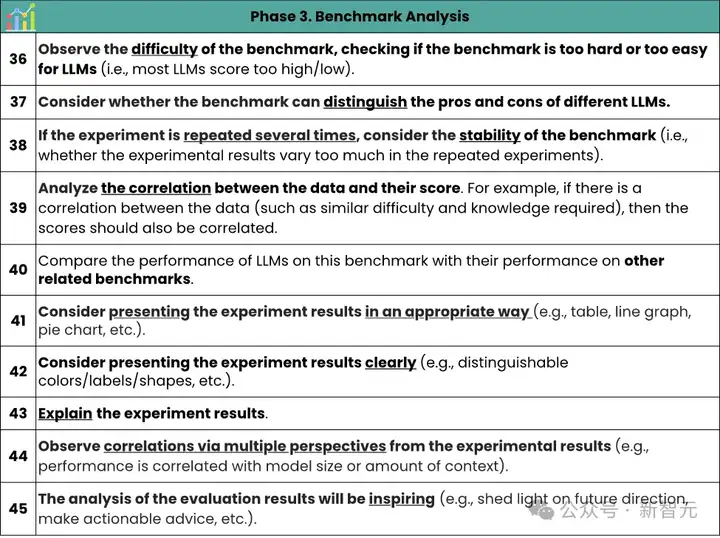
研究团队对代码评测集「分析」阶段提出了10条检查项。《指南》指出,分析实验结果时应尽可能考虑多角度、多维度。
借鉴经典度量学理论中的评估指标,综合考虑代码评测集的难度(评测集是否过于简单以至于模型表现过好,或过于困难以至于所有模型均一筹莫展)、区分度(评测集应能区分不同模型的能力)、稳定性等。还可以横向对比同类代码评测集在其他编程语言、相关任务、上下游任务中的表现,分析其是否具有相关性。
最后,在实验分析展示阶段,图示尽量恰当(如,用折线图表示趋势、柱状图表示数值对比、饼状图表示比例等),数字尽量清晰。
研究团队经过对焦点案例的深入分析指出,30%代码评测集在分析实验数据时未能对实验结果进行分析,并提供合理解释;存在实验结果图示中数字不可分辨(如图14)等情况。
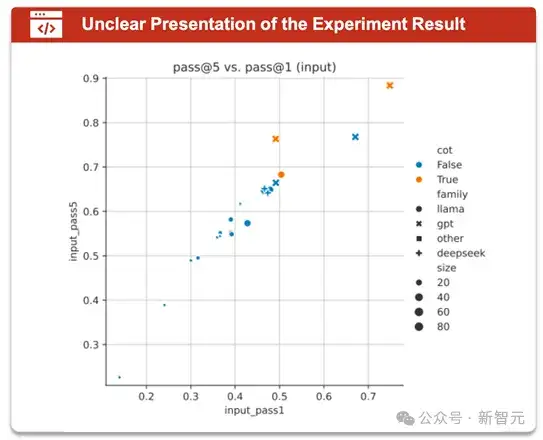
图14 实验结果图示中数字不可分辨的例子
研究团队对代码评测集「发布」阶段提出了10条检查项。《指南》指出,代码评测集发布时,应设置好许可证(license)以明确使用权限及方式;提供评测所需的完整素材,包括评测数据、评估方式(如测试用例)、运行环境(如docker)、可运行代码或代码实例等;准备使用文档,以提高用户友好性;提供评测运行时日志,以提高评测的可靠性与透明性,便于其他从业人员使用。
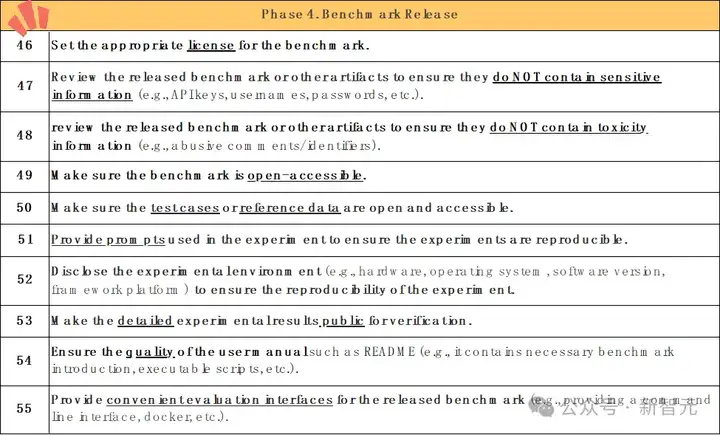
研究团队发现,近20%的代码评测集没有设置许可证,这使得代码数据的权限不清晰;超过半数的评测集不提供可复现的提示词,阻碍可复现性。
团队还指出,在公布的代码评测集中要注意删除隐私、敏感信息(如API密钥、个人邮箱、密码等),避免隐私泄漏(如图15)。

图15 包含隐私信息的例子(包含API key)
最后,研究团队进行了问卷调查,共发出50份问卷,其中49份有效。
团队要求受访者:(1)来自于AI或软件工程(SE)领域,且(2)至少正式发表过一篇论文。其中,有近一半的受访者曾参与构建过代码评测集。
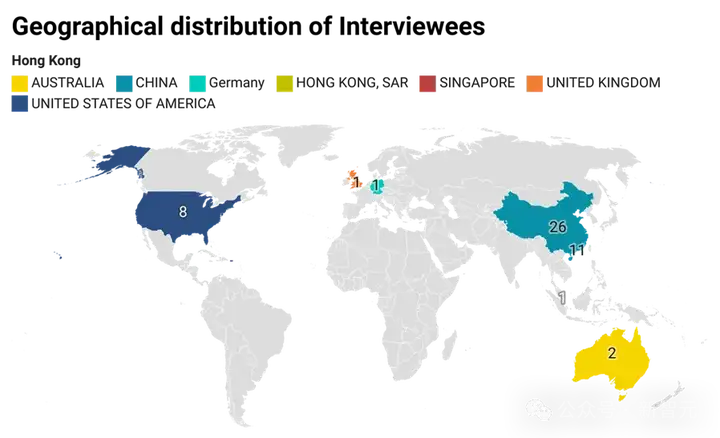
图16 受访者的地区分布
首先,所有受访者都同意「一份评测集构建指南对代码评测集的构建能起到很大帮助」;《指南》中85%(47/55)的检查项都得到超八成受访者的认同。
有趣的事,凡是曾经参与过代码评测集构建的受访者,对检查项的认可度都非常高,55条中有53条得到了所有参与过评测集构建的受访者的认同。
然而,研究团队也从问卷调查中,识别到从业者意识上的不足:
受访者意识上的「缺失」正好解释了研究团队在综述中的观察——数据质量堪忧、可复现性差、公开透明性差。
最后,研究团队将综述及指南整理成一份40页的研究论文,并附上完整的《指南》,希望能唤起大模型从业者对代码评测集质量的注意,对评测集可靠性、可复现性的重视。
该研究做出了如下贡献:
指南的第一作者是香港科技大学的研究助理教授曹嘉伦,主要研究领域包括AI&SE、人工智能测试、形式化验证等。其余作者包括香港科技大学博士后王文轩,副教授王帅,教授张成志;香港中文大学本科生陈昱杰,凌子轩,博士生李树青、王朝正,教授吕荣聪;香港中文大学(深圳)博士生余博西,助理教授贺品嘉;中山大学副教授刘名威,教授郑子彬等。
参考资料:
https://arxiv.org/pdf/2501.10711
文章来自于“新智元”,作者“LRST”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
