

AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
来自主题: AI技术研报
9213 点击 2025-11-28 09:28
基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。

近年来,代码评测集数量激增,但质量参差不齐。为规范其开发,香港科技大学联合多所高校研究了过去十年的274个代码评测集,发现诸多问题,如数据重复、测试用例错误、隐私信息未删除等。基于此,他们推出了《代码评测集发展指南55项》(How2Bench),涵盖设计、构建、评测、分析、发布五大阶段,旨在提升代码评测集的质量与可靠性。

多年来,浙江大学周晟老师团队与阿里安全交互内容安全团队持续开展产学研合作。近日,双⽅针对标签噪声下图神经⽹络的联合研究成果《NoisyGL:标签噪声下图神经网络的综合基准》被 NeurIPS Datasets and Benchmarks Track 2024 收录。本次 NeurIPS D&B Track 共收到 1820 篇投稿,录⽤率为 25.3%。
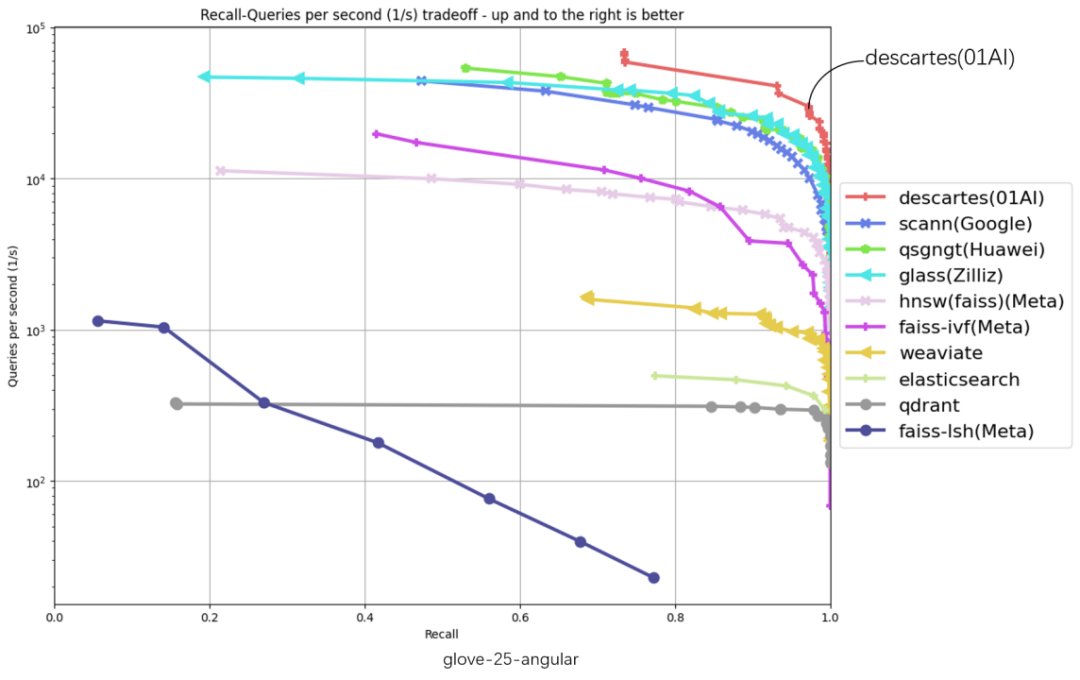
3 月 11 日,零一万物宣布推出基于全导航图的新型向量数据库 「笛卡尔(Descartes)」,已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。