# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——
共计收集和整理了涉及8500+个LLM,在12个Benchmark上的共2亿条性能记录!

先来简单科普一下路由LLM。
这种方法主要是把像ChatGPT、Qwen、DeepSeek这些成型的LLM当作 “专家” ,当给一个输入的时候,有分类能力的Router(路由器)就会把这个输入分配给合适的LLM处理。
如此一来,就能实现高性能、低计算消耗、低幻觉等目标。
而来自中山大学和普渡大学的研究人员在基于上述海量的记录做了一番探索之后,发现了一个现象,叫做Model-level Scaling Up。
一言蔽之,就是一个好的Router,可以让路由LLM范式的性能随着LLM候选数量的增加迅速变强。
随后,他们通过这些数据构建了针对Router设计的评测RouterEval。
值得注意的是,其他研究人员,也可以通过RouterEval在很少的计算资源下(如笔记本、单卡GPU上)就能参与到该路由LLM的研究当中。
当大多数研究人员和开发者第一次听到Mixture-of-Expert (MoE) 的时候,可能第一反应不是现在常见的对结构中的FFN层进行扩展,以FFN层作为”expert”。
而是直接将每一个成型的LLM,比如ChatGPT、Qwen、DeepSeek等直接看做是”expert”。
实际上,这种范式也称为路由LLM(Routing LLMs)。

简单地说,就是给定一个输入input,一个具有一定分类能力的Router (路由器)会将input分配给指定的LLM进行处理,以达到高性能、低计算消耗或者是低幻觉等各种各样的目标,或组合目标。
这类问题可以被认为是分类问题、推荐系统问题、Agent规划甚至是检索问题(注意,不是检索数据for LLM,而是检索LLM for 数据)。
一些典型的例子有:
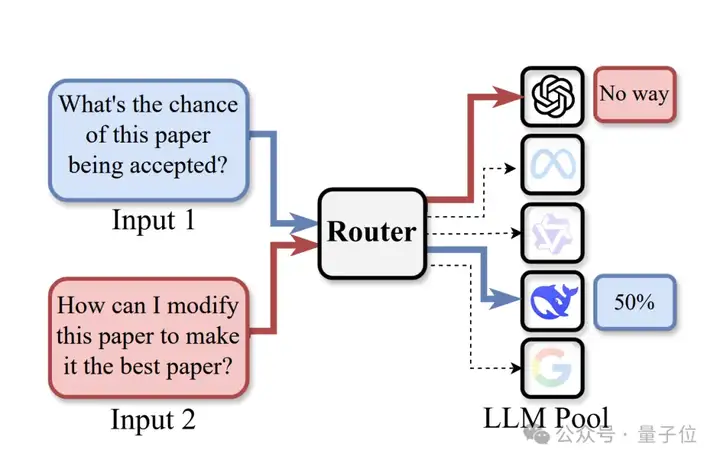
△路由LLM (Routing LLMs)示意图
路由LLM具有很高的应用潜力和兼容性,不同LLM都可以被添加到LLM候选Pool中参与routing(包括异构LLM,各种tuning/pretraining方法下得到的LLM,等等),而且可以发挥很强的性能。
比如最近UCB提出的Prompt-to-Leaderboard以很低的训练成本,以路由LLM的范式下实现和需要数十万个GPU训练得到的Grok3相当的性能,并登上Arena排行榜第一。
然而当前路由LLM领域仍然存在一些挑战影响了Router的发展:
于是,研究团队收集并整理且开源了涉及8567个不同LLMs在12个evaluations下2亿条性能记录,并通过这些记录发现:
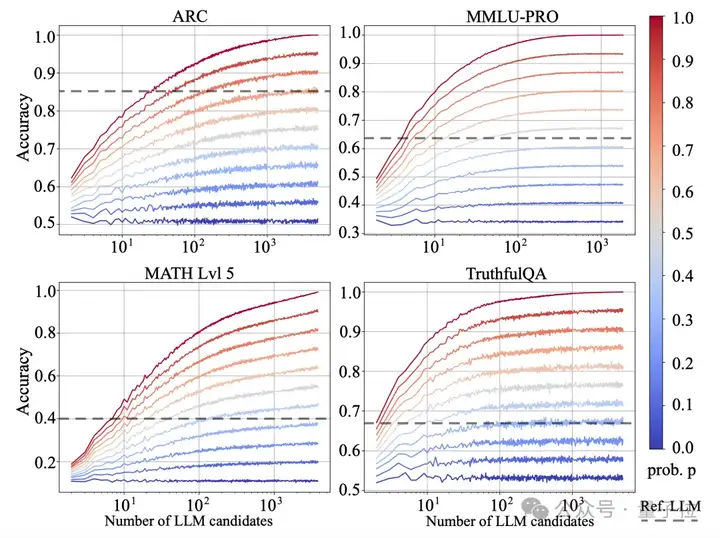
△Model-level Scaling Up现象示意图
利用2亿条性能记录,可以构建完美Router,即oracle Router ro:

接着,根据上式可以构建不同性能的Router ro(p),其中wm为随机Router,当p→1时,Router ro(p)越解决上界分类性能,当p→0时,ro(p)越接近随机Router。
从上图结果来看,随着LLM候选的数量增加,不同的evaluation在具有一定能力的Router下呈现了Scaling Up现象。
而性能一般的Router,比如随机Router则几乎没有Scaling Up现象。
且快速超过参考模型Ref. LLM的性能(参考模型一般是GPT4)。
另外团队还可以发现两个有趣的现象:
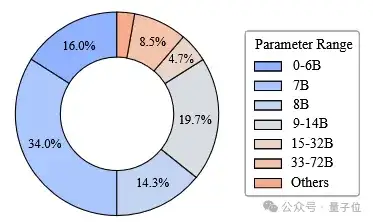
RouterEval涉及的LLM的参数分布
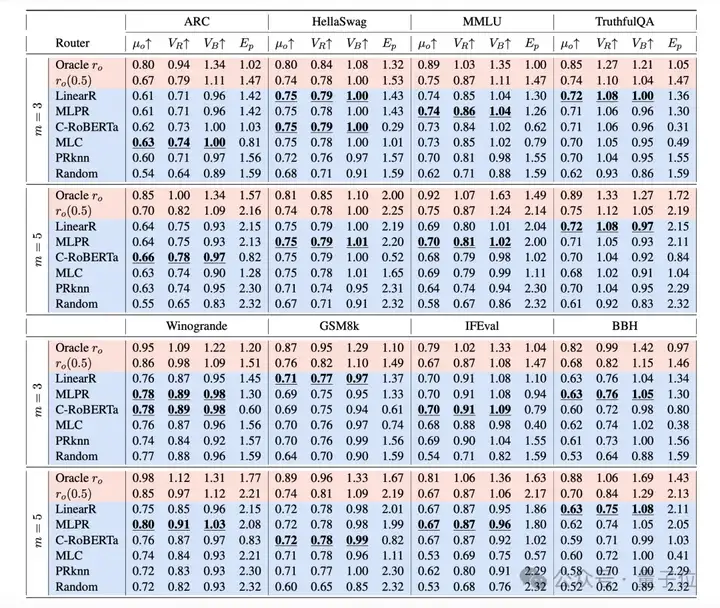
通过测试当前的已有的Routers的性能,可以发现现在Router仍然有很大的提升空间。
不过幸运的是,RouterEval进行的Router设计的实验不需要大量的计算资源,且可以融入不同的已有技术,包括few-show learning,数据增强、推荐系统、正则化方法、预训练模型、额外数据等等.
因此Router将有希望快速得到实质性改进。
以及,和当前一些其他范式的区别和关系如下:

当然,研究团队也提出一些未来的挑战。
首先就是缺乏数据。
要获得足够好的Router,当然的数据仍然远远不够,因为这些性能记录的数据一般不开源,且掌握在大公司手中,这需要全社区的共同努力。目前也可以通过算法一定程度缓解数据缺乏的问题。
其次是如何保持在多LLM候选情况下的Router性能的问题。
当LLM候选越多的时候,意味着Router要进行更多类的分类,这对于Router的训练来说具有很高的挑战性;
除此之外,还包括RouterEval目前只关注在性能。
尽管routing llm可以考虑计算消耗、幻觉等其他目标。但是目前性能的水平还远远不够,如果现在就过度关注其他目标的话,可能言辞尚早。另外,计算消耗和幻觉等目标的数据不容易搜集,可能采集不到足够多的LLM的记录数据,仍然需要全社区的努力。
最后,就是部署的难度。
即使足够强的Router可以获得,但是此时LLM候选的部署可能是新的瓶颈,这在计算机系统等领域中也有很多的研究角度,如计算负载,高效分配、动态模型激活等。幸运的是,从论文的观察来看,3-10个LLM已经能得到出色的结果。
GitHub和论文等地址放下面了,感兴趣的小伙伴可以深入研究一下哦~
代码地址:
https://github.com/MilkThink-Lab/RouterEval
论文地址:
https://arxiv.org/abs/2503.10657
论文合集:
https://github.com/MilkThink-Lab/Awesome-Routing-LLMs
文章来自于“量子位”,作者“MilkThink团队”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
