# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在Transformer占据多模态工具半壁江山的时代,大核CNN又“杀了回来”,成为了一匹新的黑马。
腾讯AI实验室与港中文联合团队提出了一种新的CNN架构,图像识别精度和速度都超过了Transformer架构模型。
切换到点云、音频、视频等其他模态,也无需改变模型结构,简单预处理即可接近甚至超越SOTA。

团队提出了专门用于大核CNN架构设计的四条guideline和一种名为UniRepLKNet的强力backbone。
只要用ImageNet-22K对其进行预训练,精度和速度就都能成为SOTA——
ImageNet达到88%,COCO达到56.4 box AP,ADE20K达到55.6 mIoU,实际测速优势很大。
在时序预测的超大数据上使用UniRepLKNet,也能达到最佳水平——
例如在全球气温和风速预测上,它就超越了Nature子刊上基于Transformer的前SOTA。
更多细节,我们接着看作者投稿。
在正式介绍UniRepLKNet的原理之前,作者首先解答了两个问题。
第一个问题是,为什么在Transformer大一统各个模态的时代还要研究CNN?
作者认为,Transformer和CNN只不过是相互交融的两种结构设计思路罢了,没有理由认为前者具有本质的优越性。
“Transformer大一统各个模态”正是研究团队试图修正的认知。
正如2022年初ConvNeXt、RepLKNet和另外一些工作问世之前,“Transformer在图像任务上吊打CNN”是主流认知。
这几项成果出现后,这一认知被修正为“CNN和Transformer在图像任务上差不多”。
本研究团队的成果将其进一步修正:在点云、音频、视频上,CNN比我们想象的强太多了。
在时序预测这种并不是CNN传统强项的领域(LSTM等曾是主流,最近两年Transformer越来越多),CNN都能超过Transformer,成功将其“偷家”。
因此,研究团队认为,CNN在大一统这一点上可能不弱于Transformer。

第二个问题是,如何将一个为图像任务设计的CNN用于音频、视频、点云、时序数据?
出于对简洁和通用性的永恒追求,将UniRepLKNet用于其他模态时,不对模型架构主体做任何改变(以下实验用的全都是UniRepLKNet-Small)。
只需要将视频、音频、点云、时序数据给处理成C×H×W的embedding map(对于图像来说,C=3),就能实现到其他模态的过渡,例如:
后文展示的结果将会证明,如此简单的设计产生的效果是极为优秀的。
2022年,RepLKNet提出了用超大卷积核(从13×13到31×31)来构建现代CNN以及正确使用超大卷积核的几个设计原则。
但从架构层面看,RepLKNet只是简单地用了Swin Transformer的整体架构,并没有做什么改动。
当前大核CNN架构设计要么遵循现有的CNN设计原则,要么遵循现有的Transformer设计原则。
在传统的卷积网络架构设计中,当研究者向网络中添加一个3×3或5×5卷积层时,往往会期望它同时产生三个作用:
那么,设计大卷积核CNN架构时,应该遵循怎样的原则呢?
本文指出,应该解耦上述三种要素,需要什么效果就用对应的结构来实现:
这样的解耦之所以能够实现,正是大卷积核的本质优势所保证的,即不依赖深度堆叠的大感受野。
经过系统研究,本文提出了大卷积核CNN设计的四条Architectural Guidelines。
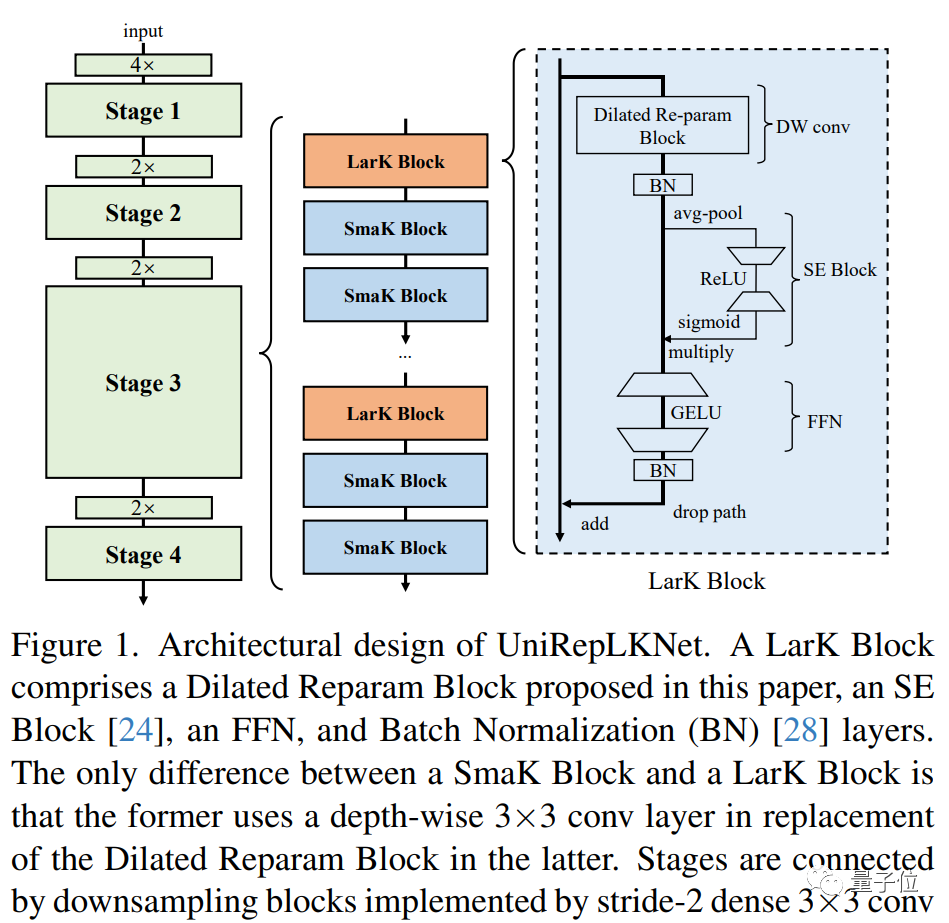
根据这些guideline,本文提出的UniRepLKNet模型结构如下——
每个block主要由depthwise conv、SE Block和FFN三个部分组成。
其中depthwise conv可以是大卷积核(图中所示的Dilated Reparam Block,其使用膨胀卷积来辅助大核卷积来捕捉稀疏的特征而且可以通过结构重参数化方法等价转换为一个卷积层),也可以只是depthwise 3x3。
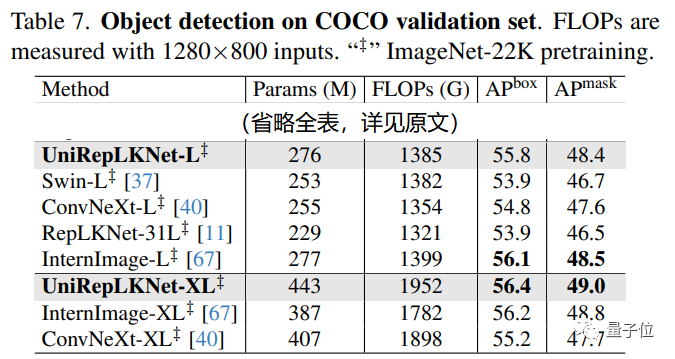
作为图像模态中的老三样,ImageNet、COCO、ADE20K上的结果自然是不能少。论文中最多只用ImageNet-22K预训练,没有用更大的数据。
虽然大核CNN本来不是很重视ImageNet(因为图像分类任务对表征能力和感受野的要求不高,发挥不出大kernel的潜力),但UniRepLKNet还是超过了最新的诸多模型,其实际测速的结果尤为喜人。
例如,UniRepLKNet-XL的ImageNet精度达到88%,而且实际速度是DeiT III-L的三倍。量级较小的UniRepLKNet相对于FastViT等专门设计的轻量级模型的优势也非常明显。

在COCO目标检测任务上,UniRepLKNet最强大的竞争者是InternImage:
UniRepLKNet-L在COCO上不及InternImage-L,但是UniRepLKnet-XL超过了InternImage-XL。
考虑到InternImage团队在目标检测领域的积淀非常深厚,这一效果也算很不容易了。
在ADE20K语义分割上,UniRepLKNet的优势相当显著,最高达到55.6的mIoU。与ConvNeXt-XL相比超出了整整1.6。

为了验证UniRepLKNet处理时序数据的能力,本文挑战了一个数据规模超大的《Nature》级别的任务:全球气温和风速预测。
尽管UniRepLKNet本来是为面向图像任务设计的,它却能超过为这个任务而设计的CorrFormer(前SOTA)。

这一发现尤为有趣,因为这种超大规模时间序列预测任务听起来更适合LSTM、GNN和Transformer,这次CNN却将其“偷家”了。
在音频、视频和点云任务上,本文的极简处理方法也都十分有效。
除了提出一种在图像上非常强力的backbone之外,本文所报告的这些发现似乎表明,大核CNN的潜力还没有得到完全开发。
即便在Transformer的理论强项——“大一统建模能力”上,大核CNN也比我们所想象的更为强大。
本文也报告了相关的证据:将kernel size从13减为11,这四个模态上的性能都发生了显著降低。
此外,作者已经放出了所有代码,并将所有模型和实验脚本开源。
论文地址:
https://arxiv.org/abs/2311.15599



