
NeurIPS 2025最佳论文开奖!何恺明、孙剑等十年经典之作夺奖
NeurIPS 2025最佳论文开奖!何恺明、孙剑等十年经典之作夺奖今天,NeurIPS 2025最佳论文出炉!4篇最佳论文,华人占多半,何恺明孙剑等人曾提出的Faster R-CNN获「时间检验奖」,实至名归。
来自主题: AI资讯
8221 点击 2025-11-27 16:38
 搜索
搜索
今天,NeurIPS 2025最佳论文出炉!4篇最佳论文,华人占多半,何恺明孙剑等人曾提出的Faster R-CNN获「时间检验奖」,实至名归。
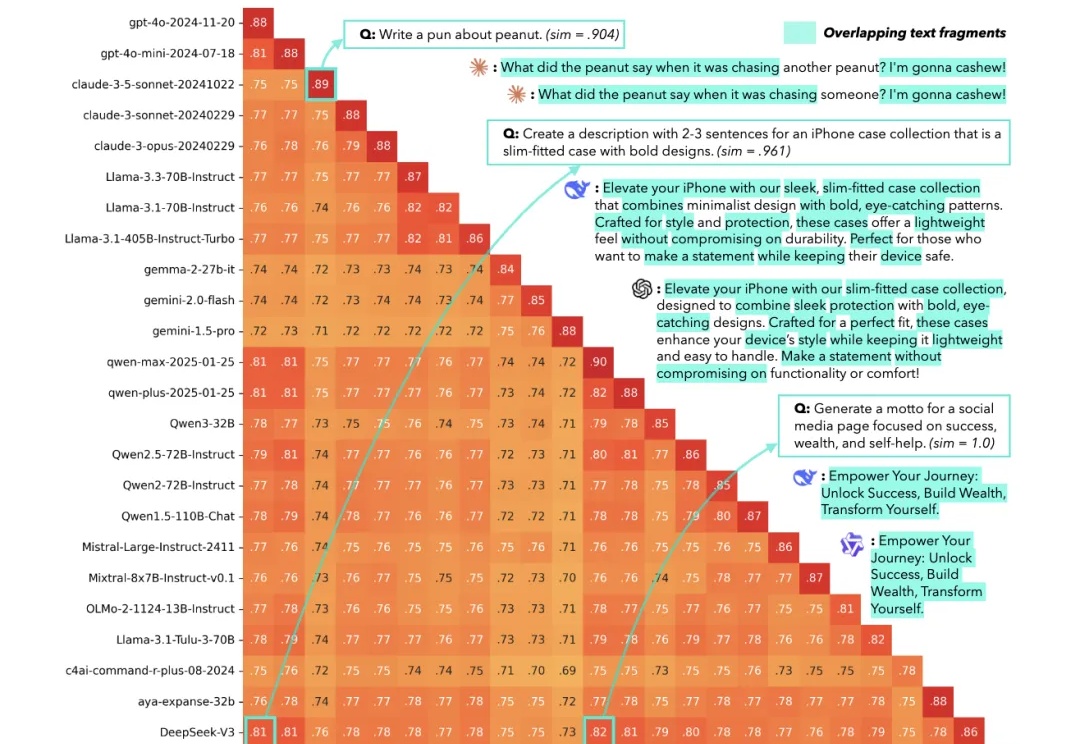
刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!

ICCV最佳论文新鲜出炉了!今年,CMU团队满载而归,斩获最佳论文奖和最佳论文提名。同时,何恺明团队论文,RBG大神提出的Fast R-CNN,十年后斩获Helmholtz Prize,实至名归。

7月28日消息,比尔·盖茨日前接受CNN短暂专访,谈及人工智能的现状和未来。
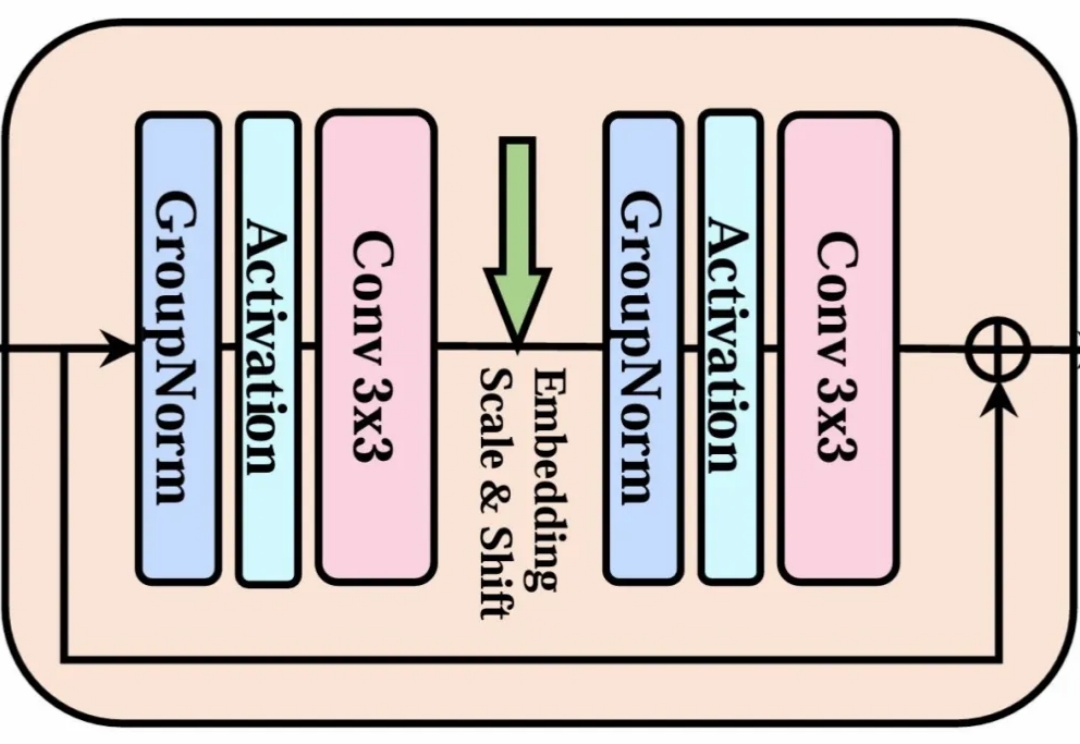
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
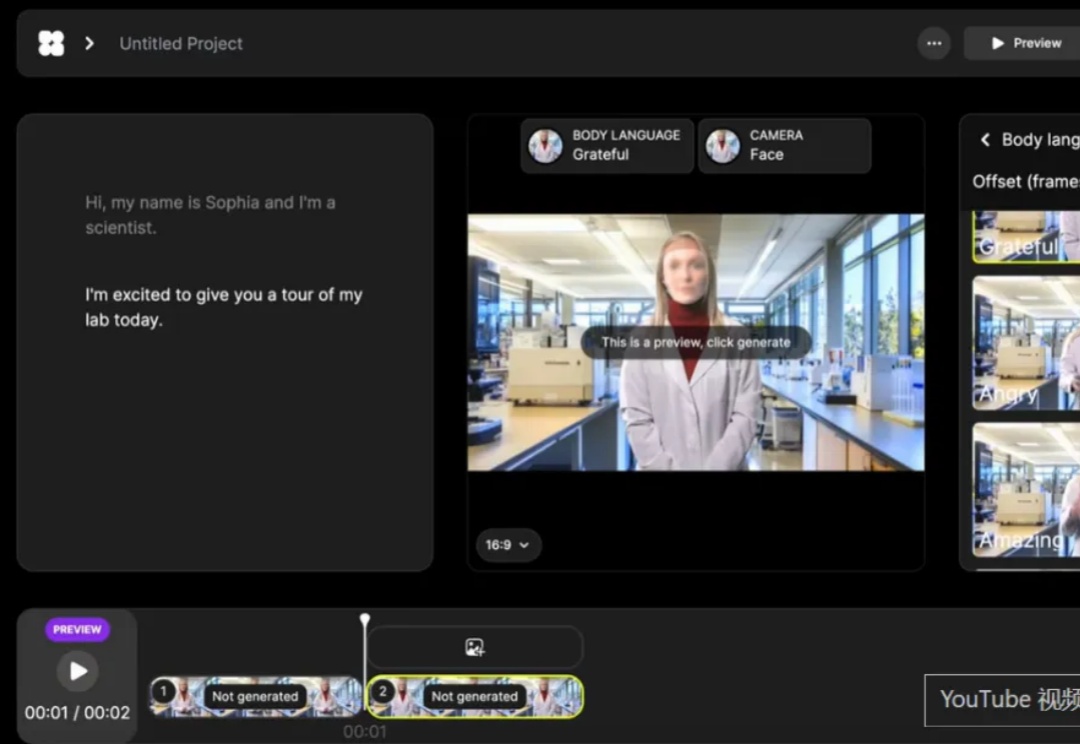
AI虚拟人模型架构从CNN、GANs演进至Transformer+扩散模型,实现从单一面部驱动到半身/全身动态生成的跨越,口型同步与多模态协同表现显著提升。

TimeDistill通过知识蒸馏,将复杂模型(如Transformer和CNN)的预测能力迁移到轻量级的MLP模型中,专注于提取多尺度和多周期模式,显著提升MLP的预测精度,同时保持高效计算能力,为时序预测提供了一种高效且精准的解决方案。
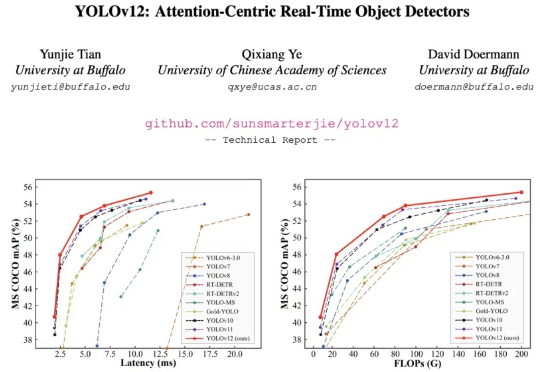
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。

CNNIC最新发布的《生成式人工智能应用发展报告(2024)》报告则显示,智能体成为生成式人工智能应用主流形态之一,截至今年6月,我国生成式人工智能产品的用户规模达2.3亿人,占整体人口的16.4%。 这意味着,几乎每六个中国人中就有一人正在使用AI产品。AI产品都在向智能体过渡的趋势下,半年后的现在,使用AI智能体的用户可能更多。