# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文作者来自复旦大学视觉与学习实验室和人工智能创新与产业研究院。其中第一作者高子怡为复旦大学研二硕士,主要研究方向为 AIGC 和 AI 安全。本文通讯作者是复旦大学的陈静静副教授。
来自复旦大学视觉与学习实验室的研究者们提出了一种新型的面向视频模型的对抗攻击方法 - 基于扩散模型的视频非限制迁移攻击(ReToMe-VA)。该方法采用逐时间步对抗隐变量优化策略,以实现生成对抗样本的空间不可感知性;同时,在生成对抗帧的去噪过程中引入了递归 token 合并策略,通过匹配及合并视频帧之间的自注意力 token,显著提升了对抗视频的迁移性和时序一致性。

引言
背景
近年来,深度神经网络(DNNs)在计算机视觉以及多媒体分析任务上取得了巨大的成功,并广泛的应用于实际生产生活中。然而,对抗样本的出现对 DNNs 的鲁棒性带来了挑战。与此同时,对抗样本的可迁移性使得黑箱攻击成为可能,从而为深度模型在诸如人脸验证和监控视频分析等安全攸关的场景中的部署带来了安全威胁。目前,大多数基于迁移的对抗攻击尝试通过限制扰动的 Lp - 范数来保证 「细微扰动」。
然而,在 Lp - 范数约束下生成的对抗样本仍具有可察觉的扰动噪声,从而使其更容易被检测到。因此,非限制性对抗攻击开始出现。与之前的方法不同,非限制性攻击通过添加非限制性的自然扰动(如纹理、风格、颜色等)实现。相比于传统添加限制性对抗噪声的攻击,上述非限制性攻击优化得到的对抗样本更加自然。
目前,针对非限制性对抗攻击的研究主要针对图像模型,针对视频模型的研究,尤其是视频模型非限制对抗攻击可迁移性的研究仍较少。基于此,本文深入探索了非限制对抗攻击在视频模型上的迁移性,并提出了一种基于扩散模型的非限制视频迁移攻击方法。
问题
基于扩散模型的非限制视频迁移攻击的挑战来自三个方面。首先,对抗视频生成涉及整个去噪过程的梯度计算,导致高内存开销。第二,扩散模型通常在早期去噪步骤中添加粗略语义信息进行引导,然而在生成对抗视频中,过早对隐变量进行扰动会导致生成对抗帧显著失真,且逐帧生成对抗帧后将导致最终对抗视频时序一致性差。最后,由于时间维度的引入,逐帧的单独对抗扰动会引入单调梯度,缺少视频帧之间的信息交互,使得对抗帧的迁移性较弱。
方法
为此,研究团队引入了第一个基于扩散模型的视频非限制性对抗攻击框架 ReToMe-VA,旨在生成具有更高可迁移性的视频对抗样本。
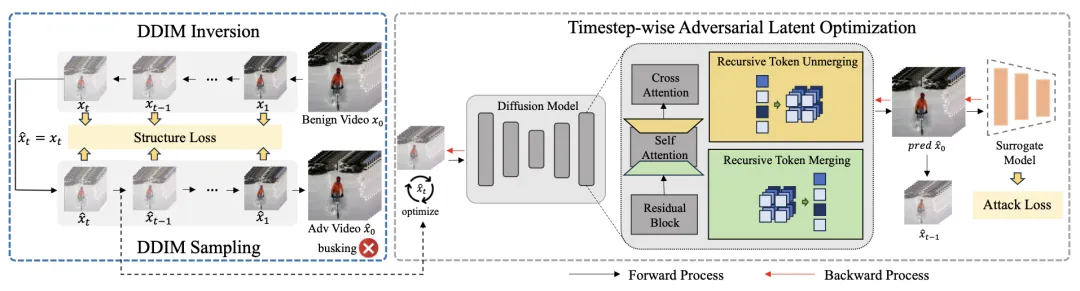
ReToMe-VA 攻击框架如上图所示。ReToMe-VA 通过 DDIM 反转将良性帧映射到隐空间。在 DDIM 采样过程中,采用逐时间步对抗隐变量优化策略来优化潜在变量,即在每个去噪步骤中优化扩散模型隐空间的扰动。这一策略能够使得添加对抗内容在具有强对抗性的同时更加自然。
此外,ReToMe-VA 引入了递归 token 合并机制来对齐和压缩跨帧的时间冗余 token。通过在自注意力模块中使用共享 token,ReToMe 优化了逐帧优化中细节的不对齐信息,从而生成时间上一致的对抗性视频。同时,跨视频帧合并 token 促进了帧间交互,使当前帧的梯度融合来自关联帧的信息,生成稳健且多样化的梯度更新方向,从而提高对抗迁移性。
时间步对抗隐变量优化策略
通过 DDIM 反转后,在每个去噪时间步 t,我们预测每一帧的最终输出 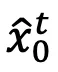 以替代对抗输出
以替代对抗输出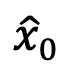 进行替代模型的预测。对抗隐变量
进行替代模型的预测。对抗隐变量 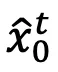 的计算和对抗目标函数表达如下:
的计算和对抗目标函数表达如下:
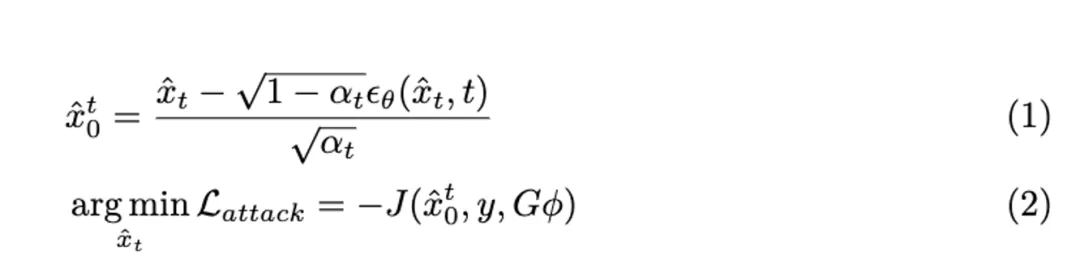
优化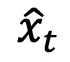 后,从
后,从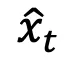 生成样本
生成样本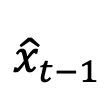 以准备下一时间步的对抗优化:
以准备下一时间步的对抗优化:
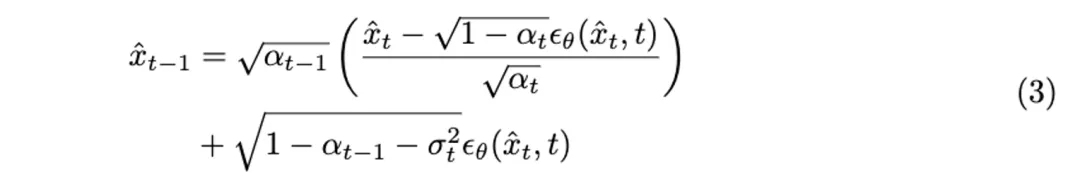
最后,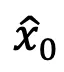 被用作最终的对抗视频片段以欺骗目标视频识别模型。
被用作最终的对抗视频片段以欺骗目标视频识别模型。
对抗内容的添加不可避免地带来了良性帧失真的挑战,被保持对抗帧与良性帧的结构相似性,TALO 在每个时间步最小化良性隐变量 x 和对抗隐变量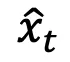 之间自注意力图的平均差异:
之间自注意力图的平均差异:
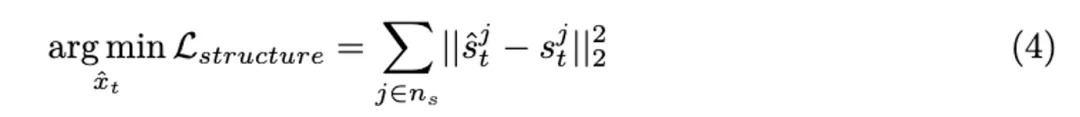
ReToMe-VA 的最终目标函数如下:
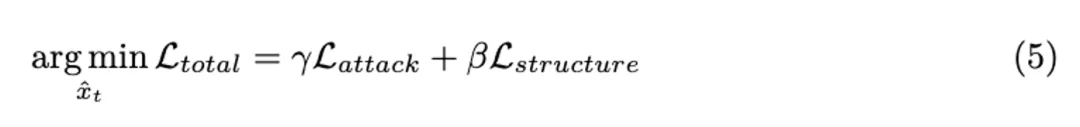
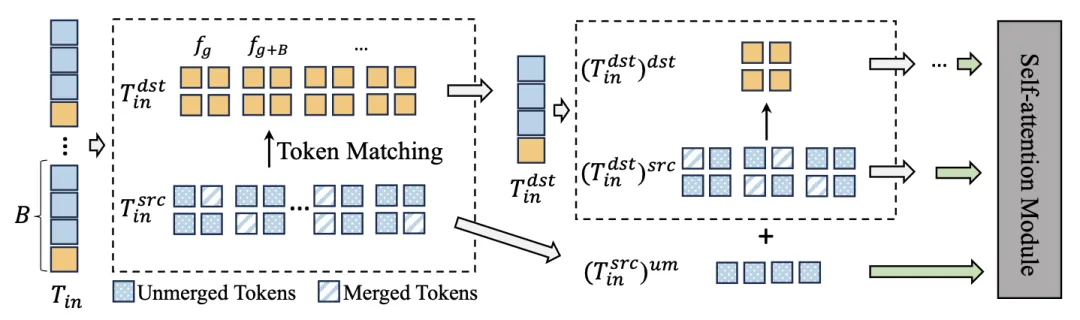
递归 token 合并
研究团队引入了递归 token 合并(ReToMe)策略,该策略递归匹配和合并跨帧的相似 token,使自注意力模块能够提取一致的特征。通常,tokenT 被划分为源 (src) 和目标 (dst) 集。然后,源集中的 token 与 dst 中最相似的 token 匹配,并随后选择 r 个最相似的边。接下来,我们通过将源集中连接的 r 个最相似的 token 替换为匹配的目标集 token 来合并 token。为了保持 token 数量不变,合并的 token 以赋值的方式被拆分。token 匹配、合并和拆分操作表示为:
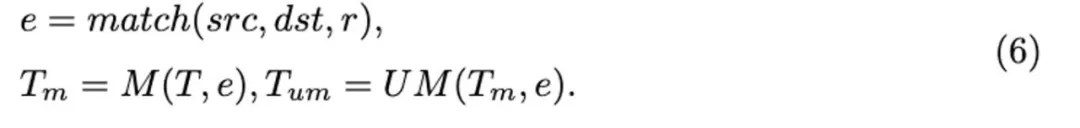
在自注意力模块将 token 按帧划分为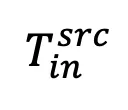 和
和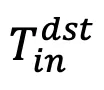 两个集合。然后使用上述合并操作合并 token:
两个集合。然后使用上述合并操作合并 token:
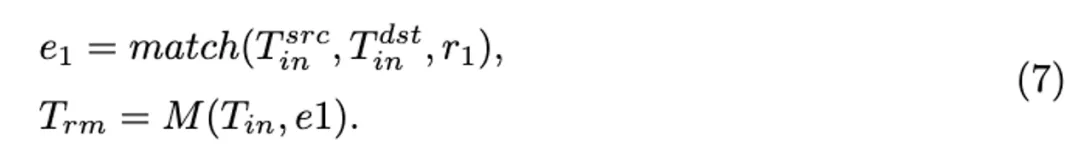
然而,在上述合并过程中,目标集中的 token 不会被合并和压缩。为了最大限度地融合帧间信息,我们递归地将上述合并过程应用于目标集中的 token,直到仅包含一帧。接下来,我们将 token 输入自注意力模块以计算输出 token。输出 token 需要以逆向顺序恢复到原始形状以执行后续操作。递归合并策略过程如图所示:
实验
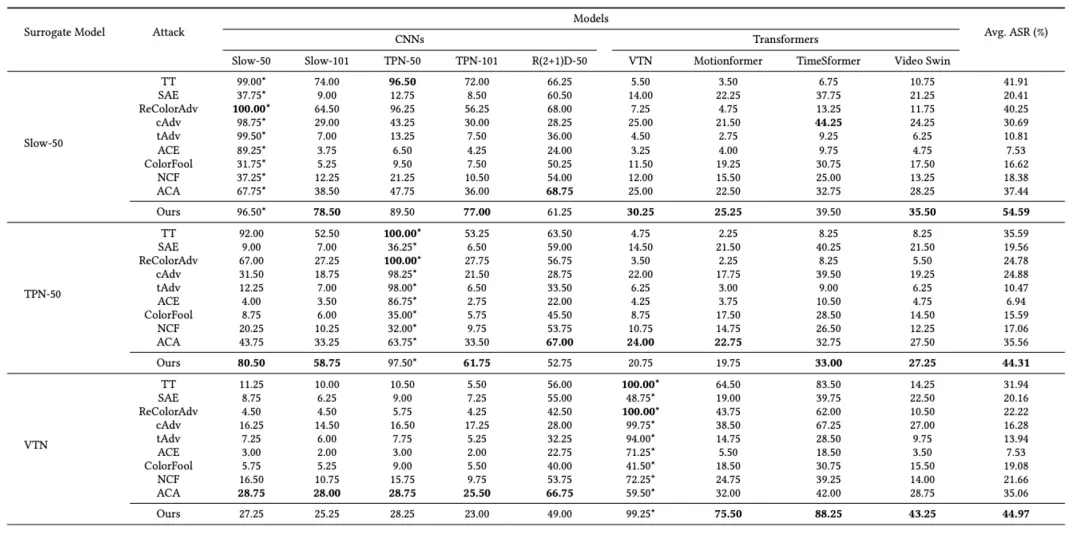
研究团队选择 Kinetics-400 数据集,I3D SLOW, TPN, R (2+1) D, VTN,Motionformer, TimeSformer 和 VideoSwin 等 CNN 和 ViT 架构的模型评估了 ReToMe-VA 的对抗性迁移性。当使用某一种结构的视频模型作为替代模型时,计算所生成对抗样本在其他结构的视频模型上的攻击成功率(Attack success rate,ASR),以此作为评价指标。
对抗迁移性实验
研究团队首先评估了正常训练的 CNNs 和 ViTs 的对抗可迁移性。对于视频限制性攻击,将提出的方法与 SOTA 的 TT 进行比较。对于视频非限制性攻击,由于缺乏可比的工作,研究团队将图像非限制性攻击扩展为逐帧生成对抗性视频片段,包括 SAE、ReColorAdv、cAdv、tAdv、ACE、ColorFool、NCF 和 ACA。
对抗性视频片段分别针对 Slow-50、TPN-50、VTN、Motionformer 和 TimeSformer 生成。结果显示,ReToMe-VA 在 Motionformer 和 TimeSformer 模型上实现了 100% 的白盒攻击成功率,且在黑盒环境中超过了限制性攻击方法 TT。当使用 Slow-50、Motionformer 和 TimeSformer 作为替代模型时,ReToMe-VA 显著超过了 SOTA 的 ACA,分别高出 17.10%、26.62% 和 10.19%。部分结果展示如下:
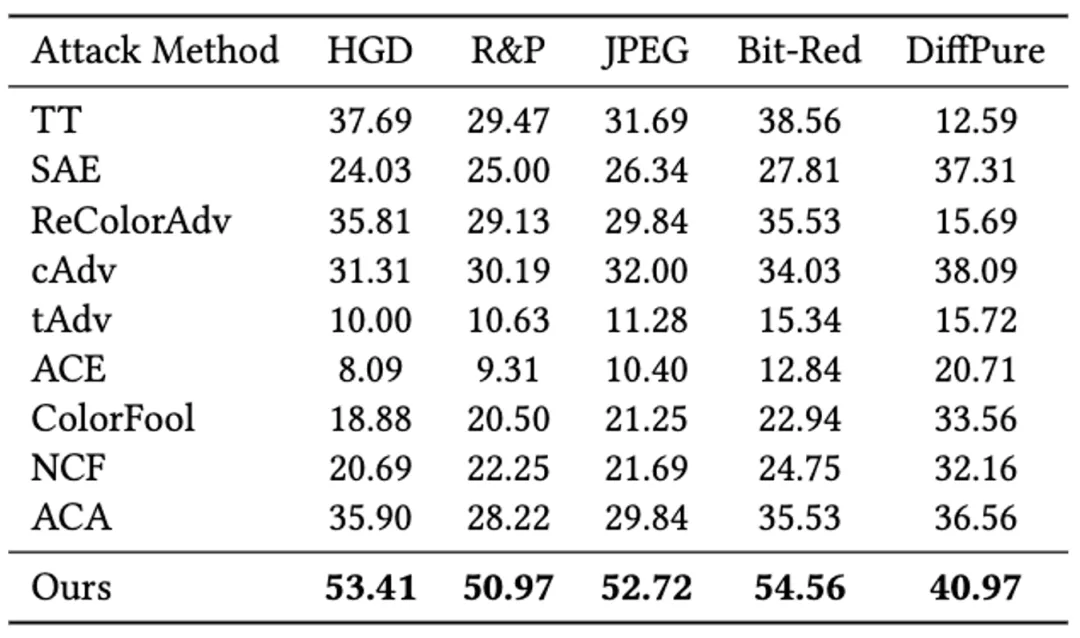
对抗防御鲁棒性实验
研究团队在 HGD,R&P,JPEG,Bit-Red 和 DiffPure 等五种防御方法上评估了 ReToMe-VA 的对抗防御鲁棒性。通过实验,ReToMe-VA 在不同防御方法中仍保持较高的攻击成功率。比如 HGD 和 DiffPure 防御方法下,ReToMe-VA 分别比 ACA 高出 17.5% 和 4.41%,这表明其在穿透这些防御时的鲁棒性和效率。
可视化

研究团队通过对视频帧质量和时间一致性的定性和定量比较来展示 ReToMe-VA 方法的优越性。
视频帧质量
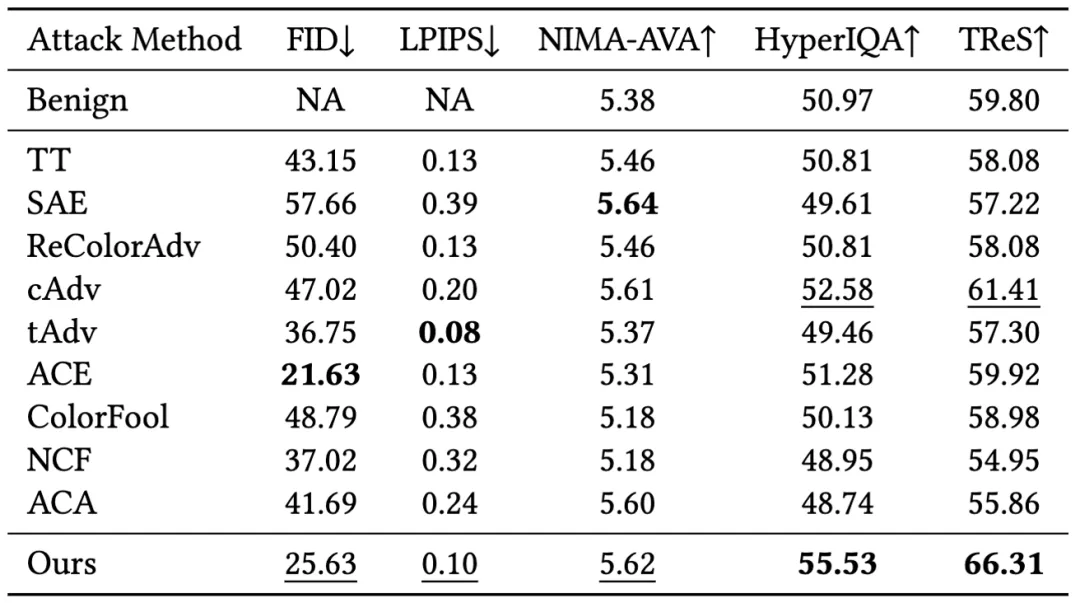
研究团队通过参考和非参考感知图像质量评估指标对帧的质量进行了量化评估。如表所示,ReToMe-VA 在所有指标中都达到了前两名。而 ReToMe-VA 在 HyperIQA 和 TReS 中取得了最佳结果。
时序一致性
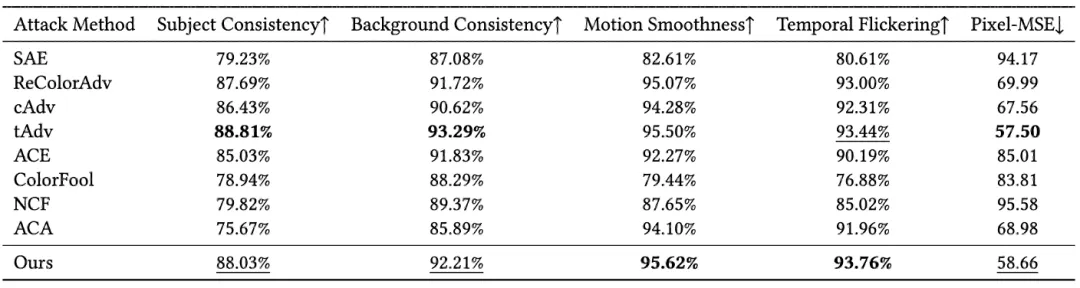
研究团队使用五个指标评估视频的时序一致性,所有指标都达到了前两名。具体来说,运动平滑度和时间闪烁性取得了最佳结果。
文章来源于“机器之心”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
