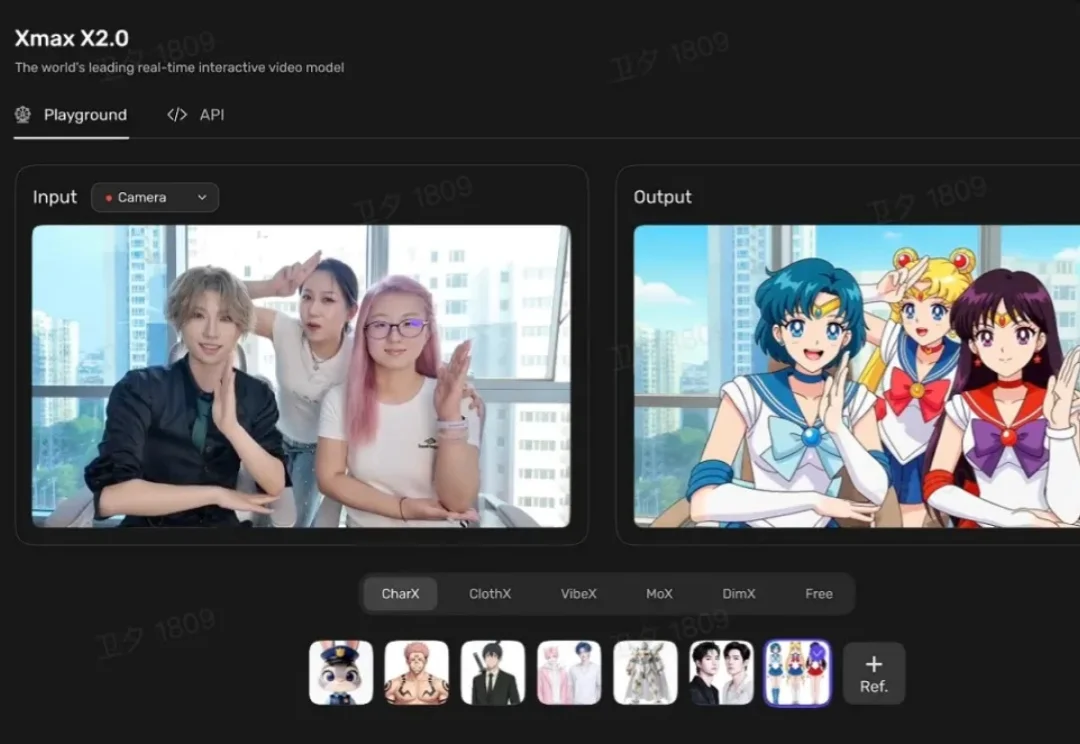
为什么说以Xmax X2.0为代表的实时交互视频模型值得重视?
为什么说以Xmax X2.0为代表的实时交互视频模型值得重视?我们先来看两个画面。
来自主题: AI技术研报
8308 点击 2026-07-16 10:30
 搜索
搜索
我们先来看两个画面。
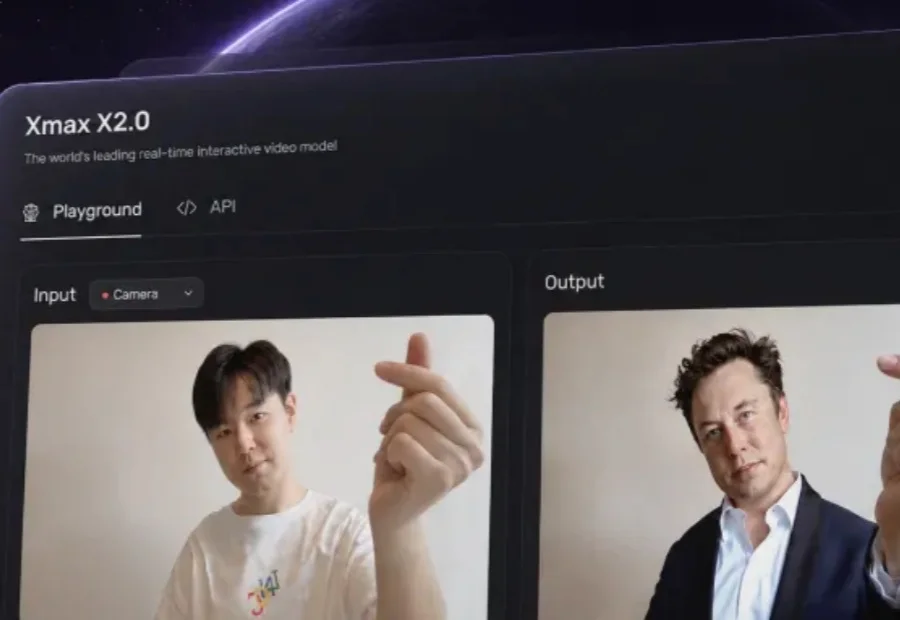
对着摄像头比了个手势,桌上凭空多了只企鹅

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。

PJ Ace 在推文中兴奋地表示,他们借助 Utopai Studios 推出的下一代 AI 视频模型和智能体 PAI2.0, 以好莱坞灾难片大师罗兰·艾默里奇(Roland Emmerich)的视听风格,硬核「复活」了一段 250 年前激情澎湃、颠覆想象的美国独立日「真实历史影像」。

全球顶流AIGC大神、AI原生PJ Ace,近期在社交媒体上发布了最新力作,引发海外科技与电影圈的强烈关注。PJ Ace在推文中兴奋地说,他们借助Utopai Studios推出的下一代AI视频模型和智能体PAI2.0,以好莱坞灾难片大师罗兰·艾默里奇(Roland Emmerich)的视听风格,硬核“复活”了一段250年前激情澎湃、颠覆想象的美国独立日“真实历史影像”。

Meta超级智能实验室(MSL)扔出了首个图像生成模型Muse Image,代号「芒果」(Mango)。这是我们迄今为止最先进的图像生成模型。与Muse Image一同亮相的,还有视频模型Muse Video,目前仍是预览版。

今天来好好盘点 2026 年上半年的图片与视频模型,伴随模型更新时间轴出现的,还有我一些当时的测试文章。也算是对不怎么努力也没什么收获的上半年做个总结汇报了。

Vidu S1 面向的是一类全新的使用场景:让视频模型从离线成片,走向可对话、可响应、可持续在线的实时交互。它的核心能力包括语音实时控制视频生成内容、无限长实时生成、540P (960×540) + 25FPS (最高可支持 42FPS) 实时交互,以及自定义初始图像与音色。难得的是,这套实时交互能力在消费级显卡上就能跑起来。

据 Z Finance 获悉,由清华博士、华为「天才少年」张家声领衔的 AI 初创公司 Philo AI 已完成近千万级美金首轮融资,由祥峰投资(Vertex Ventures)独家投资。张家声此前主导的视频模型曾登上 Artificial Analysis 全球第 2,而这支核心成员全员清北博士的团队一向低调。本轮资金将重点用于世界生命模型的核心研发、自有系统构建与核心团队扩张。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。